Classification models are key machine learning techniques that categorize input data into predefined classes, providing businesses with actionable insights and automation capabilities to improve decision-making and operational efficiency.
These models range from simple decision trees to complex ensemble methods, offering varying levels of interpretability and predictive performance.
Decision Trees: Interpretable Models for Business Decisions
Decision trees use a tree-like structure where each node represents a decision based on a specific feature, and each branch represents an outcome leading to a final classification.
Advantages: Easy to interpret and visualize; useful for scenarios requiring transparent decision logic.
Business Use: Common in credit scoring, customer segmentation, and risk assessment, helping stakeholders understand decision paths.
Functionality: By following branches from root to leaf, users can trace how a classification was made.
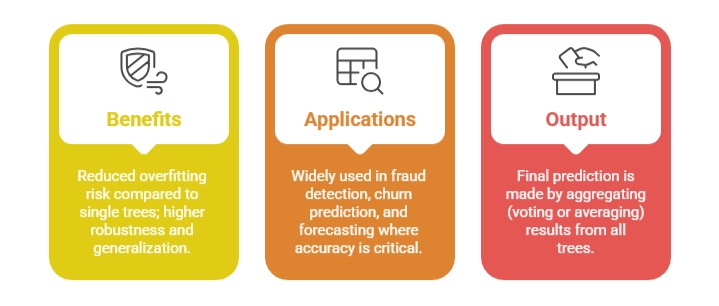
Random Forests: Ensemble Methods for Improved Predictions
Random forests combine multiple decision trees, each trained on random subsets of data and features, to enhance prediction accuracy.
Naive Bayes: Probabilistic Classification for Business Problems
Naive Bayes applies Bayes’ theorem assuming independence between features, classifying data based on calculated posterior probabilities.
Strengths: Fast, scalable, effective with high-dimensional data.
Use Cases: Email spam filtering, sentiment analysis, and recommendation systems.
Probabilistic Nature: Provides likelihood estimates useful in risk and uncertainty assessments.
Model Interpretability: Understanding How Models Make Decisions
Model interpretability is crucial for understanding and trusting how models make decisions, particularly in regulated industries such as finance and healthcare.
While decision trees are inherently interpretable, more complex models like random forests require tools such as feature importance scores or SHAP values to explain predictions.
Transparent models aid in debugging, identifying biases, and effectively communicating insights to non-technical stakeholders.

Class Sessions
Sales Campaign

We have a sales campaign on our promoted courses and products. You can purchase 1 products at a discounted price up to 15% discount.