In traditional supervised learning, models require large amounts of labeled data to learn patterns and generalize effectively to unseen examples.
However, in many real-world scenarios, acquiring extensive annotated datasets is costly, time-consuming, or even impractical.
To address these limitations, few-shot learning and zero-shot learning have emerged as advanced paradigms that allow models to generalize with minimal or no labeled data.
Few Shot Learning
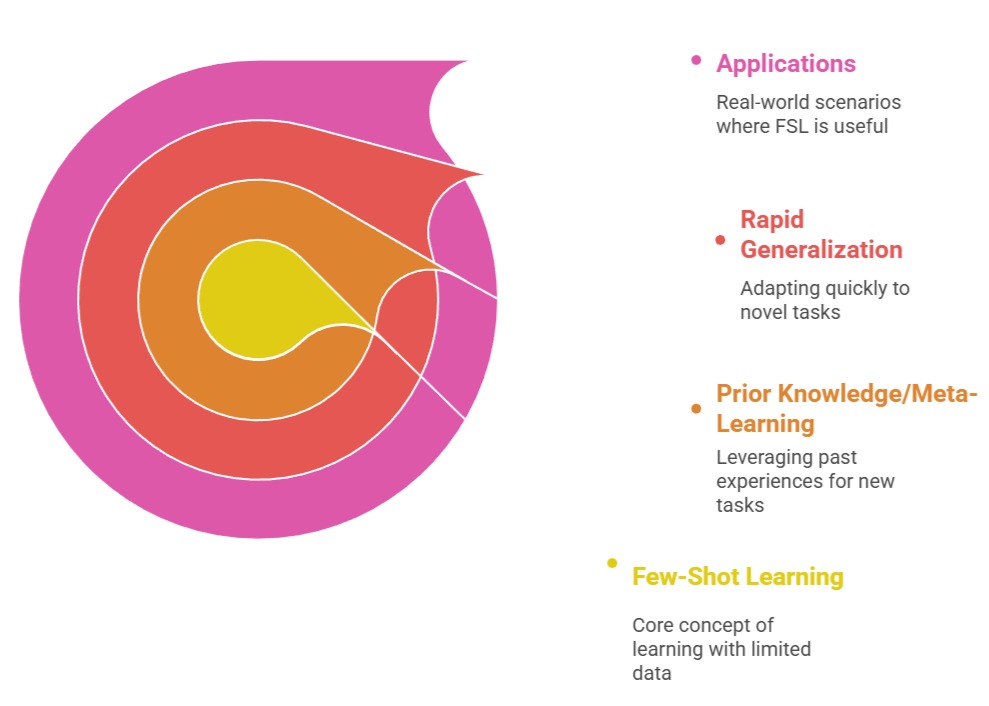 Few-shot learning (FSL) refers to the ability of a model to learn and adapt to a new task using only a small number of labeled examples—often just a few per class.
Few-shot learning (FSL) refers to the ability of a model to learn and adapt to a new task using only a small number of labeled examples—often just a few per class.
The key idea is to leverage prior knowledge or meta-learning from previously seen tasks so that the model can rapidly generalize to novel tasks without retraining from scratch.
Few-shot learning is particularly valuable in domains such as healthcare, rare language translation, wildlife recognition, and any scenario where labeled data is scarce.
By using prior experience and transfer learning techniques, few-shot models efficiently learn representations that capture the essential structure of new tasks.
Advantages
1. Rapid Adaptation to New Tasks
Few-shot learning allows models to quickly adapt to new tasks with only a few labeled examples.
By leveraging prior knowledge through meta-learning or transfer learning, the model can extract essential patterns from minimal data.
This capability is particularly beneficial in domains where labeling is expensive, such as medical imaging, rare language processing, or specialized scientific datasets.
Few-shot learning reduces training time and data collection efforts, enabling faster deployment in real-world scenarios.
2. Data Efficiency
FSL models significantly reduce the dependence on large annotated datasets.
They utilize prior knowledge to infer features of new tasks from very limited examples.
This makes them highly practical in low-resource environments, such as small businesses, emerging research fields, or situations where data privacy limits access to large datasets.
Efficient use of limited data ensures better cost-effectiveness and wider applicability of AI solutions.
3. Task Versatility
Few-shot learning supports multiple tasks using a single underlying model.
The model can perform classification, regression, or sequence prediction across different domains without retraining from scratch.
This versatility allows organizations to maintain one robust system for diverse applications, from image recognition to NLP tasks, rather than building separate models for each scenario.
Disadvantages
1. Sensitive to Example Quality
Few-shot models rely heavily on the representativeness of the provided examples.
Poorly chosen or biased examples can mislead the model, resulting in incorrect predictions or low generalization performance.
The small sample size makes the model vulnerable to outliers or atypical data points.
2. Limited Robustness
With very few examples, the model may not capture the full variability of a task.
Noisy inputs or domain shifts can drastically reduce performance, limiting the model's reliability in real-world environments where data distributions fluctuate.
3. Computational Overhead in Meta-Learning
Although data-efficient, FSL often requires complex meta-learning architectures or pretraining on multiple related tasks.
This adds computational complexity and can increase training time and resource requirements, which may be challenging for smaller organizations.
Examples
1. Classifying rare diseases with only a few labeled medical scans.
2. Identifying rare species of plants or animals from limited photographs.
3. Intent recognition in NLP for underrepresented languages or domains.
Zero-Shot Learning (ZSL)
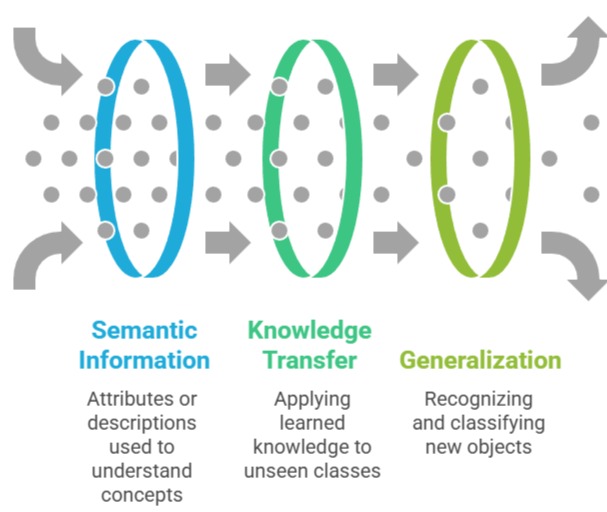
Zero-shot learning (ZSL) extends this concept even further. In ZSL, the model is expected to correctly classify or generate outputs for tasks or classes it has never seen during training.
This is achieved by using auxiliary information such as semantic embeddings, textual descriptions, or attribute vectors that provide context for the unseen classes.
Zero-shot learning enables AI systems to scale efficiently to a wide range of tasks without collecting task-specific annotations, making it suitable for large-scale, dynamic, or evolving applications where labeling every possible class is infeasible.
Advantages
1. Generalization Without Labeled Data
Zero-shot learning allows models to predict classes or outputs for tasks never seen during training.
By leveraging semantic information, textual descriptions, or embeddings, models can infer unseen categories.
This reduces dependency on costly labeled datasets and enables rapid adaptation to new domains, making ZSL highly suitable for dynamic and large-scale AI applications.
2. Scalability Across Tasks
Zero-shot models can scale to a vast number of tasks without additional retraining.
For instance, a model trained on general textual and image data can handle new classification tasks, language translations, or content generation automatically.
This scalability enables efficient deployment in multi-task environments like conversational AI, recommendation systems, or automated tagging.
3. Integration with Pretrained Models
Zero-shot learning works effectively with foundation models, using pre-learned representations and prompt-based techniques.
This synergy allows the model to leverage extensive knowledge from pretraining, achieving good performance even on unseen tasks without task-specific fine-tuning.
Disadvantages
1. Dependence on Auxiliary Information:
The quality of zero-shot performance depends heavily on textual descriptions, semantic embeddings, or prompts.
Ambiguities or poor-quality auxiliary information can lead to misclassification or inaccurate predictions, limiting reliability in high-stakes applications.
2. Limited Fine-Grained Accuracy
While capable of generalization, ZSL may struggle with subtle distinctions between similar classes.
For Example, distinguishing between closely related species or medical conditions may require labeled examples for precise discrimination, which ZSL inherently lacks.
Interpretability Challenges: Understanding why a zero-shot model predicts a certain output is difficult, especially when multiple embeddings or complex pre-trained representations are involved.
This opacity can reduce trust and limit adoption in critical applications.
Examples
1. Recognizing previously unseen animal species using textual descriptions.
2. Translating rare or low-resource languages without labeled parallel corpora.
3. Image classification for novel categories using textual labels in datasets like ImageNet.
Foundations Models
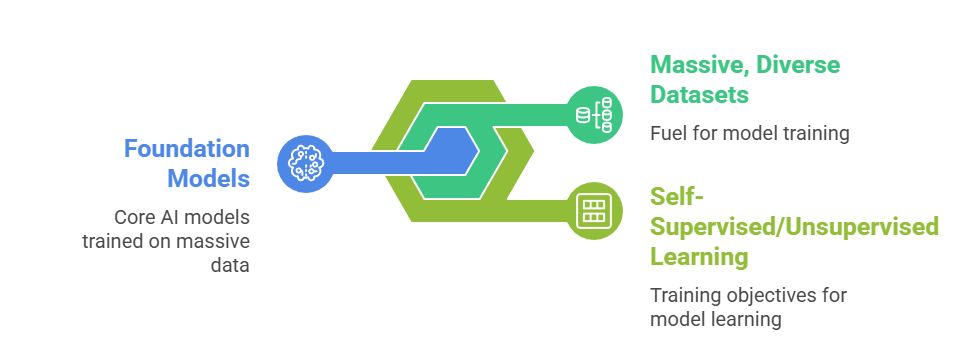 Foundation models are large-scale pre-trained models trained on massive, diverse datasets, often using self-supervised or unsupervised learning objectives.
Foundation models are large-scale pre-trained models trained on massive, diverse datasets, often using self-supervised or unsupervised learning objectives.
These models encode broad knowledge about language, vision, or multimodal data and serve as a base for multiple downstream tasks.
Foundation models, such as GPT, BERT, CLIP, and PaLM, can be adapted to new tasks through fine-tuning or prompt-based learning, offering strong few-shot and zero-shot performance.
Advantages
1. Pretrained Knowledge Across Tasks
Foundation models like GPT, BERT, and CLIP are trained on massive, diverse datasets to learn broad representations of language, vision, or multimodal data.
This allows them to perform multiple downstream tasks efficiently, reducing the need for large task-specific datasets.
They provide a strong knowledge base for few-shot and zero-shot learning.
2. Versatility and Multimodal Capabilities
Foundation models handle text, images, audio, and multimodal inputs, supporting diverse applications.
For Example, CLIP can align images with text, while GPT can generate language outputs across domains.
This versatility enables organizations to deploy a single model for multiple tasks rather than maintaining separate systems.
3. Strong Few-Shot and Zero-Shot Performance
These models can adapt to unseen tasks using few-shot examples or zero-shot prompts.
The pre-trained knowledge ensures meaningful generalization even without extensive fine-tuning, allowing rapid prototyping and deployment of AI systems.
Disadvantages
1. High Computational Costs
Training and deploying foundation models require immense resources, including large-scale GPUs/TPUs and high memory capacity. This limits accessibility for smaller organizations and increases operational expenses.
2. Bias and Ethical Concerns
Foundation models often inherit biases from pretraining datasets, potentially producing harmful, unfair, or offensive outputs. Mitigating these biases is non-trivial and requires careful curation, monitoring, and additional fine-tuning.
3. Limited Interpretability
Understanding decision-making in foundation models is challenging due to their size and complexity. The latent representations and attention mechanisms are difficult to analyze, reducing transparency and accountability.
Examples
1. GPT-4 for zero-shot text summarization or question answering.
2. CLIP for zero-shot image classification using natural language labels.
3. PaLM or LLaMA for cross-lingual understanding and reasoning tasks.

Class Sessions
Sales Campaign

We have a sales campaign on our promoted courses and products. You can purchase 1 products at a discounted price up to 15% discount.