Modern machine learning systems handle massive, continuously growing streams of data generated from mobile applications, IoT devices, enterprise logs, sensors, transactions, and digital platforms.
Traditional ML workflows become inefficient when data increases in volume, velocity, and variability. Scalable ML pipelines address this challenge by automating ingestion, transformation, training, evaluation, and deployment at a scale suitable for enterprise environments.
These pipelines ensure that model updates are fast, reliable, and aligned with real-time business needs.
Real-time processing systems work alongside scalable pipelines to support instant decision-making. Instead of waiting for batch jobs, they react to incoming events within milliseconds, powering applications like fraud detection, predictive maintenance, user personalization, and dynamic pricing.
Technologies such as Kafka, Flink, Spark Streaming, Beam, and Kinesis enable this continuous computation environment.
Together, scalable pipelines and real-time engines form the foundation of intelligent, production-grade ML systems capable of learning, adapting, and generating insights without human intervention.
They also improve reproducibility, tracking, monitoring, and governance across the ML lifecycle.
As organizations shift to cloud-native infrastructures, these approaches have become essential for operationalizing machine learning in rapidly evolving, data-intensive environments.
Scalable ML Pipelines
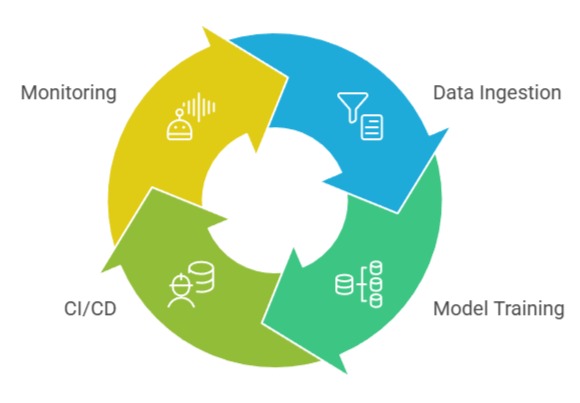
1. Automated Data Ingestion and Preparation
Scalable pipelines handle vast incoming datasets from varied sources—databases, APIs, streams, IoT sensors—without manual oversight.
They use distributed systems to ensure continuous, fault-tolerant extraction, cleaning, and transformation of data.
This automation accelerates model readiness and ensures standardized preprocessing across workflows.
For example, Airflow + Spark pipelines automatically prepare terabytes of data daily for analytical and ML workloads.
Such systems guarantee that irrespective of load surges, the pipeline maintains stability and consistency.
2. Distributed Model Training and Optimization
When training requires extensive computation, scalable pipelines distribute processing across clusters or cloud compute instances.
Frameworks like TensorFlow Distributed, Horovod, and Ray Train allow parallelism across CPUs, GPUs, and TPUs.
This drastically reduces training time, especially for deep learning and ensemble models.
For instance, a training process that takes 10 hours on a single machine may complete in under an hour on a distributed pipeline.
These systems auto-manage resource allocation and fault handling.
3. Continuous Integration & Continuous Deployment (CI/CD) for ML
ML-specific CI/CD pipelines combine version control, automated testing, model validation, and deployment workflows.
They enable rapid iterations without compromising reliability.
Tools like MLflow, Kubeflow, and SageMaker Pipelines track datasets, parameters, model versions, and performance changes.
For example, a retail recommendation model can be updated hourly as new user interactions come in, with each version automatically validated before rollout.
4. Monitoring, Drift Detection, and Auto-Retraining
Production ML models degrade when data patterns shift. Scalable pipelines integrate real-time monitoring, drift alerts, and automated retraining triggers.
These systems examine distributions, accuracy metrics, latency, and input anomalies. For example, in fraud detection systems, changes in transaction patterns may trigger immediate model retraining. Such oversight ensures long-term reliability and regulatory compliance.
Real-Time Processing
Real-time processing enables immediate analysis and response to incoming data, powering dynamic decision-making across applications.
By leveraging streaming engines, event-driven ML, and serverless architectures, organizations can deliver timely insights and actions at scale.
1. Stream Processing Engines
Real-time systems analyze events the moment they arrive, enabling sub-second insights.
Tools such as Kafka Streams, Apache Flink, Spark Streaming, and Google Dataflow support stateful computations, windowing, and event-time processing.
For instance, a streaming engine can detect anomalies in factory IoT sensor data and trigger alerts within milliseconds.
This continuous processing minimizes downtime and enhances situational awareness.
2. Event-Driven ML Inference
Real-time ML systems deploy lightweight, optimized models capable of responding instantly to incoming events.
Technologies like TensorFlow Serving, ONNX Runtime, and SageMaker Endpoints enable scalable, high-throughput prediction services.
For example, ride-hailing apps continuously adjust pricing, ETA predictions, and driver allocations based on live conditions.
This ensures users experience timely, personalized results.
3. Microservices & Serverless ML Inference
Real-time applications often rely on microservices architectures or serverless functions to handle unpredictable workloads.
Tools like AWS Lambda, Azure Functions, and Google Cloud Run allow models to run only when triggered, optimizing cost and scalability.
For instance, image moderation systems invoke ML inference services only when new content is uploaded, making the architecture both efficient and responsive.

Class Sessions
Sales Campaign

We have a sales campaign on our promoted courses and products. You can purchase 1 products at a discounted price up to 15% discount.