Ensemble methods are advanced machine learning techniques that combine multiple models to achieve stronger predictive performance than any single model can deliver on its own.
The core idea is that while individual models may make errors or overfit, groups of models—when combined effectively—balance out weaknesses and amplify strengths.
Ensembles improve accuracy, reduce variance, and enhance robustness, especially in real-world environments where data can be noisy, incomplete, or highly complex.
These methods rely on approaches like bagging, boosting, and stacking, each offering unique ways of aggregating models.
Bagging focuses on reducing variance by training many independent learners on random data samples.
Boosting trains models sequentially, where each new learner focuses on correcting previous mistakes. Stacking blends different types of models to capture diverse learning patterns.
In modern data science practice, ensemble approaches are crucial because many datasets—especially in finance, healthcare, e-commerce, and cybersecurity—contain nonlinear interactions, mixed feature types, and imbalanced classes.
Ensemble techniques help overcome these challenges by providing stability, improved generalization, and higher predictive reliability.
Random Forest
Random Forest is an ensemble algorithm that builds a collection of decision trees using the bagging technique, where each tree is trained on a randomly selected subset of data and features.
This randomness ensures that no two trees are identical, improving generalization and reducing overfitting.
Each tree independently predicts an output, and the final result is obtained through majority voting or averaging, depending on the task. Its structure allows it to handle missing values, nonlinear relationships, and large feature sets with minimal tuning.
Random Forest is also highly interpretable through feature importance measures, making it suitable for domains requiring transparency.
Additionally, it maintains strong performance even with noisy, imbalanced, or high-dimensional data. Due to its versatility, it remains a go-to baseline model for both research and industry applications.
Example: A Random Forest used in medical diagnosis can analyze patient records and symptoms across hundreds of decision trees, producing reliable predictions about disease risk by aggregating their outputs.
Importance of Random Forest
Random Forest is one of the most widely used ensemble learning algorithms due to its reliability, flexibility, and strong performance across diverse datasets.
The following points highlight the key advantages that make Random Forest a popular choice in real-world machine learning applications.
1. Highly Resistant to Overfitting
Random Forest reduces overfitting by training multiple decision trees on different random subsets of data and features.
This diversity prevents any single tree from memorizing the dataset, resulting in a more generalized and stable model.
The ensemble nature ensures that extreme predictions from individual trees are balanced out by the majority.
This makes Random Forest particularly reliable in noisy real-world datasets where simpler models tend to fail.
Even when hundreds of features are present, the method remains robust because randomness avoids dependency on specific attributes.
As a result, Random Forest becomes a dependable baseline when dataset quality is uncertain.
2. Handles High-Dimensional and Complex Data Efficiently
Random Forest performs exceptionally well on datasets with a large number of features, including those with nonlinear interactions.
Because each tree considers only a subset of features at a time, the model avoids computational overload while still uncovering meaningful patterns.
This property is crucial in fields like bioinformatics, finance, fraud analysis, and text analytics, where the feature space is complex and multi-layered.
The algorithm’s ability to capture deep variable relationships makes it suitable for modeling patterns that would otherwise require heavy feature engineering.
Its efficiency provides a practical advantage during exploratory analysis and production-level tasks.
3. Provides Strong Feature Importance Insights
One major benefit of Random Forest is its ability to estimate feature importance, helping practitioners understand which variables most influence predictions.
This interpretability supports data-driven decisions in industries where explanation matters, such as healthcare, insurance, and governance.
Feature importance scores guide better feature selection, reduce model complexity, and highlight key predictors.
These insights also help identify data errors or redundancies that may not be obvious initially.
By offering transparency without sacrificing accuracy, Random Forest bridges the gap between performance and explainability.
4. Performs Well on Both Classification and Regression Tasks
Random Forest is versatile and performs strongly on a wide range of machine learning tasks—from predicting continuous outcomes to categorizing complex classes.
Its design allows it to adapt to different error structures and problem types without requiring architectural changes.
This universality reduces the need for multiple specialized models, especially in end-to-end ML pipelines.
In practice, it is used for disease prediction, loan default risk scoring, churn prediction, and real estate value estimation.
Its consistent behavior across tasks makes it a trusted choice for initial modeling and benchmarking.
5. Robust Against Noise and Missing Data
Random Forest can naturally handle missing values by utilizing surrogate splits and tree-level decision strategies.
Because many trees are built using different subsets of data, the ensemble remains stable even when some information is absent or inconsistent.
This resilience is beneficial in domains where perfect data quality cannot be guaranteed, such as medical records, sensor data, and customer logs.
It minimizes the impact of noisy variables and reduces the risk of biased predictions. As data grows more unstructured, this robustness becomes increasingly valuable.
6. Scales Easily to Large Datasets
Random Forest’s structure supports parallelization since each tree can be built independently.
This makes it suitable for large datasets commonly found in enterprise-level applications.
Distributed computing frameworks like Hadoop, Spark, and cloud-based ML services further accelerate training.
Random Forest maintains accuracy even as the dataset grows, unlike single-tree models that degrade or become unstable.
This scalability ensures long-term usability as organizations expand their data infrastructure.
8. Strong Baseline for Comparison in ML Pipelines
Random Forest is often used as a benchmark because it establishes a reliable performance baseline without extensive hyperparameter tuning.
Its consistent results help practitioners evaluate whether more complex models—like boosting or neural networks—are truly necessary.
This saves time during experimentation and model selection phases.
When more advanced models fail to significantly outperform it, Random Forest is often chosen for deployment due to its balance of simplicity, speed, and accuracy.
Its ability to compete with more modern techniques makes it a timeless tool in machine learning.
Gradient Boosting Machines (GBM)
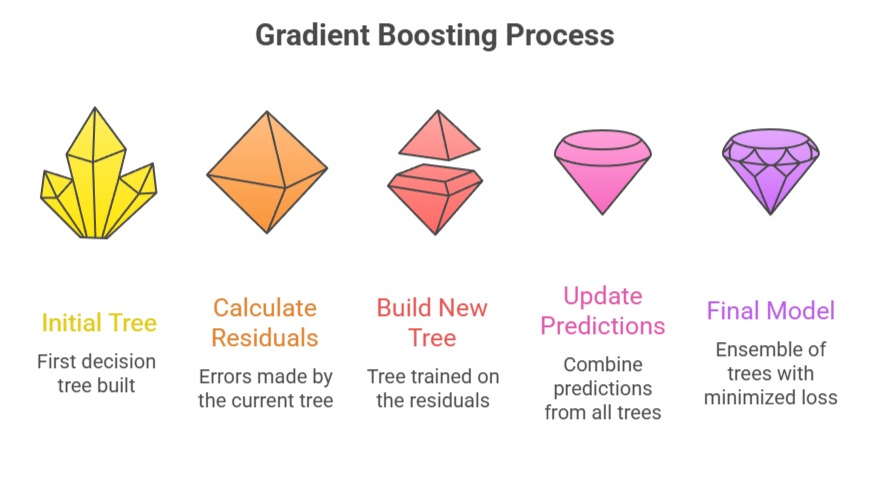
Gradient Boosting is a sequential ensemble method that builds decision trees one at a time, with each new tree correcting the residual errors made by previous trees.
It uses gradient descent concepts to minimize loss functions, making the model highly precise and adaptable to different problem types.
Unlike Random Forest, which grows trees independently, GBM focuses on learning from weaknesses, resulting in strong predictive performance.
However, this sequential learning makes it more sensitive to noise, requiring careful tuning of parameters such as learning rate, tree depth, and regularization.
When these factors are optimized, GBM captures subtle patterns and interactions that simple models cannot detect.
Its flexibility allows it to handle imbalanced datasets, complex structures, and varied feature types. GBM is widely used in scenarios where accuracy outweighs interpretability.
Example: A Gradient Boosting model predicting housing prices improves with every iteration by correcting earlier underestimations or overestimations, ultimately delivering highly accurate predictions.
Importance of Gradient Boosting Machines (GBM)
Gradient Boosting Machines (GBM) are powerful ensemble learning algorithms known for delivering high accuracy and flexibility across a wide range of predictive tasks.
Their importance lies in their ability to model complex relationships while remaining adaptable, interpretable, and effective on structured data.
1. Ability to Learn Complex Patterns Through Sequential Improvement
GBM builds models step by step, where each new tree focuses specifically on correcting the mistakes of the previous ones.
This sequential learning process enables the algorithm to capture subtle interactions, nonlinearities, and deep dependencies that simpler models often miss.
Because errors are gradually reduced at every stage, GBM becomes highly accurate even when relationships in data are complex or hidden.
This makes the method invaluable in applications like pricing models, risk scoring, and high-stakes predictions where precision matters.
The accumulated learning process ensures that the model refines its understanding with every iteration, producing a strong final predictor.
2. Flexibility to Optimize Various Loss Functions
A major strength of GBM is its ability to work with different loss functions, making it adaptable to classification, regression, and even ranking problems.
Unlike traditional algorithms that are limited to specific types of errors, GBM allows practitioners to customize the objective based on domain requirements.
This flexibility supports use cases such as probabilistic forecasting, anomaly detection, or business-specific cost-sensitive tasks.
By matching the loss function closely to the problem, GBM achieves superior alignment with real-world decision goals.
This adaptability is one reason why Gradient Boosting remains relevant across modern industries.
3. Strong Predictive Performance with Proper Tuning
With well-chosen hyperparameters—like learning rate, tree depth, and number of trees—GBM can outperform many classical machine learning models.
Its ability to combine weak learners into a highly accurate ensemble makes it one of the top choices for structured/tabular datasets.
Although sensitive to overfitting, regularization techniques such as shrinkage, subsampling, and early stopping help maintain stability.
When tuned correctly, GBM models consistently perform strongly in competitive benchmarks and real-world applications.
This high performance has made GBM a standard tool in analytics, finance, marketing, and forecasting.
4. Handles Imbalanced and Noisy Data Effectively
GBM is naturally equipped to handle datasets with uneven class distributions because it can weight misclassified examples more heavily during training.
This allows the algorithm to focus on minority classes or rare events that many models ignore.
Additionally, because each successive tree corrects errors from earlier ones, noise becomes progressively less influential if proper regularization is applied.
This makes GBM reliable in domains like fraud detection, medical diagnosis, and network intrusion monitoring, where rare patterns need precise identification.
5. Strong Interpretability Through Tree-Based Structure
Although more complex than a single decision tree, GBM still provides interpretability through feature importance scores, partial dependence plots, and error reduction insights.
These tools help understand how the model improves over time and what features drive the learning process.
This is especially useful in data-sensitive environments such as auditing, compliance, and healthcare analytics.
The sequential structure also allows analysts to examine how each iteration adjusts to previous errors, giving a transparent view of model evolution.
6. Works Well with Smaller or Medium-Sized Datasets
Unlike deep learning models that require massive datasets, GBM can achieve excellent results even with moderate data volume.
The boosting mechanism amplifies learning efficiency by recycling residual errors, allowing the model to uncover meaningful patterns from limited information.
This efficiency makes GBM suitable for business environments where data collection is expensive or restricted.
XGBoost (Extreme Gradient Boosting)
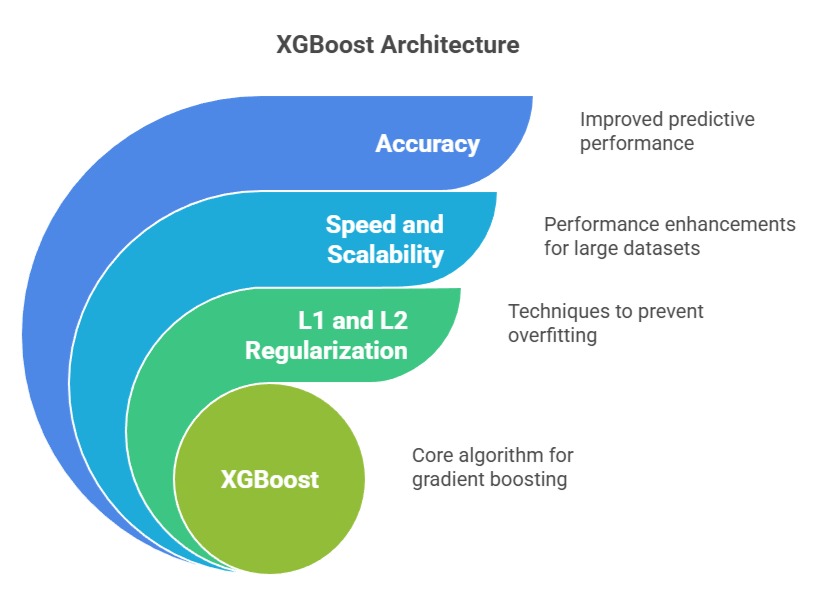
XGBoost is an enhanced version of Gradient Boosting engineered for superior speed, scalability, and accuracy.
It adds L1 and L2 regularization to control model complexity and prevent overfitting, making it more stable than traditional GBM.
XGBoost constructs trees using optimized algorithms that support parallel processing and distributed computing, dramatically reducing training time for large datasets.
It automatically handles missing values, sparsity, and weighted data, making it suitable for production-level systems.
Advanced pruning strategies ensure optimal tree structures, while clever caching and memory optimization further improve efficiency.
These enhancements allow XGBoost to consistently achieve top performance in machine learning competitions.
Its adaptability makes it ideal for tasks involving millions of records, such as financial predictions, anomaly detection, and recommendation systems.
Example: In a fraud detection system, XGBoost can analyze massive transaction logs rapidly and accurately identify suspicious patterns that traditional models might overlook.
Importance of XGBoost (Extreme Gradient Boosting)
XGBoost (Extreme Gradient Boosting) is a highly optimized boosting algorithm designed to deliver exceptional accuracy, speed, and scalability.
Its importance stems from its ability to handle large, complex datasets while maintaining strong generalization and flexibility across diverse machine learning tasks.
1. Exceptional Speed and Scalability for Large Datasets
XGBoost is engineered with highly optimized algorithms that support parallel processing, cache optimization, and distributed computing.
These innovations drastically reduce training time, especially for datasets with millions of rows and hundreds of features.
Its ability to scale across multi-core processors and cloud environments makes it a top choice for enterprise-level machine learning systems.
As organizations deal with growing data volumes, XGBoost remains one of the most efficient and performant algorithms available.
This speed advantage is a primary reason for its dominance in ML competitions.
2. Strong Regularization to Reduce Overfitting
XGBoost incorporates L1 and L2 regularization, which penalize overly complex models and help maintain generalization.
This prevents the model from memorizing noise or anomalies in the training dataset.
Regularization makes XGBoost significantly more stable compared to traditional GBMs, especially on high-dimensional or noisy data.
These enhancements allow it to maintain high accuracy while avoiding common pitfalls associated with boosting methods.
3. Automatic Handling of Missing and Sparse Data
XGBoost intelligently learns the best direction to follow in a decision tree when values are missing.
This eliminates the need for preprocessing steps such as imputation and makes the model robust to real-world datasets with incomplete records.
Sparse data, such as text vectors or log data, is handled efficiently using internal optimizations.
This capability makes XGBoost ideal for domains like NLP, web analytics, and recommendation systems where missingness is common.
4. Highly Effective for Structured/Tabular Data
While deep learning dominates unstructured data, XGBoost remains unmatched for structured datasets commonly found in business, finance, operations, and analytics.
Its tree-based mechanism excels in capturing relationships across numerical and categorical data.
As a result, industries use it for credit scoring, fraud detection, marketing segmentation, demand forecasting, and customer behavior modeling. In many cases, XGBoost outperforms neural networks on such data types.
5. Supports Custom Loss Functions and Extensive Tuning
XGBoost allows practitioners to define custom objectives, making it adaptable to advanced problem types like ranking, survival analysis, and specialized business metrics.
It also offers a rich set of hyperparameters including tree depth, learning rate, subsampling ratios, regularization strengths, and more.
These controls help experts fine-tune the model to reach exceptional performance. Its flexibility appeals to professionals solving niche or domain-specific challenges.
6. Consistently High Performance in ML Competitions
XGBoost has become a standard tool for winning Kaggle competitions and similar challenges due to its reliability, accuracy, and efficient training pipeline.
It performs well even with minimal feature engineering, and with tuning, it often reaches state-of-the-art results.
This speaks to its algorithmic strength and ability to generalize across diverse datasets.
7. Support for Distributed and Cloud-Based Training
With built-in support for distributed systems like Hadoop, Spark, and Kubernetes, XGBoost scales effortlessly in cloud platforms.
This makes it suitable for massive analytics workloads and continuous production retraining.
Its compatibility with enterprise ML pipelines ensures that it fits seamlessly into modern data engineering ecosystems.

Class Sessions
Sales Campaign

We have a sales campaign on our promoted courses and products. You can purchase 1 products at a discounted price up to 15% discount.