Neural network architectures form the backbone of modern artificial intelligence, enabling machines to perceive, understand, and generate complex patterns from data.
Each architecture is designed to solve specific types of problems by mimicking different aspects of human cognition.
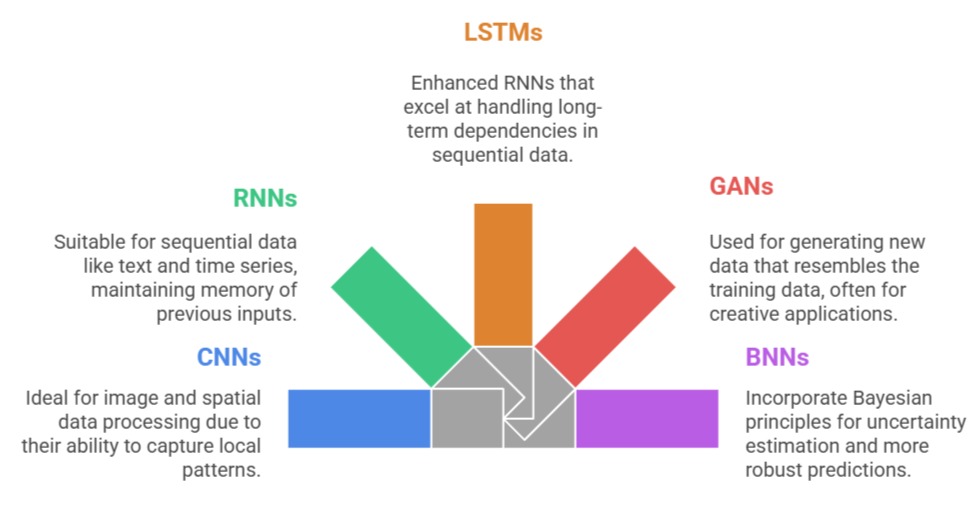
Convolutional Neural Networks (CNNs) excel at analyzing spatial information, making them ideal for image recognition, object detection, and visual pattern understanding.
Recurrent Neural Networks (RNNs) are designed to handle sequential data such as text, speech, or time-series signals, capturing dependencies across time.
Building on this, LSTMs (Long Short-Term Memory networks) improve the limitations of traditional RNNs by remembering long-term relationships and preventing vanishing gradients, making them highly effective for language modeling and sequence prediction.
 Convolutional Neural Networks (CNNs)
Convolutional Neural Networks (CNNs)
Local Feature Extraction and Spatial Awareness
CNNs are engineered to automatically identify spatial patterns in images through convolutional filters that scan smaller regions of the input.
This localized processing enables the network to detect textures, edges, shapes, and higher-order patterns without manual feature engineering.
As the layers deepen, CNNs construct hierarchical abstractions, transforming raw pixels into meaningful representations.
Pooling operations further condense features, promoting invariance to translation or slight distortions.
These characteristics make CNNs particularly strong for vision-focused tasks where structure matters.
Their architecture also reduces parameters compared to fully connected networks, improving efficiency.
This balance of efficiency and spatial intelligence has made CNNs dominant in modern computer vision applications.
Example: In medical imaging, CNNs can analyze MRI scans to identify subtle anomalies such as early-stage tumors by learning minute intensity variations that are impossible to detect manually.
Recurrent Neural Networks (RNNs)
Sequence Modeling and Temporal Dependencies
RNNs incorporate cyclical connections that allow previous outputs to feed into new inputs, giving the network a form of short-term memory.
This structure enables them to interpret ordered data such as sentences, sensor readings, or time-series records.
By maintaining hidden states that evolve over time, RNNs encode contextual information that traditional feedforward networks cannot capture.
However, their dependence on sequential updates makes training computationally intensive for long sequences.
RNNs often struggle with vanishing gradients, which weakens their ability to represent long-distance relationships.
Despite these challenges, they remain valuable for tasks that require understanding order and flow. Their strength lies in modeling transitions and temporal evolution.
Example: An RNN can analyze stock price movements to detect short-term trends by learning temporal fluctuations across consecutive trading periods.
Long Short-Term Memory Networks (LSTMs)
Overcoming Long-Range Dependency Challenges
LSTMs extend RNNs by introducing specialized gates that regulate how information enters, persists, and exits the memory cell.
This architecture enables the model to retain relevant signals over extended periods without succumbing to vanishing gradient issues.
The forget, input, and output gates collaborate to decide which information should be stored or discarded.
Such fine-grained control makes LSTMs effective for tasks with long contextual chains, such as language understanding or anomaly detection in sequences.
Their stable memory behavior allows them to interpret complex time dependencies with higher fidelity.
Although they require more parameters than standard RNNs, their predictive reliability compensates for the additional complexity.
LSTMs continue to be widely adopted where temporal structure is key.
Example: LSTMs can generate text by learning how words relate across long passages, enabling models to construct coherent sentences and maintain context.
Generative Adversarial Networks (GANs)
Adversarial Learning and Synthetic Data Generation
GANs consist of two neural networks—the generator and the discriminator—engaged in a competitive learning loop.
The generator aims to create synthetic samples that mimic real data, while the discriminator evaluates authenticity and provides feedback.
This adversarial setup pushes the generator to improve continuously, refining its outputs until they become nearly indistinguishable from real samples.
GANs excel at learning complex distributions, producing high-quality images, audio, and even structured data.
Their creative capacity has led to breakthroughs in image restoration, artistic style transfer, and simulation.
However, training GANs can be unstable due to the delicate balance required between the two networks. Despite this, they remain one of the most influential deep learning innovations.
Example: GANs are used to generate realistic high-resolution faces, enabling applications in animation, film effects, and synthetic dataset creation for privacy-sensitive environments.
Bayesian Neural Networks (BNNs)
Probabilistic Weight Learning and Uncertainty Estimation
Bayesian Neural Networks integrate Bayesian inference into neural architectures by treating weights as probability distributions rather than fixed parameters.
This approach allows the model to quantify uncertainty in its predictions, offering confidence intervals alongside outputs.
BNNs are especially valuable in sectors requiring reliability under ambiguous conditions, such as autonomous vehicles or healthcare diagnostics.
Their probabilistic nature helps guard against overconfident decisions when presented with unusual or out-of-distribution data.
Training BNNs involves approximating complex posterior distributions, often using techniques like variational inference or Monte Carlo sampling.
This makes them more computationally intensive than standard networks. Nonetheless, the resulting interpretability and uncertainty-awareness greatly strengthen decision-making capabilities.
Example: A Bayesian neural model can estimate uncertainty in identifying defects in manufacturing images, enabling engineers to prioritize cases needing manual review.

Class Sessions
Sales Campaign

We have a sales campaign on our promoted courses and products. You can purchase 1 products at a discounted price up to 15% discount.