Data privacy risks in AI pipelines are an increasingly significant concern in the era of big data and advanced machine learning models. AI pipelines involve multiple stages—from data collection and preprocessing to model training, deployment, and ongoing learning—which all present potential vulnerabilities for exposing sensitive information.
These risks are heightened by the vast and often unregulated data sources involved, including personal, financial, health, and proprietary business data. Protecting data privacy throughout the AI lifecycle is crucial not only for compliance with regulations like GDPR and HIPAA but also for maintaining user trust, safeguarding intellectual property, and preventing malicious exploitation.
Data Collection and Ingestion Risks
The initial stage of an AI pipeline involves gathering data from various sources, which presents several privacy challenges:
1. Unsecured Data Transfer: Insecure transmission channels enable interception or eavesdropping by malicious actors.
2. Data Leakage from External Sources: Public or third-party datasets may contain personally identifiable information (PII) or confidential data without proper consent or anonymization.
3. Inadequate Data Filtering: Collecting unnecessary sensitive data increases exposure risk, especially if improperly handled later in the pipeline.
Mitigation strategies include secure data transfer protocols (e.g., TLS), data anonymization, strict access controls, and rigorous data vetting processes.
Data Storage and Access Control
Storing large volumes of data securely is essential, yet common vulnerabilities persist:
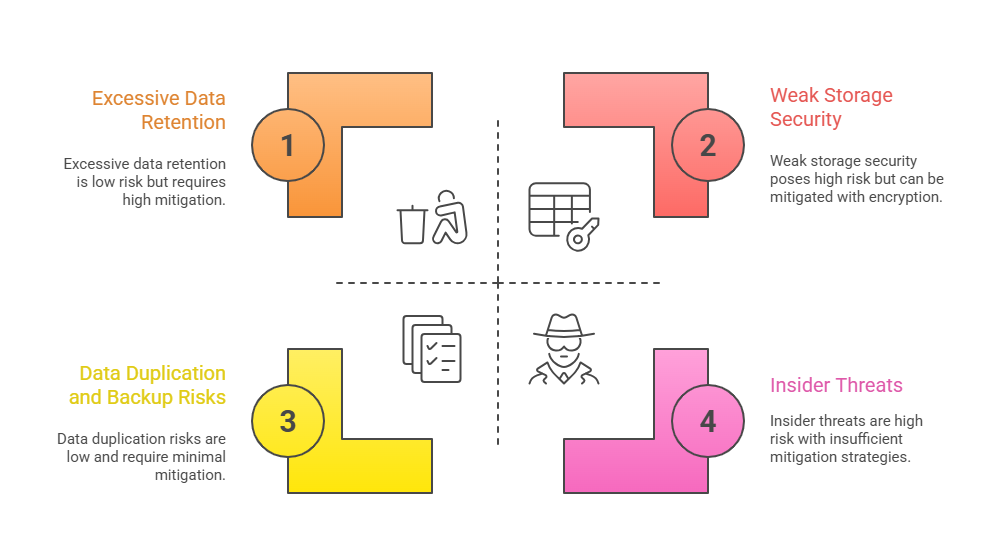
Effective measures include encryption at rest, granular access permissions, timely data purging, and continuous audit logging.
Model Training and Inferencing Risks
During training and deployment, AI models pose specific privacy threats:
1. Model Inversion Attacks: Attackers infer sensitive training data, such as private health records or financial details, by querying models and analyzing outputs.
2. Membership Inference: Determining whether specific data points were part of the training set, thereby exposing user participation or sensitive attributes.
3. Data Leakage through Model Outputs: Sharing overly detailed results, such as confidence scores or detailed logs, can disclose proprietary or sensitive information.
Protection techniques include differential privacy, federated learning, model watermarking, and limiting output granularity.
Deployment and Continuous Learning Risks
As models evolve and update over time, additional privacy risks emerge:
1. Data Drift and Leakage: Changes in input data over time can inadvertently leak sensitive information or cause model biases.
2. Model Re-identification: Repeated querying can enable adversaries to reconstruct or re-identify individuals within datasets.
3. Insecure APIs and Interfaces: Improperly secured APIs may leak sensitive information during interaction.
Mitigations involve access controls, monitoring usage patterns, deploying privacy-preserving algorithms (like federated learning), and secure API design.
Regulatory Compliance and Ethical Considerations
AI pipelines are subject to various legal and ethical standards: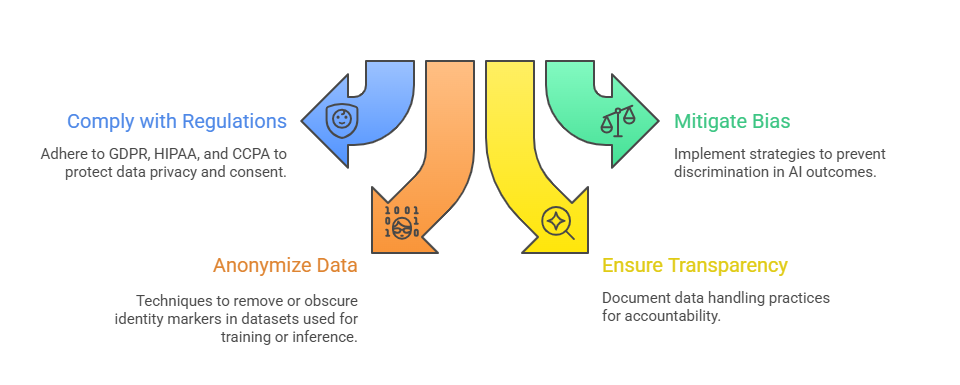
Practical Strategies for Privacy Preservation
Ensuring privacy in modern systems demands both technical and procedural controls. Below are key strategies to minimize risk and exposure.
1. End-to-End Encryption: Secure data during transmission and storage.
2. Data Minimization: Collect only necessary data; avoid over-collection.
3. Differential Privacy: Add noise to data or outputs to prevent re-identification.
4. Federated Learning: Train models locally without centralized data collection.
5. Access Controls & Auditing: Enforce strict roles, monitor access, and review logs regularly.
6. Regular Privacy Impact Assessments: Review data handling practices periodically to ensure compliance.
