Common Vulnerabilities and Exposures (CVEs) are standardized identifiers used in cybersecurity to catalog and communicate information about publicly known software vulnerabilities. Interpreting CVE data and accurately scoring their risk is vital for organizations to prioritize remediation and defend against potential attacks.
However, CVE descriptions are often complex, lengthy, and vary in detail, making manual interpretation time-consuming and prone to inconsistencies. Natural Language Models (NLMs), a subset of artificial intelligence based on advanced Natural Language Processing (NLP), are increasingly used to automate and enhance CVE interpretation and risk scoring.
These models analyze the textual description of vulnerabilities, extract relevant information, infer severity factors, and assist in generating consistent, data-driven risk scores, ultimately improving vulnerability management effectiveness.
Understanding Natural Language Models
Natural Language Models employ advanced AI algorithms to understand, generate, and manipulate human language. Recent advances in transformer architectures—such as BERT, GPT, and RoBERTa—have significantly improved machines’ ability to comprehend context, semantics, and intent within text, enabling sophisticated applications in vulnerability analysis:
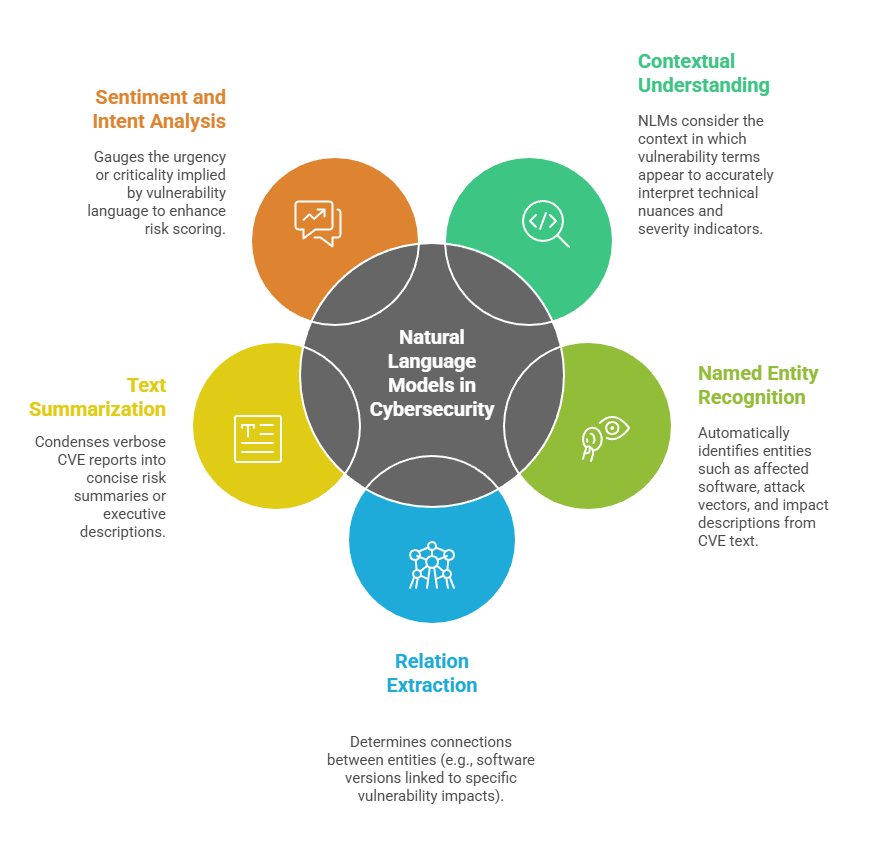
By leveraging these capabilities, natural language models assist in extracting actionable intelligence from heterogeneous and unstructured CVE data sources.
CVE Interpretation Using Natural Language Models
NLMs process CVE entries by analyzing their structured metadata along with unstructured textual descriptions and references. Typical tasks include:
1. Parsing Descriptions: Extracting affected software components, vulnerability types (e.g., buffer overflow, privilege escalation), attack vectors (e.g., remote code execution), and impacted confidentiality, integrity, and availability factors.
2. Identifying Key Indicators: Spotting markers such as exploitation complexity, required privileges, and authentication needs embedded in the textual content.
3. Mapping to Taxonomies: Associating vulnerabilities with OWASP categories, MITRE ATT&CK tactics, or CVSS attributes.
4. Data Enrichment: Integrating additional context from NVD feeds, vulnerability databases, and threat intelligence sources.
This automated interpretation standardizes and accelerates understanding, fostering consistent assessments across varying CVE entries.
Risk Scoring Enhancement
Traditional risk scoring frameworks like CVSS provide a baseline numeric severity score, but often lack contextual organizational factors. Natural language models augment risk scoring by:
1. Dynamic Attribute Analysis: Refining CVSS scores with up-to-date information extracted from CVE text and evolving exploit reports.
2. Threat Landscape Correlation: Weighing risk based on current exploit availability, active attack campaigns, and historical incident data gleaned from threat intelligence.
3. Prioritization Recommendations: Suggesting remediation urgency tailored to organizational asset criticality and exposure.
4. Continuous Learning: Adapting scoring methodologies based on feedback from incident responses and security operations.
These enhancements result in more relevant, timely, and actionable vulnerability prioritization.
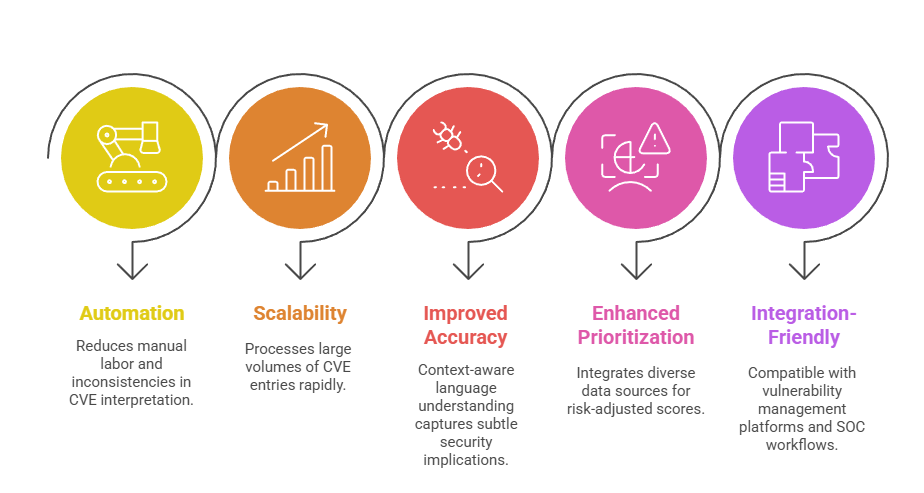
Benefits of Natural Language Models for CVE Analysis
From automation to enhanced prioritization, NLP models transform how organizations interpret and act on CVE data. The following points highlight the main benefits of applying these models.
Challenges and Considerations
Data quality, interpretability, and ethical handling are critical factors in achieving reliable CVE analysis with NLP models. Listed below are key challenges and considerations to guide implementation.
1. Data Quality Dependency: Accuracy depends on the completeness and clarity of CVE descriptions.
2. Model Interpretability: Balancing model complexity with transparency to gain analyst trust.
3. Multilingual and Domain-Specific Language: Handling diverse terminologies and cross-industry vocabularies requires model adaptation.
4. Ethical and Privacy Concerns: Managing sensitive CVE-related data and security disclosures responsibly.
