Sequential modeling is a central capability in modern deep learning, driven by the growing need to analyze data that unfolds over time, such as language, audio, sensor signals, and user behavior patterns.
Recurrent Neural Networks (RNNs) were among the earliest architectures designed specifically for this purpose, enabling models to process sequences by maintaining an internal state that evolves with each timestep.
This ability to propagate information across time allows RNN-based systems to capture contextual dependencies that cannot be represented by standard feed-forward networks.
Within this family, three major architectures dominate practical use: vanilla RNNs, Long Short-Term Memory (LSTM) networks, and Gated Recurrent Units (GRUs).
Each represents a progression in how neural networks store, update, and forget information, addressing limitations that arise when sequences grow longer or patterns become more complex.
Vanilla RNNs introduce the basic recurrent mechanism but struggle with long-term dependencies due to gradient instability.
LSTMs address this with a sophisticated gating structure that enables selective memory retention, making them highly effective for tasks involving extended context.
GRUs provide a streamlined gating design that balances efficiency and performance, making them suitable for applications demanding faster computation without significant accuracy loss.
VANILLA RNN
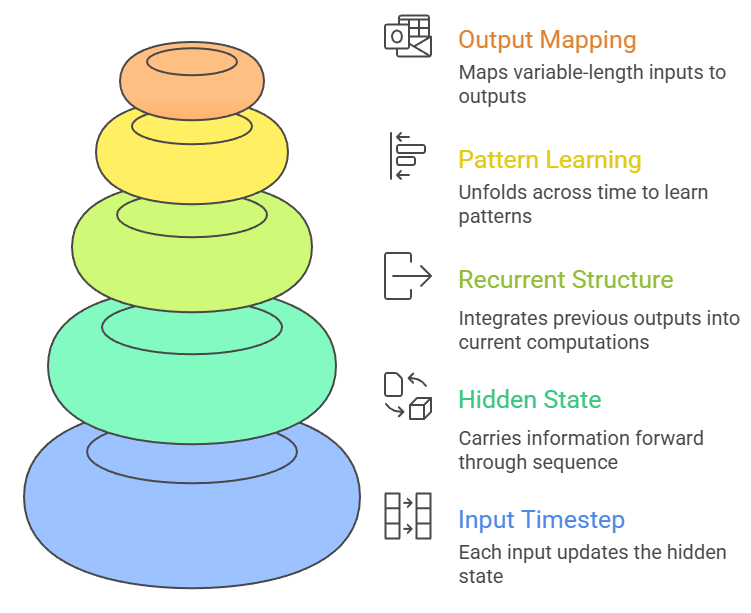
A vanilla Recurrent Neural Network represents the most fundamental form of sequence modeling, where each input timestep updates a hidden state that carries information forward through the sequence.
Its recurrent structure allows the network to build contextual understanding by integrating previous outputs into current computations, making it capable of processing language, time-series signals, and other temporally ordered data.
Vanilla RNNs learn patterns by unfolding across time, enabling them to map variable-length inputs to fixed or variable-length outputs.
However, their simple design makes them vulnerable to gradient vanishing or exploding, severely limiting their capacity to recall information over long spans.
Despite this, they serve as an essential conceptual foundation for more advanced gated architectures and are still used in lightweight tasks where sequences are short and computational overhead must remain minimal.
Advantages
1. Simple and Computationally Lightweight
A vanilla RNN’s architecture is straightforward, involving a single recurrent transformation that updates the hidden state.
This simplicity reduces the number of parameters compared to gated architectures, resulting in faster training and inference when processing short or moderately sized sequences.
Its lightweight nature makes it suitable for embedded devices, rapid experimentation, and academic exploration where interpretability of the fundamental recurrent mechanism is important.
Because fewer operations are required per timestep, vanilla RNNs can be deployed in real-time systems where minimal latency is required and long-term dependencies are not critical.
This computational efficiency allows them to serve as baseline models for benchmarking sequence tasks.
2. Effective for Short-Context Patterns
Vanilla RNNs perform well when the relevant temporal dependencies occur within a limited window, such as short utterances, brief signal bursts, or localized textual patterns.
Their recurrent mechanism efficiently captures transitions between adjacent timesteps, enabling them to model immediate contextual shifts with precision.
Since the model does not need to maintain information across long spans, it avoids many of the stability issues associated with deeper memory requirements.
This makes the architecture ideal for small datasets or tasks where only limited historical context is important for accurate prediction.
3. Natural Fit for Sequential Data Structures
The recurrent design of vanilla RNNs inherently aligns with the structure of sequential data, allowing the model to process inputs one timestep at a time while maintaining a dynamic internal representation.
This makes them suitable for time-series prediction, character-level modeling, and event stream analysis.
Because they naturally unfold through time, vanilla RNNs require minimal architectural adjustments when dealing with different sequence lengths, enhancing their adaptability to various domains.
4. Good for Educational and Conceptual Understanding
Due to their structural simplicity, vanilla RNNs offer an accessible entry point for learning how recurrent networks process sequences.
Their transparent hidden-state update provides insight into temporal representation learning and gradient flow.
Students and practitioners often use vanilla RNNs to build intuition before advancing to more complex architectures like LSTMs or GRUs.
This conceptual clarity makes them foundational to understanding more advanced sequential systems.
5. Flexible Input–Output Mapping Capabilities
Vanilla RNNs support a wide range of mapping configurations, including sequence-to-sequence, sequence-to-label, and label-to-sequence tasks.
This versatility allows them to be applied across diverse applications without the need for major architectural changes.
Whether predicting the next timestep, generating text, or classifying an entire sequence, a vanilla RNN can adjust its computational flow with minimal modifications.
6. Compatible with Online and Streaming Data
Because vanilla RNNs process data incrementally, they are well-suited to applications requiring continuous updates as new information arrives.
This makes them valuable in domains like IoT sensor analysis, financial tick prediction, and real-time monitoring systems.
Their ability to update predictions continuously ensures adaptability to changing patterns and evolving environments.
7. Low Memory Footprint
With fewer parameters and minimal gating complexity, vanilla RNNs consume significantly less memory than gated alternatives.
This enables deployment in constrained environments such as mobile devices or low-power compute systems.
Their compact footprint also makes them suitable for large-scale deployments where memory must be conserved.
Disadvantages
1. Struggles with Long-Term Dependencies
Vanilla RNNs suffer heavily from vanishing gradients, which causes earlier information to fade as sequences grow longer.
This prevents the model from retaining crucial context when dependencies span many timesteps, severely limiting performance on tasks like machine translation or long-form text generation.
Even with careful initialization, the network struggles to maintain stable gradients, resulting in weak representation of distant relationships.
2. Vulnerable to Gradient Exploding
In addition to vanishing gradients, vanilla RNNs can experience gradient exploding, where updates become excessively large, destabilizing training.
This leads to oscillating loss values, diverging weights, and unreliable optimization behavior.
While gradient clipping mitigates the issue, it does not fully eliminate instability, making training difficult for long sequences.
3. Limited Capacity for Complex Temporal Structures
The simple recurrence mechanism cannot adequately capture intricate temporal patterns that require selective retention and controlled forgetting.
Without gating mechanisms, the model treats all past information with equal weight, resulting in poor representation of nuanced sequential concepts.
This restricts the use of vanilla RNNs for advanced tasks requiring deep contextual understanding.
4. Inefficient for Long Sequences
As sequences grow longer, training becomes inefficient because the network must unroll through many timesteps.
This increases computational load and slows convergence, particularly when gradients degrade or explode.
Long-sequence unrolling also increases susceptibility to numerical instability.
5. Poor Performance Compared to Modern Architectures
In many real-world applications, vanilla RNNs are outperformed by LSTMs, GRUs, and attention-based models, which provide significantly better retention and more stable training dynamics. As a result, vanilla RNNs are rarely used in production pipelines.
6. Difficulty Handling Irregular or Missing Data
Vanilla RNNs assume evenly spaced timesteps and well-defined sequences.
When data is irregular or contains gaps, performance degrades substantially. Specialized preprocessing or modified architectures are often required to compensate.
7. Limited Parallelization During Training
Because vanilla RNNs process data sequentially, they cannot benefit from the same level of parallelism available to CNNs or transformers.
This results in longer training times and reduced scalability for large datasets.
LONG SHORT-TERM MEMORY (LSTM)
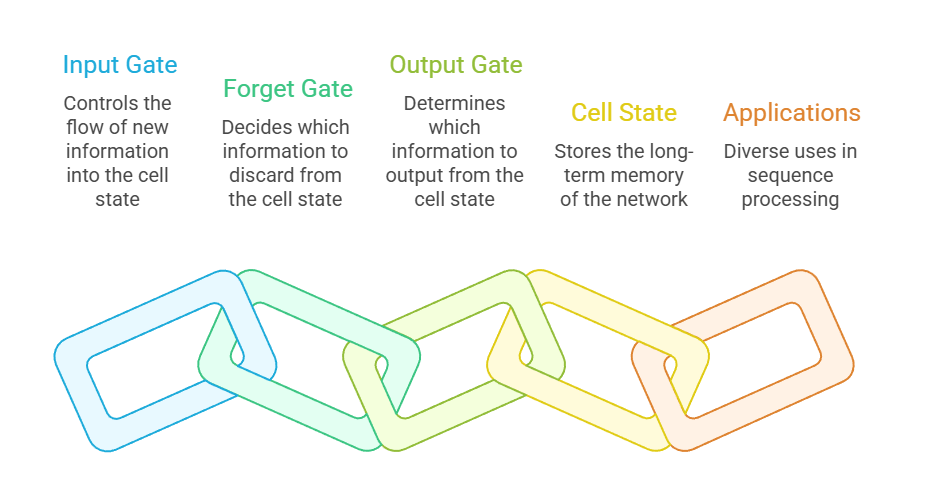 Long Short-Term Memory networks were introduced to overcome the inability of vanilla RNNs to retain information over long sequences, particularly in tasks that rely heavily on distant contextual dependencies.
Long Short-Term Memory networks were introduced to overcome the inability of vanilla RNNs to retain information over long sequences, particularly in tasks that rely heavily on distant contextual dependencies.
Their internal architecture, composed of input, forget, and output gates, allows them to selectively store, update, and erase information as it flows through time, making them exceptionally effective at maintaining memory across hundreds of steps.
LSTMs have become foundational in numerous sequence-processing applications, including language modeling, speech recognition, medical time-series prediction, and even early transformer alternatives.
Their structured gating mechanism provides more stable gradient flow, preventing the vanishing and exploding gradient issues that hinder traditional RNNs. Although more computationally demanding,
LSTMs remain widely used due to their reliability, interpretability of gating behavior, and ability to handle real-world sequential complexity.
They paved the way for modern architectures while still serving as a robust sequence model in many practical environments.
Advantages
1. Superior Long-Term Dependency Handling
LSTMs excel at learning relationships across long sequences because their gated architecture enables them to preserve information far more effectively than vanilla RNNs.
Unlike traditional recurrence, which repeatedly overwrites hidden states, LSTMs regulate what stays and what is discarded, allowing them to maintain essential context across hundreds of steps.
This ability is crucial for tasks such as paragraph-level text generation or multi-stage reasoning in time-series analysis, where distant events strongly influence current predictions.
Their memory cells function like controlled storage units, enabling the model to form structured and persistent representations.
As a result, LSTMs remain exceptionally reliable in domains requiring stable long-range comprehension.
2. Mitigation of Vanishing Gradient Problems
The unique internal structure of LSTMs helps preserve gradient magnitude during backpropagation, preventing the rapid decay that typically affects vanilla RNNs.
This stability allows models to learn complex temporal structures without losing gradient signal as time steps increase.
Because the cell state can transport information with minimal alteration across large temporal distances, optimization becomes more efficient and converges more consistently.
This property reduces the need for extensive architectural hacks or specialized initialization schemes.
Consequently, LSTMs became a landmark solution enabling deep sequence modeling before the rise of attention mechanisms.
3. Robustness Across Noisy and Irregular Sequences
LSTMs maintain reliable performance even when sequences contain noise, irregular spacing, missing values, or non-uniform patterns, making them suitable for real-world signals such as medical sensor data or stock market fluctuations.
Their gating system naturally filters out irrelevant information while amplifying meaningful temporal cues, resulting in stable predictions under imperfect conditions.
This robustness enables deployment in mission-critical fields where noise cannot be avoided.
Over time, LSTMs learn to generalize across inconsistencies rather than overfitting to noise artifacts, giving them an advantage over simpler models.
4. Flexibility Across Multiple Modalities
LSTMs are capable of learning temporal dynamics in textual, acoustic, visual, and behavioral data, making them a versatile solution for multidisciplinary AI tasks.
Their architecture does not rely on assumptions about the nature of the sequence, allowing them to model speech waveforms, character sequences, sensor logs, neural recordings, or even video frames.
This adaptability makes them a preferred foundation for multi-modal pipelines, especially when cross-domain relationships must be captured.
Their generalized structure enables smooth integration into many legacy systems that predate attention-based architectures.
5. Strong Performance on Small and Medium Datasets
Unlike transformer models that require massive corpora to learn effectively, LSTMs demonstrate strong results even when training data is limited.
Their inductive bias, encoded through the gating design, helps them learn logical temporal patterns without relying on extremely large datasets.
This makes LSTMs ideal for applications in specialized scientific domains, where collecting extensive data is difficult or expensive.
Their stability under data scarcity also makes them attractive for low-resource languages, niche financial markets, and rare medical conditions.
6. Sequential Memory Interpretation and Debugging
LSTMs offer interpretability advantages because their gate activations provide clues about how information is stored or discarded during sequence processing.
Researchers and engineers can analyze gate patterns to understand which parts of a sequence influence the output and which are deliberately forgotten.
This transparency is valuable in healthcare, finance, and policy systems where explanations are essential for regulatory compliance.
Such interpretability allows LSTMs to serve as both predictive models and analytical tools to uncover hidden temporal structures.
7. Proven Stability in Production Environments
LSTMs have been extensively tested in real-world industrial systems, making them a stable, predictable option for long-term deployments.
Their behavior under scaling, distribution, latency constraints, and noisy input conditions is well documented, reducing uncertainty for engineering teams.
They have powered major speech recognition engines, translation services, and forecasting systems for years, establishing a strong evidence base for their reliability.
This maturity enables teams to optimize and maintain LSTM systems without the experimental overhead that more recent architectures often require.
Disadvantages
1. High Computational and Memory Cost
LSTMs involve a large number of parameters due to their multiple gates, leading to higher training and inference costs compared to simpler recurrent units like GRUs.
This computational burden can slow experimentation cycles, reduce throughput, and increase hardware requirements, especially when processing long sequences.
In embedded or real-time systems, these costs can hinder deployment unless models are heavily optimized. As a result, LSTMs may be impractical when latency or energy consumption is a primary constraint.
2. Difficulty Scaling to Very Long Sequences
Although LSTMs handle moderate long-term dependencies well, they still struggle with extremely long sequences such as entire books or long audio streams, where memory bottlenecks and diminishing gradient flow accumulate over time.
These limitations become more pronounced as sequence length grows into thousands of steps, making attention-based architectures more effective for large-scale contexts.
Consequently, LSTMs can fail to maintain coherent memory across extremely extended inputs.
3. Slow Training Compared to Modern Architectures
The sequential nature of LSTMs forces computations to occur step-by-step rather than in parallel, significantly slowing training time on long sequences.
Unlike transformers that capitalize on parallel processing, LSTMs’ dependence on previous time steps limits hardware acceleration capabilities.
This bottleneck reduces scalability, especially on large datasets requiring many epochs of training.
4. Complex Internal Dynamics
Although LSTMs are more interpretable than some deep models, their internal gating system can still behave unpredictably, making optimization sensitive to hyperparameters such as learning rate, dropout, and initialization.
Small changes in configuration can lead to significant performance fluctuations.
This complexity increases development time and demands extensive experimentation.
5. Risk of Overfitting on Small Datasets
While LSTMs perform well with limited data, their high parameter count can lead to overfitting if regularization strategies are not carefully applied.
Without dropout, gradient clipping, and strong validation strategies, the model can memorize training sequences instead of learning general patterns.
This is a significant concern in fields where labeled data is scarce or expensive.
6. Limited Ability to Capture Global Relationships
LSTMs inherently process data in a linear forward direction, making it difficult for them to capture global context or interactions between distant sequence elements.
This becomes problematic in tasks where long-range relationships determine meaning, such as document summarization or multi-speaker dialogues.
Their reliance on temporal progression restricts the holistic view that attention mechanisms provide.
7. Often Outperformed by Attention-Based Models
Transformers and attention mechanisms have surpassed LSTMs in most large-scale tasks, offering better performance, faster training, and greater parallelization.
While LSTMs remain useful in constrained environments, their comparative performance disadvantages reduce their relevance in cutting-edge research.
As a result, many modern NLP and speech systems have transitioned to attention-dominant architectures.
GRU (Gated Recurrent Unit)
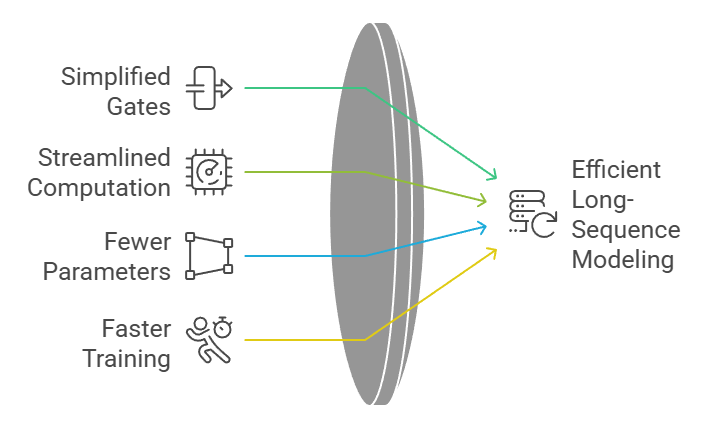
The Gated Recurrent Unit (GRU) is an evolved recurrent architecture designed to simplify the internal mechanisms of LSTMs while preserving strong long-sequence modeling capabilities.
It merges the forget and input gates into a single update gate, streamlining computation without compromising the network’s ability to capture complex temporal relationships.
This compact structure results in faster training, fewer parameters, and improved generalization when dealing with medium-scale datasets or tasks requiring efficient deployment.
GRUs maintain a balance between computational economy and expressive power by allowing gradient flow more effectively than traditional RNNs, reducing issues such as gradient diminishing across long sequences.
Their adaptive gating enables the model to retain or discard information dynamically, ensuring that relevant patterns persist through time.
Because of their lighter architecture, GRUs are often used in situations where rapid experimentation, smaller memory footprints, and lower latency are essential.
Their combination of simplicity and performance makes them a strong choice for industrial applications and real-time systems.
Advantages
1. Reduced Architectural Complexity
GRUs remove unnecessary structural components by merging the LSTM’s input and forget mechanisms into a single update gate, reducing parameter count and improving the interpretability of their internal behavior.
The streamlined architecture leads to quicker convergence during training and decreases computational burdens, which is valuable for lightweight devices and environments with restricted processing capabilities.
Unlike deeper gated models, GRUs can operate effectively without extensive hyperparameter tuning, enabling faster deployment in production systems.
This structural simplicity increases maintainability, making it easier for teams to debug and update sequence models consistently.
The reduced complexity also contributes to smooth gradient flow, helping GRUs sustain representation quality over long sequences.
2. Faster Training and Lower Memory Demand
The smaller number of parameters in GRUs allows them to train significantly faster than LSTMs while requiring less memory during both forward and backward propagation cycles.
This efficiency is particularly beneficial when working with large volumes of sequential data, where training time becomes a major constraint. GRUs scale well on hardware-limited platforms such as mobile processors or edge devices, enabling wider adoption in real-time applications like voice input or predictive maintenance.
Reduced memory usage also helps maintain stability when running long experiments or parallel models.
This makes GRUs ideal for situations where quick iteration is needed without sacrificing sequence modeling effectiveness.
3. Strong Performance on Medium-Sized Datasets
In many practical scenarios, GRUs outperform LSTMs when working with datasets that are not large enough to fully leverage the expressive power of more complex gating mechanisms.
Their more compact structure reduces the likelihood of overfitting while maintaining the ability to capture long-term dependencies.
Because GRUs generalize well even with limited data availability, they are suitable for commercial environments where large-scale labeled datasets are expensive or difficult to obtain.
This advantage enhances their value in personalized recommendation systems, time-series forecasting tasks, and moderate-complexity language applications.
4. Effective Gradient Flow Through Sequences
GRUs mitigate vanishing gradient issues by regulating information retention and update dynamics through carefully designed gate mechanisms.
This helps maintain signal strength even when dealing with extended temporal patterns, enabling GRUs to track long-distance relationships that vanilla RNNs struggle with.
Because of this stable gradient behavior, GRUs sustain prediction quality across tasks like energy consumption forecasting, user engagement modeling, or health-sensor signal analysis.
The improved flow increases consistency across training epochs and reduces oscillation in loss curves, which contributes to more reliable optimization outcomes.
5. Competitive Accuracy with Fewer Parameters
Despite having a more compact structure than LSTMs, GRUs achieve comparable performance across many sequence modeling benchmarks, including speech recognition, text processing, and sensor-based predictive tasks.
They efficiently encode contextual information without the need for extensive gate interactions or complex state transitions.
This ability to produce strong results using fewer core units reduces the computational footprint substantially, making GRUs highly attractive for resource-constrained environments.
Their parameter efficiency also allows larger batch sizes, improving throughput without demanding additional hardware investment.
6. Enhanced Suitability for Real-Time Applications
GRUs exhibit reduced inference latency due to their streamlined architecture, making them ideal for systems that require immediate decision-making or continuous monitoring.
Applications such as voice assistants, industrial IoT, and fraud detection benefit from GRUs’ rapid processing and minimal lag.
Their low computational overhead allows them to maintain accurate temporal predictions while operating under strict timing constraints.
This responsiveness enhances user experience and system reliability in any domain requiring instantaneous output from sequential data streams.
7. High Robustness in Noisy or Irregular Sequences
GRUs’ adaptive update mechanism helps the network determine how much information from noisy or irregular inputs should be preserved or discarded, improving performance in chaotic real-world environments.
This gating behavior protects the model from overreacting to random fluctuations while still maintaining sensitivity to meaningful temporal changes.
In applications involving financial markets, environmental sensor readings, or behavioral analytics, this robustness is essential for ensuring stable predictions.
GRUs can maintain temporal coherence even when exposed to imperfect, incomplete, or partially corrupted signals.
Disadvantages
1. Lack of Separate Memory Cell
Unlike LSTMs, GRUs do not maintain an independent memory cell, which can reduce their ability to manage highly complex long-term dependencies.
Tasks that require fine-grained memory manipulation—such as long-document summarization or multi-stage reasoning—may benefit more from LSTMs’ broader gating structure.
As a result, GRUs sometimes fall short in extended narrative contexts or hierarchical temporal structures.
2. Less Effective for Extremely Long Sequences
While GRUs improve upon vanilla RNNs, they still may struggle with sequences requiring very deep temporal recall over hundreds of time steps.
The simplified gating mechanism limits how precisely information retention is controlled, especially in highly layered or multi-timescale contexts.
This causes performance drop-offs in tasks such as large-scale language modeling or extended audio processing.
3. Not Always Superior to LSTMs in Complex Data Distributions
In tasks involving intricate temporal structure or heterogeneous feature patterns, LSTMs outperform GRUs due to their more expressive gating framework.
GRUs’ reduced flexibility can lead to weaker modeling of nuanced behaviors or long-range contextual transformations.
This means that GRUs are sometimes less suitable in multidisciplinary sequence tasks requiring multi-stage memory management.
4. Less Popular in Research Benchmarks
Most cutting-edge sequence modeling research—especially in NLP—has historically favored LSTMs or transformer-based architectures, resulting in fewer GRU-centric advancements.
This creates a smaller ecosystem of optimization techniques, pretrained checkpoints, and architecture variations.
The limited research focus sometimes restricts GRUs from achieving state-of-the-art results in academic benchmarks.
5. Sensitivity to Hyperparameter Settings
Although simpler than LSTMs, GRUs still require careful tuning of learning rate, initialization strategy, and layer depth to prevent instability during training.
Their compact design can sometimes amplify errors when hyperparameters are misconfigured, leading to erratic convergence behavior.
This increases the time needed to experiment when deploying them in specialized industrial systems.
6. Reduced Interpretability of Gate Dynamics
While GRUs simplify gating structure, they also obscure memory handling because the update gate jointly controls what is kept and forgotten.
This merging of responsibilities makes the underlying decisions less transparent, limiting interpretability in high-risk or regulated environments.
Stakeholders may find it challenging to understand why specific time-based predictions were generated.
7. Inconsistent Performance Across Domains
GRUs perform exceptionally well in some domains but show unpredictable results in others, especially tasks requiring multi-resolution temporal reasoning or heavily contextual prediction.
Their effectiveness varies more widely than LSTMs across diverse datasets, creating uncertainty when selecting architectures for mission-critical deployment.
