Transfer learning is a powerful technique in deep learning that leverages knowledge gained from a pretrained model on one task to improve performance on a different but related task.
Rather than training a network from scratch, which is often resource-intensive and data-hungry, transfer learning allows practitioners to build on pretrained feature representations learned from large datasets like ImageNet or COCO.
This approach is particularly valuable when the target dataset is small, specialized, or costly to label.
Fine-tuning is an extension of transfer learning where certain layers of the pretrained model are adjusted or retrained on the target dataset. It allows the network to adapt its generic learned features to the specific nuances of the new task.
They accelerate model convergence, reduce the need for massive computational resources, and improve generalization by leveraging rich prior knowledge.
Transfer Learning
Transfer learning involves using a pretrained model—trained on a large source dataset—and applying it directly or partially to a new task.
Typically, earlier layers of the network, which capture general features such as edges or textures in images, are reused, while the later layers can be adapted to the specific task.
Advantages
1. Reduces Training Time and Computational Cost
Since pretrained networks already contain valuable feature representations, training requires significantly fewer epochs.
This reduces GPU/TPU usage and accelerates model development.
Tasks that previously demanded days of training can be completed in hours or minutes, making transfer learning ideal for rapid prototyping and practical deployment.
2. Improves Performance on Small Datasets
Transfer learning enables high accuracy even when the target dataset is limited in size.
By leveraging rich features learned from large datasets, the model avoids overfitting and extracts meaningful patterns from sparse data, making it effective in medical imaging, remote sensing, and niche NLP tasks.
3. Leverages State-of-the-Art Architectures
Using pretrained models such as ResNet, BERT, or EfficientNet allows practitioners to benefit from cutting-edge architectures without implementing them from scratch.
This ensures access to highly optimized feature extractors, improving model robustness and accuracy on diverse tasks.
4. Facilitates Cross-Domain Applications
Transfer learning allows knowledge learned from one domain to be applied to a related domain, even when the data distribution differs slightly.
For instance, a model trained on general object detection can be adapted to detect industrial defects.
This cross-domain adaptability saves time, effort, and resources, enabling solutions in specialized fields where labeled data is scarce.
5. Reduces Risk of Poor Convergence
Starting from pretrained weights provides the network with a well-initialized starting point.
This reduces the likelihood of poor convergence that can occur with random initialization, especially in deep architectures. Networks are less likely to get stuck in suboptimal minima, leading to more consistent training outcomes.
6. Encourages Model Reusability
Pretrained models can serve as reusable components across multiple projects or tasks.
This modularity encourages knowledge sharing and reduces redundancy in model development.
Teams can build pipelines that leverage existing models for rapid deployment, facilitating faster iteration and experimentation.
Disadvantages
1. Domain Mismatch Issues
If the source and target datasets are very different, pretrained features may not transfer effectively, limiting performance.
For instance, a model trained on natural images may struggle with medical X-rays without proper adaptation. This requires careful evaluation of source-target similarity.
2. Reduced Flexibility
While transfer learning accelerates training, it may constrain model design.
Practitioners are often limited to the architecture and input formats of pretrained models, making customization more challenging. Adapting large networks to novel tasks may also be resource-intensive.
3. Possible Overfitting on Target Dataset
Although pretrained models help generalization, fine-tuning without caution on small datasets can still lead to overfitting, especially if too many layers are updated or learning rates are too high. Monitoring validation performance is essential to prevent degradation.
4. Licensing and Intellectual Property Restrictions
Some pretrained models may have usage restrictions or licensing limitations.
Applying them to commercial applications may require permissions or compliance with specific terms.
This can limit accessibility for certain organizations or restrict deployment in proprietary systems.
5. Limited Customization of Pretrained Features
While pretrained networks provide high-quality representations, they may not perfectly match the target task’s needs.
Modifying internal layers for full customization can be complex and may reduce the benefits of pretraining, limiting flexibility for unique or niche applications.
6. Potential Bias in Source Dataset
Pretrained models inherit biases present in the source dataset, which can propagate into the target task.
For Example, models trained on internet images may have demographic or cultural biases. This can affect fairness and ethical deployment, requiring careful evaluation and mitigation strategies.
Importance
![]()
Challenges
1. Choosing the appropriate pretrained model for the target task.
2. Managing differences in data distribution between source and target datasets.
3. Deciding which layers to freeze or retrain to balance generalization and adaptation.
4. Ensuring the network does not overfit small datasets during adaptation.
5. Handling input size, resolution, and modality differences across datasets.
Fine-Tuning
Fine-tuning is the process of unfreezing certain layers of a pretrained network and retraining them on the target dataset.
This allows the model to adjust higher-level feature representations to task-specific patterns while retaining general features learned from the source dataset.
Fine-tuning is especially beneficial when the source and target domains are similar but require slight adjustments for optimal performance.
Advantages
1. Optimizes Pretrained Features for Specific Tasks
By retraining select layers, fine-tuning refines generic representations to capture task-specific details.
This improves accuracy and allows models to excel in specialized domains such as medical diagnosis or sentiment analysis, where subtle patterns are critical.
2. Enhances Generalization
Fine-tuning retains the general knowledge from large datasets while tailoring the model to new data.
This prevents overfitting on small datasets and improves the model’s ability to handle unseen data, producing robust and reliable predictions.
3. Flexibility in Layer Selection
Practitioners can choose which layers to unfreeze based on task complexity.
For closely related tasks, retraining only the final layers may suffice; for moderately different tasks, more layers can be adapted.
This selective approach balances computational efficiency and performance improvement.
4. Improves Feature Specificity
Fine-tuning allows the network to adapt general features to task-specific characteristics.
For Example, in medical imaging, fine-tuning a general image classification model improves the detection of subtle patterns like tumors.
This specialization enhances accuracy and enables precise predictions in critical applications.
5. Enables Gradual Adaptation
Fine-tuning can be performed incrementally, retraining only higher layers first and gradually including lower layers.
This staged adaptation reduces the risk of overfitting and catastrophic forgetting, ensuring the model retains useful general knowledge while learning new task-specific features.
6. Supports Multimodal or Multi-Task Learning
Fine-tuning can adapt a pretrained model to multiple related tasks simultaneously.
For Example, a single language model can be fine-tuned for sentiment analysis, question answering, and summarization. This flexibility allows one pretrained backbone to serve multiple purposes efficiently
Disadvantages
1. Risk of Catastrophic Forgetting
Excessive fine-tuning may erase valuable features learned from the source dataset, reducing generalization.
Careful control of learning rates and selective layer training is necessary to avoid forgetting previously acquired knowledge.
2. Requires Careful Hyperparameter Tuning
Fine-tuning is sensitive to learning rates, batch sizes, and number of retrained layers.
Improper settings can destabilize training, cause overfitting, or reduce the benefits of transfer learning.
Systematic experimentation is often required to find the optimal configuration.
3. Computationally Intensive for Large Models
While fine-tuning reduces total training time compared to full training, updating multiple layers of large networks can still be computationally expensive.
Efficient resource allocation and hardware considerations are necessary, particularly for transformer-based models like BERT or GPT.
4. Requires Careful Monitoring to Prevent Overfitting
Fine-tuning on small or noisy datasets can easily lead to overfitting, especially if too many layers are retrained.
Continuous monitoring of validation metrics is essential, and regularization techniques may need to be applied alongside fine-tuning.
5. Hyperparameter Sensitivity
Fine-tuning introduces additional hyperparameters, such as learning rate schedules, batch sizes, and the number of layers to retrain.
Poor choices can destabilize training, erase pretrained knowledge, or limit performance gains, requiring careful experimentation and tuning.
6. Can Be Resource-Intensive for Large Models
While generally faster than training from scratch, fine-tuning large pretrained networks still requires significant computational resources.
Transformer models or deep CNNs may demand GPUs or TPUs, which can limit accessibility for practitioners with constrained hardware.
Importance of Fine-Tuning
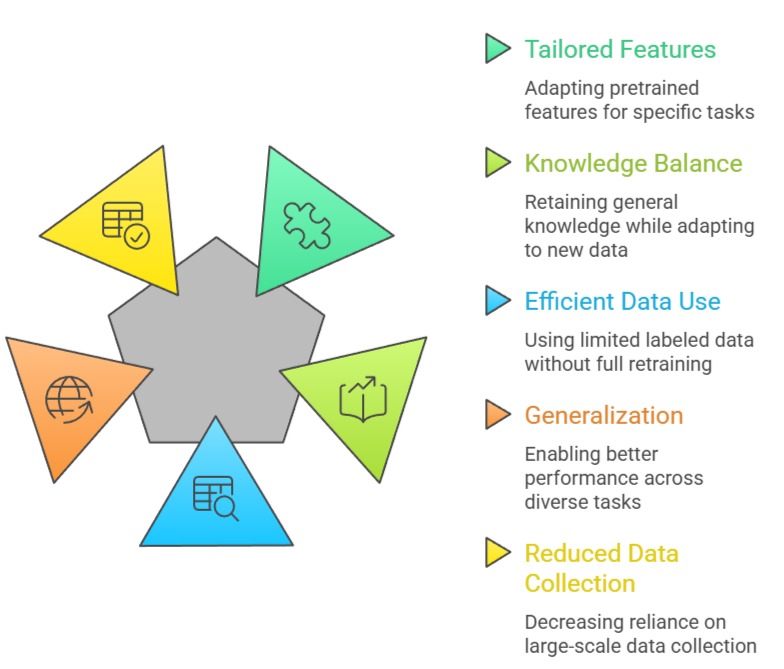
Challenges
1. Determining which layers to freeze and which to retrain.
2. Avoiding overfitting on small or noisy datasets.
3. Selecting appropriate learning rates to prevent catastrophic forgetting.
4. Balancing computational cost and training efficiency.
5. Adapting models across domains with significant distribution differences.

Class Sessions
Sales Campaign

We have a sales campaign on our promoted courses and products. You can purchase 1 products at a discounted price up to 15% discount.