Adversarial examples represent one of the most intriguing and challenging aspects of modern machine learning and artificial intelligence systems. They are carefully crafted inputs designed to deceive models into making incorrect predictions or classifications without any obvious indication of manipulation.
The subtlety of adversarial examples makes them a significant security concern because, to human observers, these inputs appear normal or benign—yet, they can cause AI systems to malfunction or produce biased, misleading, or harmful outputs.
The study of adversarial examples is critical to understanding the vulnerabilities of AI models, developing robust defenses, and ensuring the safe application of AI across sensitive domains such as autonomous vehicles, healthcare, finance, and security.
What are Adversarial Examples?
Adversarial examples are inputs to machine learning models that have been intentionally manipulated in subtle ways to cause misclassification or erroneous results. The key characteristics include:
1. Imperceptible Perturbations: These modifications are often minor—so slight that they are indistinguishable from normal data to humans—yet they can drastically alter the model’s output.
2. Targeted vs. Non-Targeted Attacks: Targeted attacks aim to cause the model to classify the input as a specific, incorrect category. Non-targeted attacks merely aim to cause any incorrect classification.
3. Transferability: Many adversarial examples designed for one model can also deceive other models, making attacks more scalable and versatile.
Why are Adversarial Examples Important?
Adversarial examples expose vulnerabilities in machine learning systems, which are increasingly embedded in critical applications. The implications include:
.png)
Methods of Generating Adversarial Examples
Researchers and attackers have developed various techniques for creating adversarial examples, including:
1. Gradient-Based Methods
Fast Gradient Sign Method (FGSM): Adds small perturbations aligned with the gradient of the loss function to deceive the model rapidly.
Projected Gradient Descent (PGD): An iterative version of FGSM that fine-tunes the adversarial perturbation for more potency.
2. Optimization-Based Attacks
Carlini & Wagner (C&W) Attack: Uses optimization algorithms to find minimal perturbations that cause misclassification with high success rates.
3. Transfer Attacks: Craft adversarial examples on a substitute model, which then transfer their deception to other models in a black-box attack.
4. Generative Adversarial Networks (GANs): Utilize generative models to produce realistic and targeted adversarial samples.
Real-World Examples and Implications
Small perturbations in data can significantly impact AI performance, highlighting vulnerabilities in deployed systems. Here’s a list of real-world cases illustrating the implications of adversarial manipulations.
1. Image Recognition: Slightly altered images cause facial recognition systems to misidentify persons or classify images incorrectly. For example, a slightly modified stop sign might be misread as a yield sign by autonomous vehicles.
2. Natural Language Processing: Small text modifications—like typo insertions or synonym swaps—can fool language models into misclassifying sentiment or intent.
3. Cybersecurity: Slightly altered malware code snippets might evade detection tools that rely on static signatures or machine learning filters.
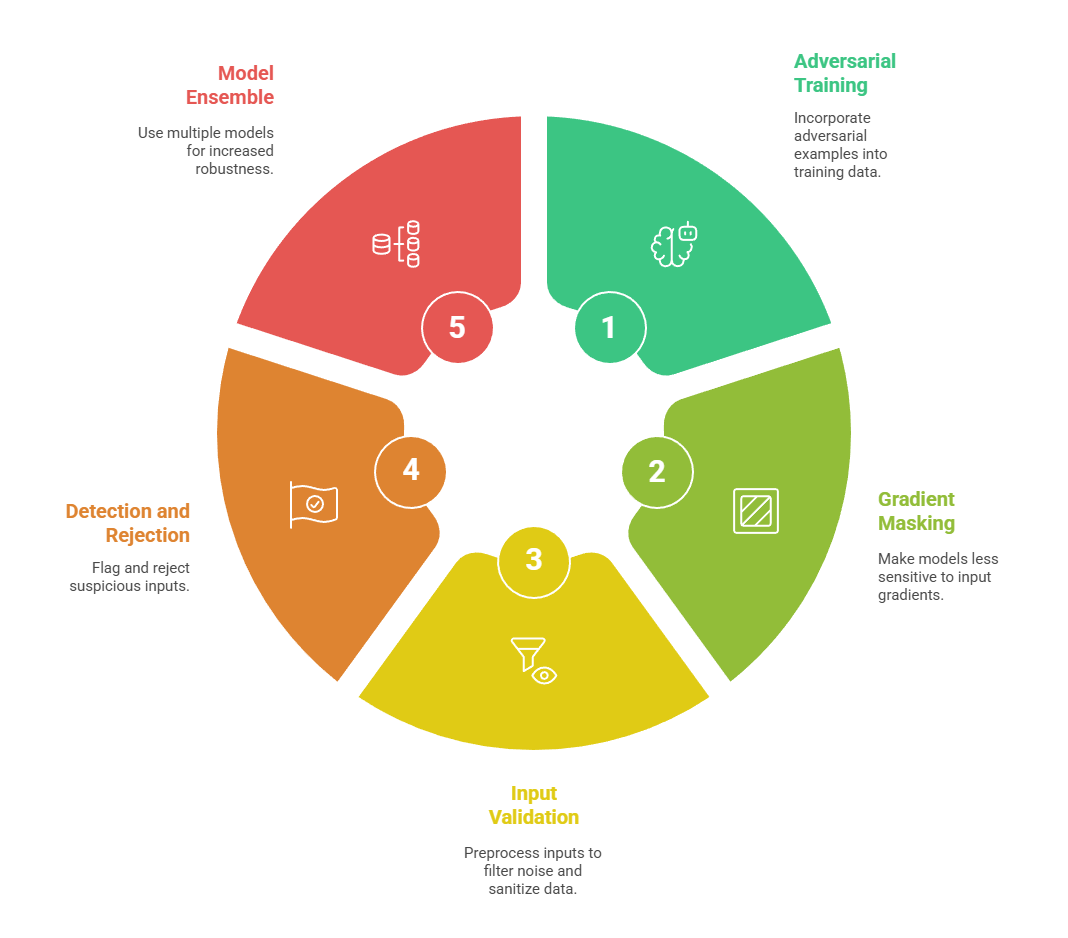
Defense Strategies Against Adversarial Examples
Strengthening AI models against adversarial examples requires proactive measures, including specialized training and model diversification. Below are some of the primary defense strategies employed in practice.