Star Schema and Snowflake Schema are two foundational data modeling techniques widely used in data warehousing and business intelligence systems.
Both designs aim to organize data in ways that facilitate efficient querying and reporting by structuring data into fact and dimension tables.
However, they differ significantly in their level of normalization, complexity, storage efficiency, and query performance.
Star Schema
It is a straightforward and intuitive design where a central fact table connects directly to multiple denormalized dimension tables.
This flat structure simplifies querying by minimizing the number of join operations necessary, which accelerates report generation and ad hoc data exploration.
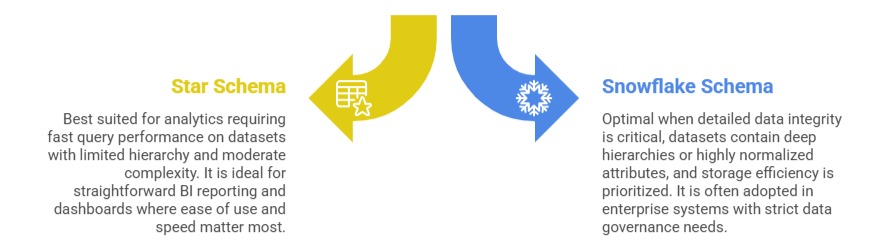
The simplicity of the star schema makes it easy to understand and implement but it stores redundant data within the dimension tables, leading to potentially higher storage requirements.
Star Schema Characteristics
1. Central fact table containing measurable business metrics (e.g., sales, revenue, transactions).
2. Surrounding denormalized dimension tables with descriptive attributes (e.g., product, customer, time).
3. Simpler structure with fewer tables and joins, improving query speed.
4. Higher data redundancy due to denormalization of dimensions.
5. Preferred for fast querying, straightforward reporting, and smaller to medium data volumes.
6. Easier for business users to understand and navigate.
Snowflake Schema
It normalizes dimension tables into multiple related sub-tables, resembling a snowflake shape. This approach reduces data redundancy by decomposing data into finer granularity and establishing foreign key relationships among the normalized tables.
While this results in more complex queries involving additional joins, it offers better data integrity, reduced storage space, and is well-suited for handling detailed hierarchies and complex dimensions.
Snowflake Schema Characteristics
1. Central fact table connected to normalized dimension tables split into multiple related sub-dimensions.
2. Dimension tables are decomposed to avoid redundancy and improve data consistency.
3. More complex schema requiring more joins, leading to slower query performance.
4. Reduced storage footprint due to normalization.
5. Suitable for large, complex datasets with hierarchical or multi-level dimensions.
6. Better data integrity and easier maintenance of dimension data updates.
When to Use Which Schema

Class Sessions
Sales Campaign

We have a sales campaign on our promoted courses and products. You can purchase 1 products at a discounted price up to 15% discount.