Machine learning (ML) models, especially those deployed as services accessible via APIs, face significant security risks beyond traditional software vulnerabilities. Among these, model extraction and inference attacks pose critical threats to the confidentiality, integrity, and privacy of both the models themselves and the sensitive data they process.
Model extraction attacks aim to recreate or approximate the underlying ML model by querying it repeatedly, potentially exposing proprietary intellectual property and training data. Inference risks involve adversaries deducing sensitive input or training dataset attributes from the model’s outputs.
Understanding Model Extraction Attacks
Model extraction (or model stealing) occurs when an adversary interacts with a deployed ML model—typically through a public API or service endpoint—to infer its underlying structure, parameters, or decision boundaries. Key conceptual points include:
Attack Mechanics: Through carefully crafted inputs and analyzing model responses (e.g., predictions, confidence scores), attackers iteratively probe the model to reconstruct a functionally equivalent surrogate model.
Targeted Models: Cloud-hosted Machine Learning-as-a-Service (MLaaS) platforms, AI inference APIs, and edge-deployed models are common targets.
Motivations: Attackers aim to steal intellectual property (expensive-to-train models), bypass security controls by replicating models, or obtain auxiliary information about the training data.
Outcomes: Successful extraction undermines confidentiality, enables adversarial exploitation, and may lead to loss of competitive advantage.
Understanding Model Inference Risks
Inference risks arise when adversaries glean sensitive information about training data or inputs solely by accessing model outputs:
1. Membership Inference: Determines if a specific data record was part of the training set, potentially exposing sensitive or private data.
2. Attribute Inference: Predicts additional attributes about inputs or data subjects, beyond what the model ordinarily outputs.
3. Training Data Leakage: Indirectly deduces proprietary or confidential data characteristics embedded in the model.
4. Privacy Implications: Particularly acute when models train on personal, healthcare, or financial data.
Model inference attacks threaten user privacy and can violate legal and ethical data protection requirements.
Impact and Examples
Extracted models don’t just replicate capabilities—they expose vulnerabilities and sensitive information. The following points highlight major impacts and notable examples from real environments.
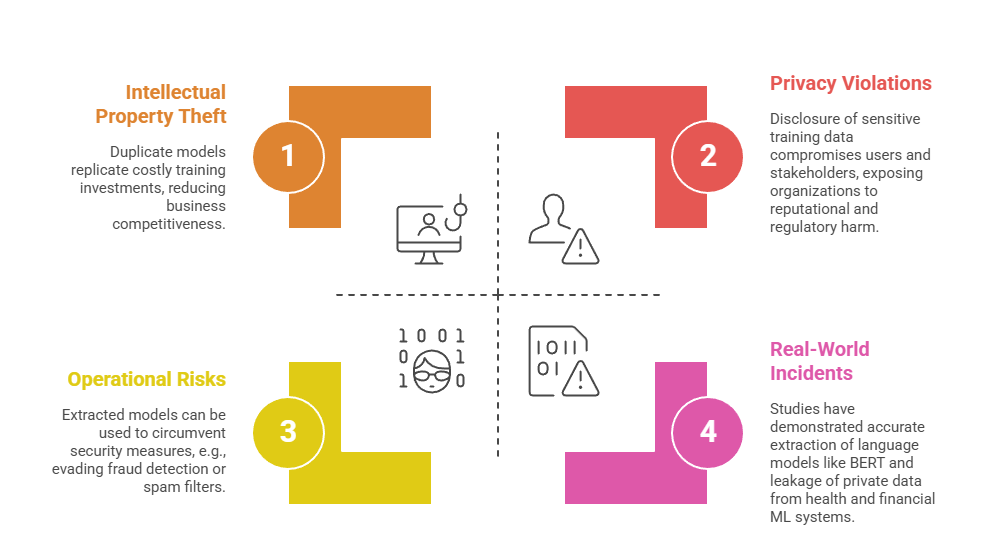
Mitigation Strategies
Model extraction attacks can compromise intellectual property and security, but targeted mitigation steps can reduce exposure.
Listed below are important techniques for preventing unauthorized model replication.
1. Access Control and Query Limiting: Restricting API usage, limiting query volume, and monitoring suspicious access patterns.
2. Output Obfuscation: Reducing output detail such as confidence scores to limit information available to attackers.
3. Differential Privacy: Embedding noise in training or inference to prevent data leakage while maintaining utility.
4. Model Watermarking: Embedding unique signatures in models to detect unauthorized copying or use.
5. Ensemble Methods and Randomization: Increasing unpredictability of model responses to deter extraction.
6. Continuous Monitoring: Detecting anomalous query behavior that may indicate extraction attempts.
