Machine Learning (ML) models, integral to numerous modern applications, have their own unique attack surfaces that differ from traditional software systems. These attack surfaces provide adversaries opportunities to manipulate model behavior, degrade performance, or extract sensitive information.
Two primary high-level categories of attacks against ML models are poisoning attacks and evasion attacks. Understanding these attack surfaces conceptually enables practitioners to identify potential vulnerabilities and implement effective defenses to harden ML systems.
Poisoning Attacks: Threats Targeting Model Training
Poisoning attacks occur during the training phase of an ML model. Here, attackers inject carefully crafted malicious data into the training dataset with the intention to degrade the model's integrity or bias its decisions. Key characteristics include:
1. Training Data Manipulation: By contaminating the data used to train the model, attackers can cause the model to misclassify inputs, reduce accuracy, or behave erratically.
2. Goals of Poisoning: These include causing denial of service by damaging model utility, backdooring the model to trigger attacker-controlled outputs, or embedding stealthy vulnerabilities exploitable at inference time.
3. Attack Vectors: Poisoning can be performed by submitting malicious samples to crowdsourced or publicly accessible training data, intercepting and altering datasets internally, or contaminating data augmentation processes.
4. Real-World Example: Injecting mislabeled images into a facial recognition dataset to cause false negatives or misidentification.
Poisoning attacks exploit the reliance of ML models on training data quality and highlight the importance of securing data pipelines.
Evasion Attacks: Threats Targeting Model Inference
Evasion attacks take place during the model inference or prediction phase. In this case, attackers craft adversarial inputs that, while appearing normal to humans, cause the model to generate incorrect or unexpected results. Important features include:
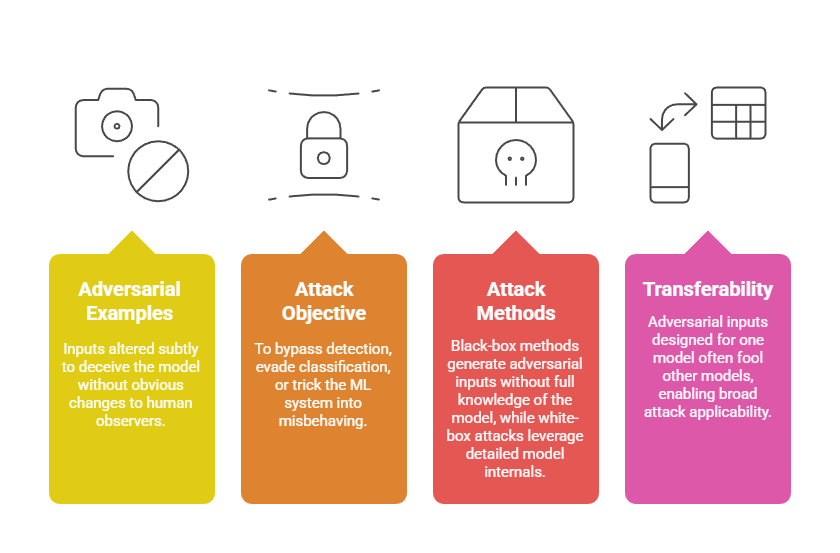
Examples include manipulating spam email features to evade filters or altering road signs to confuse autonomous vehicles.
Other ML Attack Surfaces
While poisoning and evasion are prominent, ML models also face other attack surfaces such as:
Model Extraction: Replicating or stealing proprietary models via repeated queries.
Membership Inference: Inferring whether specific data points were part of the model's training set, risking privacy leaks.
Data Poisoning Variants: Such as backdoor or Trojan attacks embedded during training.
These illustrate the diverse and evolving threat landscape around ML models.
