Data preparation and cleaning are critical steps in the data analytics process, ensuring that data is accurate, complete, and consistent for reliable analysis.
This stage involves identifying and addressing data quality issues, standardizing data formats, filling in missing information, detecting outliers, and validating the overall dataset quality.
Clean and well-prepared data forms the foundation for meaningful, actionable insights.
Identifying Data Quality Issues: Missing Values, Duplicates, and Inconsistencies
A common challenge in raw datasets is missing values, which can skew analysis or cause errors in algorithms. Identifying these gaps early is essential.
Duplicate records arise when data from different sources overlap or repetitive entries occur, leading to inflated results or misleading patterns. Inconsistencies, such as varying date formats or mismatched categories, reduce the data's uniformity and comparability.
Data Import Techniques and Format Standardization
During data import, diverse sources often bring heterogeneous formats. Standardizing formats—such as date representations, numerical units, and categorical labels—is crucial.
Techniques include applying data transformation rules, using predefined schemas, and leveraging tools that automate format harmonization. Consistent data formatting facilitates seamless integration across systems and easier interpretation.
Imputation Strategies for Handling Incomplete Data
Missing data can be addressed through several imputation methods:
1. Mean/median imputation for numerical fields
2. Mode substitution for categorical attributes
3. Predictive modeling, using patterns from existing data to estimate missing values
4. Deletion, removing records or columns with excessive missingness when appropriate
Choosing the right imputation depends on the data context, quantity of missing values, and analysis goals.
Outlier Detection and Treatment Methods
Outliers—data points significantly different from others—can distort statistical measures and models. Detection methods include statistical tests, visualization (boxplots), and clustering techniques. Treatment options:
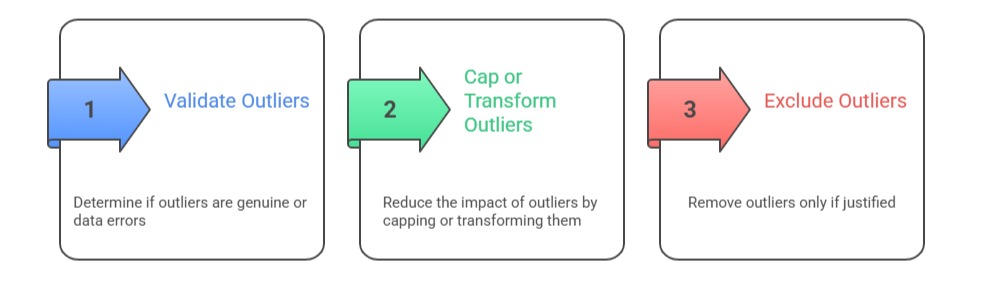
Careful handling preserves data integrity and analysis validity.
Data Validation and Quality Assurance Processes
Validation ensures prepared data meets accuracy and consistency standards. Processes involve:
1. Cross-checking with source data or business rules
2. Automated quality checks, such as range constraints and referential integrity
3. Peer reviews and audit trails documenting data transformations
4. Continuous monitoring and re-validation in dynamic datasets
These steps build confidence in data reliability for decision-making.
