Predictive modeling is a core technique in data science that utilizes historical and current data to forecast future outcomes.
It plays a vital role in helping businesses anticipate market trends, customer behaviors, and operational risks, thereby enabling smarter, data-driven decision-making.
This process utilizes various learning approaches, follows a systematic model-building lifecycle, involves careful feature engineering, and requires robust evaluation metrics to ensure model reliability and effectiveness.
Supervised vs. Unsupervised Learning Approaches
Supervised Learning: Models are trained on labeled datasets where the target outcome is known. The goal is to predict outcomes such as customer churn, sales volumes, or fraud detection. Common algorithms include regression, classification (e.g., logistic regression, decision trees), and neural networks.
Unsupervised Learning: Models identify patterns or structures in unlabeled data, such as customer segmentation or anomaly detection. Techniques include clustering (e.g., k-means) and dimensionality reduction.
Supervised learning is prevalent for explicit prediction tasks, while unsupervised methods support exploratory data analysis.
Model Building Lifecycle
Building an effective predictive model involves multiple stages, each crucial for performance and accuracy. The points below summarize the lifecycle from training to validation to testing.
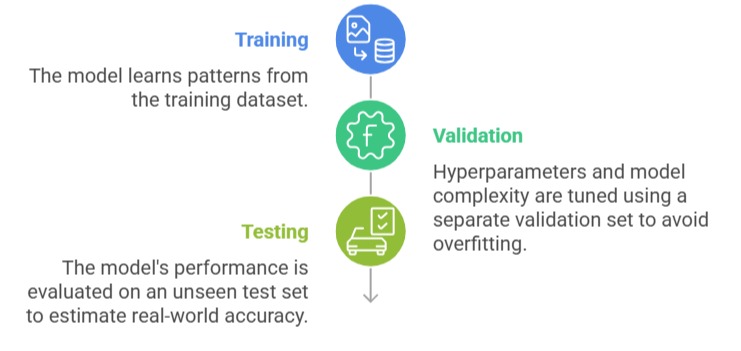
Proper model lifecycle management ensures that predictive results generalize well beyond the sample data.
Feature Engineering: Selecting Relevant Variables for Predictions
Feature engineering, a critical step in predictive modeling, involves creating, selecting, and transforming variables to enhance model performance.
This process includes handling missing data, encoding categorical variables, generating interaction terms, and scaling quantitative inputs.
Domain knowledge plays a key role in identifying features that are closely related to the prediction target. Effective feature engineering reduces noise, improves model interpretability, and increases predictive accuracy.
Model Evaluation Metrics
Model evaluation metrics guide decision-making and model selection. The key metrics below focus on correctness, detection capability, and balance between different types of prediction errors.
1. Accuracy: Proportion of correct predictions over total predictions; useful when classes are balanced.
2. Precision: Proportion of true positives among all positive predictions; critical when false positives are costly.
3. Recall (Sensitivity): Proportion of true positives detected among actual positives; important when missing positives is costly.
4. F1-Score: Harmonic mean of precision and recall; balances trade-offs, particularly in imbalanced datasets.
Choosing appropriate metrics depends on the business context and the cost of different types of errors.

Class Sessions
Sales Campaign

We have a sales campaign on our promoted courses and products. You can purchase 1 products at a discounted price up to 15% discount.