Once a dataset has been cleaned and prepared, the next important question is: "Which variables should actually be used in the analysis or model?"
Not every column in a dataset is useful. Some features carry rich, meaningful information. Others are redundant, irrelevant, or even harmful to your analysis — adding noise, increasing complexity, and reducing the accuracy of any model built on top of them.
Feature selection is the process of identifying and retaining only the most relevant variables while discarding those that do not contribute meaningfully to understanding or predicting the target outcome.
It is a critical step that sits between data cleaning and modeling, and doing it well leads to simpler, faster, and more accurate analytical results.
Why Feature Selection Matters
Using every available column in a dataset might seem like the safest approach, more information should mean better results, right? In practice, the opposite is often true. Including irrelevant or redundant features creates a range of problems that directly undermine analysis quality.
1. Overfitting: Models trained on too many irrelevant features memorize noise rather than learning genuine patterns, performing well on training data but poorly on new data.
2. Increased Complexity: More features mean slower computation, harder interpretation, and more difficult maintenance.
3. Multicollinearity: Highly correlated features provide duplicate information and destabilize model coefficients.
4. Reduced Interpretability: A model built on 5 well-chosen features is far easier to explain to stakeholders than one built on 50 features.
The goal of feature selection is not to throw away data carelessly, it is to keep what genuinely matters and remove what does not.
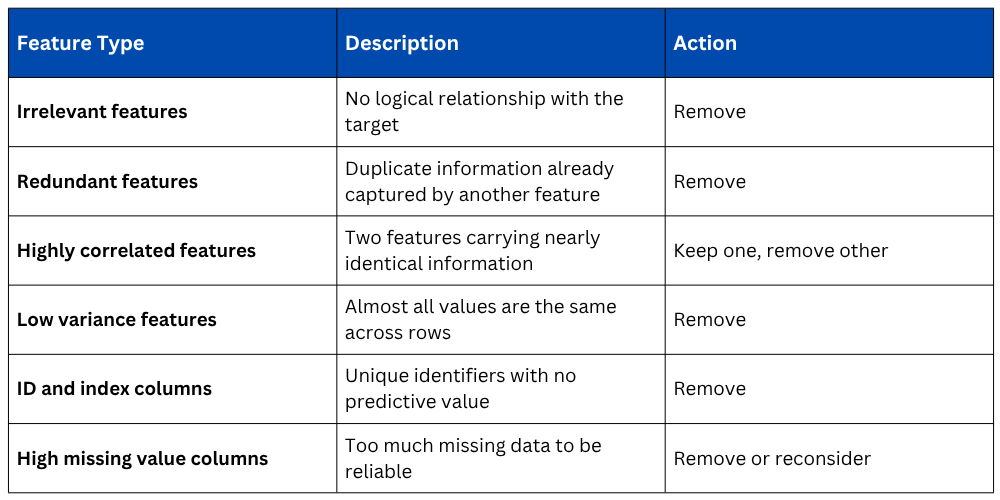
Types of Features to Look For and Remove
Before applying formal selection techniques, a practical understanding of what kinds of features typically need to be removed helps build analytical judgment.
Method 1 — Removing Low Variance Features
A feature where nearly all values are identical across the dataset contributes almost no useful information. For example, a column where 99% of values are "Yes" tells you almost nothing that differentiates one record from another.

This shows how many unique values exist in each column. Columns with only 1 or 2 unique values across thousands of rows are strong candidates for removal.

Method 2 — Correlation-Based Selection
Highly correlated features carry redundant information. When two features have a correlation above 0.85 or 0.90, keeping both adds no new information but increases complexity. The standard approach is to identify the pair and remove one of them.
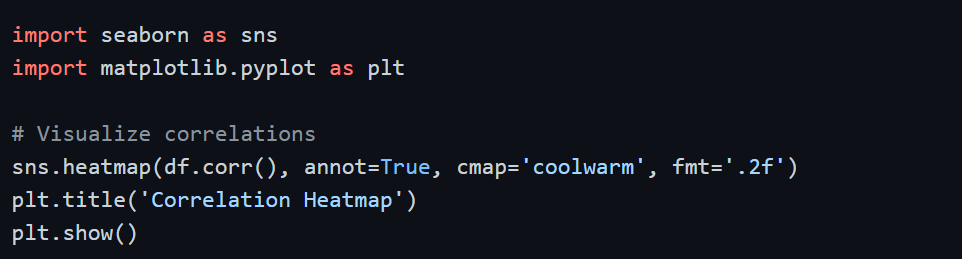
Programmatically identifying and removing highly correlated features:
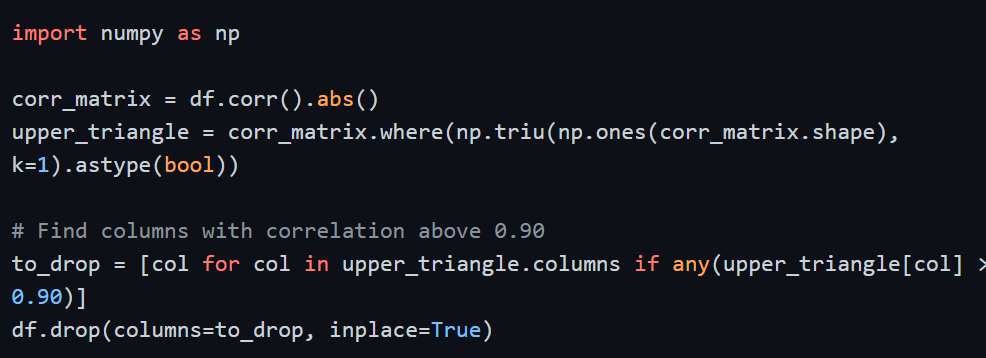
This systematically identifies and removes one feature from each highly correlated pair, retaining the information while eliminating redundancy.
Method 3 — Univariate Selection Using Statistical Tests
Statistical tests measure the relationship between each individual feature and the target variable. Features with a strong statistical relationship with the target are selected — those with a weak relationship are discarded.
Scikit-learn's SelectKBest applies a chosen statistical test to each feature and selects the top K features with the strongest relationship to the target.
from sklearn.feature_selection import SelectKBest, f_classif
import pandas as pd
X = df.drop(columns=['target'])
y = df['target']
selector = SelectKBest(score_func=f_classif, k=5)
selector.fit(X, y)
# View feature scores
feature_scores = pd.DataFrame({'Feature': X.columns, 'Score': selector.scores_})
print(feature_scores.sort_values('Score', ascending=False))
# Get selected feature names
selected_features = X.columns[selector.get_support()]
print(selected_features)
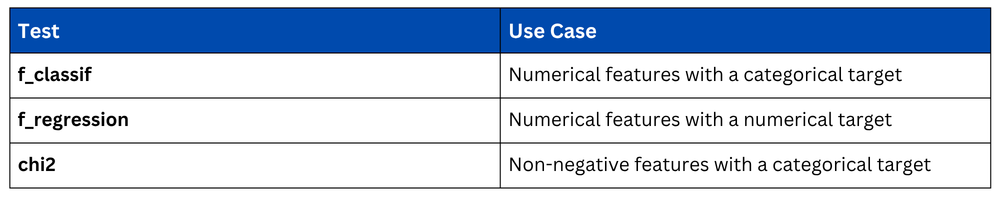
Choosing the Right Statistical Test
Method 4 — Feature Importance from Tree-Based Models
Tree-based models like Random Forest naturally rank features by how much each one contributes to splitting decisions, providing a direct, data-driven measure of feature importance. This is one of the most reliable feature selection methods in practice.
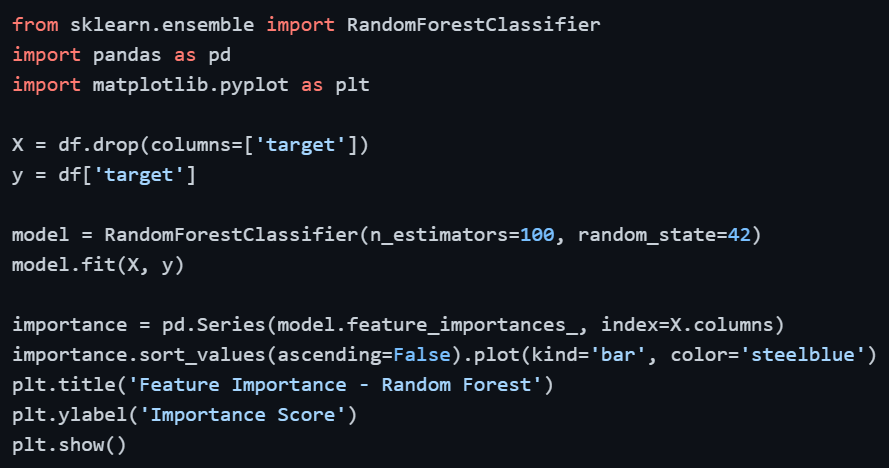
Features with very low importance scores contribute little to the model and are candidates for removal. A common approach is to retain the top features that collectively account for 90–95% of total importance.
Method 5 — Dropping Irrelevant Columns Manually
Domain knowledge and common sense are just as powerful as statistical techniques. Columns like customer IDs, row numbers, timestamps with no analytical value, or fields that clearly have no relationship to the problem at hand should simply be dropped directly.

This is always the first pass of feature selection — before any statistical method is applied, remove what is obviously irrelevant based on understanding the data and the problem.

Class Sessions
Sales Campaign

We have a sales campaign on our promoted courses and products. You can purchase 1 products at a discounted price up to 15% discount.