Federated Learning (FL) represents a transformative shift in machine learning by allowing multiple devices or organizations to collaboratively train a model without exposing their local data.
Instead of sending raw datasets to a central server, FL distributes the training process itself, enabling data holders to retain ownership and control.
This paradigm significantly strengthens privacy safeguards, reduces data-transfer risks, and supports regulatory compliance in sectors where confidentiality is essential, such as finance, healthcare, and telecommunications.
Privacy-preserving ML expands upon FL by incorporating advanced cryptographic and statistical safeguards like Secure Multiparty Computation (SMPC), Differential Privacy (DP), and Homomorphic Encryption (HE).
These techniques aim to mitigate model inversion attacks, membership inference threats, and gradient leakage—risks that could reveal sensitive patterns even when raw data is not shared.
Together, FL and privacy-preserving techniques create a robust ecosystem for training reliable, scalable, and secure models in distributed environments.
They enable organizations to tap into diverse, real-world data sources while minimizing exposure and abiding by strict data governance mandates.
As AI adoption accelerates across industries, these technologies help bridge the gap between performance and protection, ensuring that innovation does not compromise user trust or legal boundaries.
Federated Learning for Secure, Decentralized, and Privacy-First Machine Learning
Federated learning enables collaborative model training across decentralized devices while keeping raw data local, ensuring privacy and regulatory compliance.
By combining techniques like differential privacy, secure multiparty computation, and homomorphic encryption, it supports secure, scalable, and privacy-first machine learning.
1 Decentralized Collaborative Learning Architecture
Federated learning enables multiple nodes—such as smartphones, hospitals, or regional data centers—to train a shared model without moving local datasets.
Each participant performs computations locally and only forwards model updates or gradients to the central coordinator.
This structure reduces communication of sensitive material while allowing continuous enhancement of model accuracy.
For example, a global predictive keyboard model improves using user typing patterns without Google or Apple collecting actual keystrokes.
This decentralized setup is particularly beneficial when bandwidth restrictions or compliance constraints prohibit large-scale data aggregation.
2 Enhanced Data Privacy Through Localized Processing
Since raw data never exits its source, federated learning ensures regulatory adherence and strengthens privacy controls by design.
Organizations can collaborate without violating internal confidentiality policies or external mandates like GDPR or HIPAA.
Local training minimizes the exposure of personal identifiers, biometric patterns, or confidential documents.
For instance, hospitals across different countries can jointly develop diagnostic tools using patient CT scans while respecting regional medical privacy laws.
This local-centric training drastically reduces the chance of sensitive information leaking through centralized repositories.
3 Differential Privacy for Gradient Protection
Even when raw data is not shared, gradients can accidentally reveal user-specific features.
Differential Privacy (DP) addresses this by injecting carefully controlled noise into updates before they leave the device.
This noise masks individual patterns while preserving aggregate learning trends. For example, an e-commerce platform using DP-enhanced FL ensures that customer purchase histories cannot be extracted from the model updates by adversarial actors.
DP strengthens anonymity guarantees and deters membership inference attacks, making it a vital layer for privacy-preserving ML ecosystems.
4 Secure Multiparty Computation (SMPC) for Encrypted Collaboration
SMPC enables multiple parties to jointly compute functions on their data while keeping inputs completely secret.
Each participant encrypts their local values, and computations occur on encrypted fragments without needing decryption.
This mechanism is crucial when institutions like banks must collaborate on fraud detection models but cannot reveal internal customer records.
SMPC ensures that even the central aggregator cannot see individual contributions.
By maintaining strict confidentiality during aggregation, this approach reduces risks associated with insider attacks or system breaches.
5 Homomorphic Encryption for Secure Model Updates
Homomorphic Encryption (HE) allows computations directly on encrypted data, enabling secure aggregation in federated systems.
Model updates can be combined or averaged without exposing their contents.
This is particularly useful in sensitive sectors like defense or pharmaceutical research, where even gradient values contain proprietary insights.
For example, multiple labs working on drug discovery can collaboratively train molecular structure prediction models with HE ensuring no lab gains access to another’s chemical datasets.
HE preserves utility while maintaining strict secrecy across stakeholders.
6 Resilience Against Gradient Leakage and Model Inversion Threats
Privacy-preserving ML techniques collectively protect against attacks aimed at reconstructing sensitive input data from shared updates.
Adversaries can sometimes reverse-engineer facial images, medical records, or location traces if defenses are weak.
Federated learning combined with DP and SMPC complicates these attacks by distributing training and masking contributions.
For example, a fitness app using FL prevents attackers from reconstructing user heartbeat patterns from server-received gradients.
This layered protection ensures safety even when adversaries target the model update channel.
7 Scalable Deployment Across Heterogeneous Devices
Federated learning accommodates a wide variety of edge devices, from smartphones to IoT sensors to enterprise servers, despite differences in computing power, storage, or connectivity.
By supporting asynchronous updates and partial participation, FL ensures that training remains uninterrupted even when some nodes are offline.
For instance, a smart-home ecosystem can train anomaly detection models using distributed sensors that intermittently connect.
This flexibility boosts model robustness while reducing infrastructure overhead associated with centralized data processing.
Importance of Federated Learning & Privacy-Preserving ML
Federated learning and privacy-preserving ML are crucial for building AI systems that respect user data, comply with regulations, and maintain organizational control.
They enable ethical, secure, and efficient model training while fostering trust and innovation across industries.
1 Enables Ethical AI at Scale
Federated Learning places privacy, user control, and data protection at the core of model development.
By removing the need to store massive volumes of personal information in centralized servers, it minimizes ethical risks linked to surveillance, profiling, and consent violations.
This structure also reduces dependency on opaque data collection systems.
For instance, FL-powered mobile applications improve user experience without harvesting personal files or logs.
2 Supports Highly Regulated Industries
Sectors such as finance, healthcare, and public administration operate under strict data governance laws.
Federated learning allows these organizations to collaborate without breaking regulatory rules such as HIPAA, RBI mandates, GDPR, and other regional privacy frameworks.
For example, hospitals from different cities can jointly train medical image classification models while keeping patient scans within the hospital network.
This approach is important because it enables innovation even under rigid compliance constraints and ensures that industries with sensitive data do not fall behind in AI adoption.
3 Promotes Data Sovereignty and Organizational Autonomy
Federated learning gives institutions full control over how and where their data is stored, processed, and protected.
This minimizes risks of external access and prevents third parties from misusing proprietary datasets.
For example, telecom operators can improve network optimization models collaboratively while maintaining ownership of subscriber logs.
This importance lies in ensuring organizations retain strategic advantage without compromising on data-driven modernization.
4 Reduces Infrastructure Burden and Network Bottlenecks
Instead of transferring heavy datasets to a central location, federated learning distributes computation across participants.
This drastically lowers the need for large data centers and cuts down bandwidth usage.
Smart devices like wearables or sensors can train models locally with minimal cloud support.
This becomes essential as data generation continues to escalate, making centralized pipelines inefficient, slower, and costly.
5 Strengthens User Trust and Transparency
Users increasingly question how companies collect, store, and exploit their personal data.
Federated learning demonstrates a privacy-conscious approach, helping organizations build trust.
For instance, virtual keyboard apps disclose that they never upload typed text to servers.
This importance is tied to brand reputation, customer loyalty, and long-term sustainability in AI-driven products.
Challenges & Limitations of Federated Learning
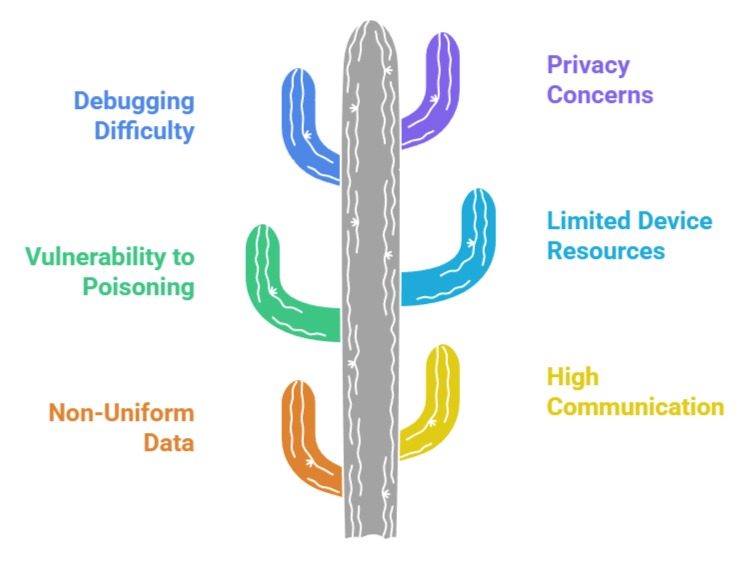
1 Non-Uniform Data Distribution Across Clients
In FL, each user or node generates different types of data, often imbalanced or noisy.
This non-IID (non-identically distributed) data slows convergence and can cause the global model to favor some user groups over others.
For example, a predictive keyboard model may become biased if most participating devices belong to one language group.
Handling these irregularities requires specialized optimization techniques, making model training more complex.
2 High Communication Overhead During Model Updates
FL requires continuous exchange of weight updates between devices and the central server.
When thousands or millions of clients participate, bandwidth consumption becomes significant.
Mobile devices on slow networks may drop out frequently.
This challenge makes it hard to scale FL reliably, especially in regions with unstable connectivity.
3 Vulnerability to Model Poisoning and Malicious Participants
Since FL aggregates updates from many distributed sources, attackers may inject corrupted gradients to manipulate the global model.
A malicious device could send poisoned updates that degrade accuracy or introduce harmful predictions.
For example, poisoning attacks on spam filters could force the model to misclassify harmful emails as safe.
Ensuring robust aggregation and validation mechanisms is still an ongoing research challenge.
4 Limited Device Resources and Energy Constraints
Training models on smartphones, wearables, or IoT sensors consumes power, memory, and processing capacity.
Continuous participation may drain battery life or slow down device performance.
Lightweight architectures and compression strategies are needed, but these trade-offs can reduce model accuracy or training frequency.
5 Difficulty in Debugging and Monitoring Distributed Systems
In centralized ML, engineers can inspect datasets, logs, and training processes.
With FL, everything happens in remote devices, making debugging difficult.
If training fails due to corrupted local data or device malfunction, developers have limited insight.
This complicates quality control and increases operational overhead.
6 Privacy Isn’t Fully Guaranteed Without Strong Cryptographic Layers
Although FL avoids sharing raw data, gradients and parameters may still leak private information.
Without differential privacy, secure aggregation, or encryption, attackers can reverse-engineer sensitive features.
This reveals that FL alone isn’t a perfect privacy shield and must be paired with additional defenses.

Class Sessions
Sales Campaign

We have a sales campaign on our promoted courses and products. You can purchase 1 products at a discounted price up to 15% discount.