Machine learning (ML) is a subfield of artificial intelligence (AI) that enables computers to learn patterns from data and make predictions or decisions without explicit programming.
While rooted in statistics, ML emphasizes computational methods to handle vast, complex datasets, adapting and improving models automatically.
Definition and Distinction from Traditional Statistical Methods
Machine Learning focuses on building models that generalize from data to make accurate predictions or classifications on new, unseen information. It adapts based on data inputs and feedback.
Traditional Statistics primarily concerned with inference about populations from samples, identifying relationships, and testing hypotheses, often assuming pre-defined models.
ML can handle high-dimensional, unstructured data and complex, nonlinear patterns that classical statistics may struggle with, blending statistical rigor with computational power.
Machine Learning Workflow
A robust ML workflow ensures that models are well-designed, trained, and validated. The key stages below emphasize structured data handling, algorithm selection, and iterative optimization.
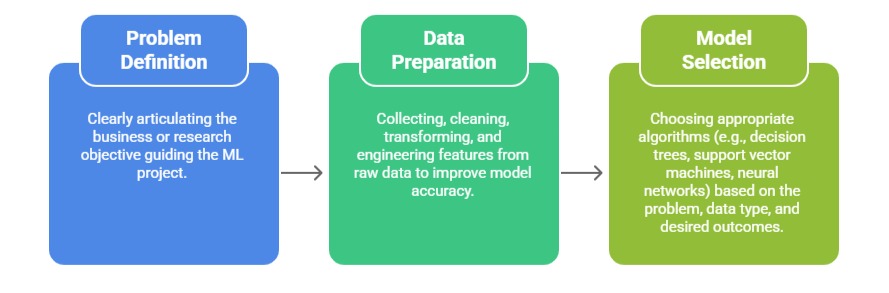
Iterative cycles of training, validation, and tuning optimize model performance before deployment.
A disciplined workflow ensures reproducibility and robust results.
Supervised Learning: Classification and Regression Applications
Supervised learning uses labeled data to train predictive models. The points below highlight classification and regression applications, illustrating how these techniques address targeted prediction problems.
1. Classification: Predicting categorical outcomes, such as fraud detection (fraud/no fraud), sentiment analysis (positive/negative), or churn prediction (yes/no).
2. Regression: Predicting continuous variables like sales amounts, temperature, or demand forecasts.
3. Algorithms include logistic regression, random forests, support vector machines, and deep learning models.
Supervised learning is widely used for specific prediction tasks with clear target variables.
Unsupervised Learning: Clustering and Pattern Discovery
Unsupervised Learning analyzes data without labeled responses to find hidden structures or groupings. The points below highlight clustering and dimensionality reduction as essential methods for pattern discovery and data exploration.
1. Clustering: Grouping similar data points, useful in customer segmentation, image categorization, and anomaly detection.
2. Dimensionality Reduction: Techniques like PCA simplify datasets by reducing feature numbers while preserving variability.
It helps in exploratory data analysis and feature learning. Unsupervised learning uncovers insights where target outcomes are unknown or exploratory analysis is needed.
