Prompt injection is a critical vulnerability specific to AI systems that rely on prompt-based interactions, such as Large Language Models (LLMs). This attack involves manipulating the model's behavior by injecting malicious or deceptive inputs (prompts) designed to alter the intended output or bypass safety mechanisms.
Unlike traditional software vulnerabilities, prompt injection exploits the way LLMs process combined natural language instructions and data, potentially leading to unauthorized data leaks, unsafe content generation, or unintended actions.
Preventing prompt injection requires a deep understanding of its mechanisms and a multi-layered defense strategy encompassing input validation, prompt design, monitoring, and ethical considerations.
Understanding Prompt Injection Attacks
Prompt injection occurs when an attacker crafts input prompts that interfere with or override the AI system's intended instructions. Types include:
1. Direct Prompt Injection: The attacker inputs malicious prompts explicitly designed to manipulate model outputs, often exploiting user input fields without proper validation.
2. Stored Prompt Injection: Malicious prompts are embedded in persistent data (e.g., databases, logs) that the AI later processes, causing delayed or triggered malicious behavior.
3. Prompt Leaking: Attackers extract sensitive system or configuration prompts unintentionally revealed by the model.
4. Jailbreaking: A particularly sophisticated prompt injection that coerces the model to bypass content filters or safety constraints outright.
Such attacks can lead to unauthorized data access, generation of disallowed content, or system misuse.
Key Risks of Prompt Injection
The following highlights illustrate critical risks associated with prompt injection. These threats can affect data integrity, system behavior, and overall trust.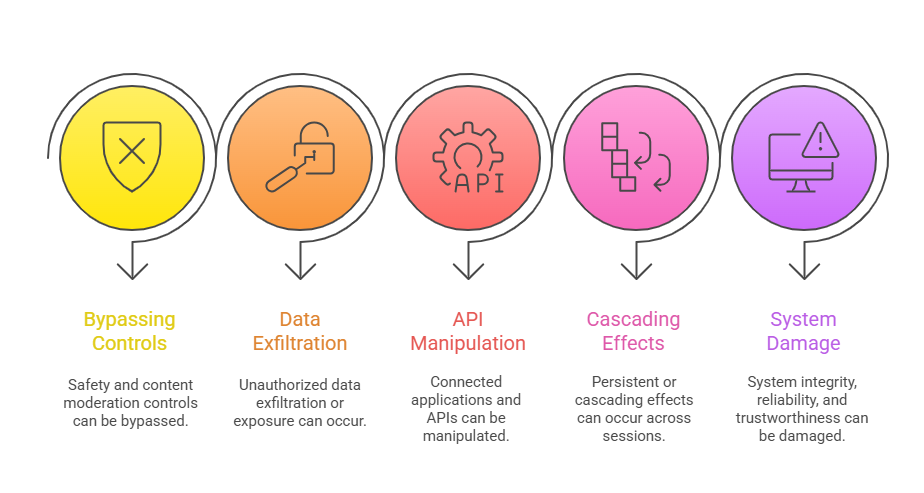
Core Prevention Strategies
A comprehensive defense against prompt injection requires proactive planning and controls. Listed here are the primary strategies to enhance AI security and reliability.
1. Secure Prompt Engineering
Design system prompts with clear role definitions and strict security constraints.
Separate control logic from user data using structured prompt formats to prevent mixing instructions and input.
2. Input Validation and Sanitization
Thoroughly check and cleanse all user inputs and external content before feeding them to the model.
Use allowlists/denylists and advanced pattern detection to block malicious payloads.
3. Output Monitoring and Filtering
Continuously monitor generated outputs for unsafe or unauthorized content.
Apply automated filters and review mechanisms to intercept harmful responses.
4. Access Control and Rate Limiting
Limit interaction frequencies to prevent brute-force injection attempts.
Restrict sensitive model functionalities to authorized users and systems.
5. Isolated Execution and Sandboxing: Run AI components in controlled environments preventing lateral movement or data leaks from compromised modules.
6. Logging and Incident Response
Implement comprehensive logging of all interactions for audit and forensic analysis.
Establish incident response plans specific to prompt injection detection and mitigation.
7. User Training and Awareness: Educate developers, operators, and users about prompt injection risks and safe usage practices.
Ongoing Challenges and Research
Despite current safeguards, prompt injection remains a persistent challenge due to the complexity of LLMs. Below are ongoing issues and active research directions.
1. The inherent complexity and stochastic nature of LLMs make foolproof prevention difficult.
2. Emerging attack vectors require continuous monitoring and timely updates to defenses.
3. Balancing usability and strict restrictions can be challenging.
4. Ethical considerations arise in enforcing content boundaries without limiting legitimate use.
