Advanced CNN architectures aim to improve computational efficiency, reduce parameter count, and enhance performance on large-scale image recognition tasks. Two notable innovations in this area are depthwise separable convolutions and EfficientNet.
Depthwise separable convolutions decompose standard convolutions into depthwise and pointwise operations, drastically reducing computational cost while retaining feature extraction quality.
This technique has become a cornerstone in lightweight CNN architectures, particularly for mobile and embedded applications.
On the other hand, EfficientNet introduces a compound scaling method, which simultaneously scales depth, width, and resolution in a balanced manner, achieving state-of-the-art accuracy with fewer parameters.
By carefully optimizing network dimensions, EfficientNet demonstrates that scaling strategies, rather than just adding layers, are key to efficiency.
Both methods emphasize efficiency without sacrificing performance, addressing the growing need for resource-aware models in real-world applications
Depthwise Separable Convolutions
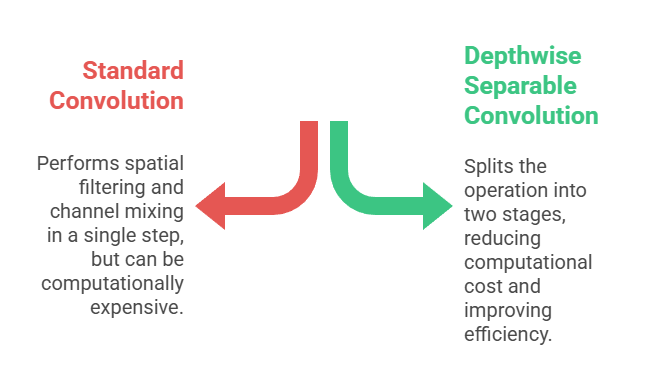
Depthwise separable convolutions are an efficient alternative to traditional convolution operations used in CNNs.
Unlike standard convolutions, which perform spatial filtering and channel mixing in a single step, depthwise separable convolutions split the operation into two stages
Depthwise convolution, which applies a single filter per input channel, and pointwise convolution, which uses 1x1 filters to combine outputs across channels.
This decomposition drastically reduces computational complexity and the number of parameters, while maintaining similar representational power.
Popularized by architectures like MobileNet, depthwise separable convolutions are widely used in mobile and real-time applications where hardware constraints are critical.
They maintain strong feature extraction capabilities while enabling CNNs to run efficiently on resource-limited devices.
Advantages
1. Significant Reduction in Computation and Parameters
By separating spatial and channel-wise operations, depthwise separable convolutions drastically reduce the number of parameters compared to standard convolutions.
This reduction lowers memory usage and speeds up both training and inference, making it feasible to deploy CNNs on devices with limited hardware.
Despite the efficiency gains, the operation still captures essential spatial and channel relationships effectively, making it suitable for real-world applications.
2. Efficient Feature Learning
These convolutions maintain high-quality feature extraction by learning spatial features in the depthwise stage and combining channel information in the pointwise stage.
This separation allows the network to focus on localized spatial patterns without redundant computations.
The resulting representations are effective for classification, detection, and segmentation tasks, providing a good trade-off between speed and accuracy.
3. Ideal for Mobile and Embedded Applications
Depthwise separable convolutions are used extensively in lightweight architectures such as MobileNet, making them perfect for smartphones, drones, or IoT devices.
They enable real-time processing of high-resolution images without requiring high-end GPUs, which is crucial for edge AI and on-device deep learning solutions.
4. Improved Training Efficiency
Reduced parameter count and computational demand translate to faster training times.
Networks can be trained with smaller batch sizes and limited hardware while still achieving competitive accuracy.
This efficiency accelerates experimentation and model iteration, particularly for researchers working with constrained resources.
5. Scalability for Deeper Networks
By lowering computational cost per layer, depthwise separable convolutions allow the construction of deeper networks without exponentially increasing parameters.
This capability enables more expressive models while remaining computationally manageable, supporting modern architectures that prioritize depth and efficiency.
6. Flexibility in Architecture Design
These convolutions can be incorporated into various CNN architectures as modular components, allowing designers to build hybrid networks that combine standard and separable layers based on task requirements.
This adaptability enhances the applicability across different computer vision problems.
7. Robust Performance
Despite the parameter reduction, depthwise separable convolutions maintain competitive accuracy on benchmark datasets.
When combined with techniques like batch normalization and residual connections, they provide stable training and reliable generalization, making them a practical choice for modern CNNs.
Disadvantages
1. Reduced Representational Power Compared to Standard Convolutions
Although efficient, depthwise separable convolutions may underperform in extremely complex tasks due to their simplified channel mixing.
In cases where detailed interactions between channels are crucial, performance may slightly degrade compared to full convolutions.
2. Sensitivity to Hyperparameter Tuning
Selecting optimal kernel sizes, stride, and channel dimensions is critical to maintain accuracy.
Improper choices can lead to insufficient feature extraction, especially in networks designed for high-resolution or complex images.
3. Implementation Complexity
Some frameworks may require careful coding or optimization to achieve the computational benefits.
Naively implementing separable convolutions may not yield significant speedups without hardware-aware adjustments.
4. Limited Use in Early Layers
Depthwise separable convolutions are sometimes less effective in initial layers where strong spatial-channel interactions are needed.
Designers may prefer standard convolutions in early stages for better feature capture, which slightly complicates architecture design.
5. Dependency on Efficient Hardware Libraries
Achieving maximum speed improvements often relies on hardware-optimized libraries or GPU support.
On unsupported devices, the efficiency gains may be limited.
6. Training Stability
Networks with many depthwise separable layers can require careful initialization and regularization to ensure stable convergence, especially when scaling to very deep architectures.
7. Not Universally Applicable
While ideal for mobile and edge applications, depthwise separable convolutions are not always necessary in high-performance server-based networks, where full convolutions may provide marginally better accuracy with sufficient resources.
EfficientNet
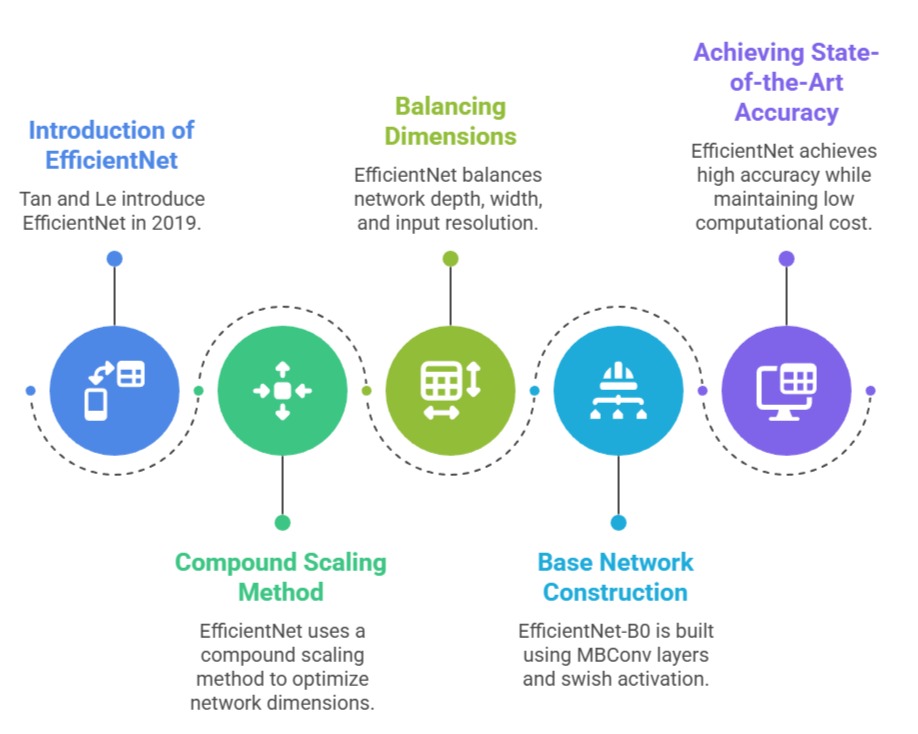 EfficientNet, introduced by Tan and Le in 2019, represents a breakthrough in CNN design by systematically optimizing network depth, width, and input resolution using a compound scaling method.
EfficientNet, introduced by Tan and Le in 2019, represents a breakthrough in CNN design by systematically optimizing network depth, width, and input resolution using a compound scaling method.
Unlike previous architectures that scaled only one dimension, EfficientNet balances all three aspects to achieve state-of-the-art accuracy while keeping computational cost low.
The base network, EfficientNet-B0, is built using mobile inverted bottleneck MBConv layers and swish activation, combining efficiency with high feature representation capability.
By applying compound scaling, EfficientNet variants (B1–B7) scale systematically according to available computational resources, maintaining accuracy improvements without excessive parameter growth.
This architecture demonstrates that thoughtful scaling, rather than arbitrarily increasing depth, is crucial for efficient CNN performance.
EfficientNet models are now widely adopted for image classification, object detection, and even medical imaging tasks, offering superior accuracy per FLOP compared to older architectures.
Advantages
1. Balanced Scaling for High Efficiency
EfficientNet’s compound scaling method optimizes depth, width, and resolution simultaneously, achieving high accuracy with fewer parameters and FLOPs.
This balance ensures that all layers are effectively utilized, avoiding over- or under-scaling that can compromise performance.
2. State-of-the-Art Accuracy
EfficientNet achieves superior performance on benchmark datasets like ImageNet while using significantly fewer parameters than traditional architectures.
Its combination of MBConv layers, swish activations, and optimized scaling ensures that the network can capture complex hierarchical features efficiently.
3. Resource Efficiency: By focusing on FLOP-efficient design, EfficientNet is suitable for deployment in resource-constrained environments, including cloud services, mobile devices, and embedded systems.
It provides a strong trade-off between computational cost, memory usage, and accuracy.
4. Scalable Variants for Flexibility
EfficientNet offers multiple variants, from B0 to B7, allowing designers to choose a model that fits specific computational budgets.
This flexibility makes it practical for diverse applications, from low-power mobile inference to high-performance server deployments.
5. Strong Transfer Learning Capabilities
EfficientNet models pretrained on large datasets serve as effective feature extractors for transfer learning.
They are highly effective in downstream tasks such as object detection, semantic segmentation, and fine-grained classification, often outperforming older architectures with fewer resources.
6. Improved Training Efficiency
EfficientNet requires fewer parameters and lower FLOPs than equivalent-performing networks, which speeds up training and reduces energy consumption.
This efficiency supports iterative experimentation and hyperparameter tuning on limited hardware.
7. Modular Design for Adaptability
EfficientNet’s building blocks can be integrated into custom architectures or combined with attention mechanisms for specialized tasks.
This modularity makes it a versatile foundation for advanced CNN research and deployment.
Disadvantages
1. Complex Architecture Design
EfficientNet’s use of MBConv blocks, swish activations, and compound scaling adds complexity compared to simpler networks like AlexNet or VGG.
Understanding and modifying the architecture requires deep knowledge of CNN design principles.
2. Hyperparameter Sensitivity
Optimal performance depends on careful selection of scaling coefficients, input resolution, and regularization techniques.
Misconfigured models can lead to degraded accuracy or inefficient computation.
3. Resource-Intensive at Higher Variants
While B0 is lightweight, larger variants like B6 or B7 require significant memory and GPU resources, limiting deployment on edge devices without optimization.
4. Longer Training Time for Large Variants
EfficientNet-B6/B7 can require extensive computational time to train from scratch, especially on high-resolution datasets, making experimentation slower than with smaller networks.
5. Dependency on Modern Frameworks
EfficientNet benefits from optimized libraries for MBConv operations and swish activation. Without these, computational gains may be reduced.
6. Limited Interpretability
The use of complex MBConv layers and compound scaling makes the network less intuitive, which can be a challenge for educational purposes or network analysis.
7. Specialized Use Case
EfficientNet excels in image classification, but may require additional adaptation for tasks like segmentation or detection, whereas simpler CNNs might be easier to modify for diverse tasks.
Real-World Applications & Case Studies
1. Depthwise Separable Convolutions
Mobile Image Classification (Smartphones & Edge AI)
Depthwise separable convolutions are widely deployed in smartphone vision systems where computational efficiency is critical.
MobileNet, the architecture built on these operations, powers apps that perform real-time image classification, gesture recognition, and object identification without needing cloud support.
This allows phones to analyze images instantly while preserving battery life and reducing latency.
In real-world mobile applications like Google Lens, AR filters, and barcode scanning, depthwise separable convolutions ensure fast inference even on mid-range devices.
The reduced parameter count makes them perfect for edge AI where storage and power are limited.
Face Detection in Social Media Apps
Many social media platforms such as Instagram, Snapchat, and TikTok rely on lightweight CNNs built using depthwise separable convolutions to detect facial landmarks in real time.
These operations help track facial expressions, overlay filters, apply AR masks, and analyze facial movements with high accuracy and minimal delay.
Since millions of users access these features simultaneously, the computational efficiency is essential for providing smooth and responsive user experiences.
Even low-end smartphones can run these models efficiently, making face detection universally accessible.
Autonomous Drones & Robotics
Drones used for surveillance, agriculture, delivery, and search-and-rescue rely on lightweight CNNs for onboard vision.
Since drones have limited battery capacity and processing power, depthwise separable convolutions enable them to perform real-time object tracking, obstacle avoidance, and navigation.
These efficient models reduce the load on hardware while providing sufficiently detailed feature extraction for safe autonomous movement.
In robotics, similar architectures help robots recognize objects and interact with their environment without relying on cloud computing.
Medical Imaging on Portable Devices
Portable medical devices such as handheld ultrasound machines use CNNs built with depthwise separable convolutions to perform on-device diagnostic analysis.
These models help detect anomalies in X-rays, classify ultrasound images, and support rapid screening in rural or low-resource settings.
The lightweight nature of these networks ensures that the devices remain portable while still providing clinically useful results.
This democratizes diagnostic tools and allows medical professionals in remote areas to receive AI-assisted insights without advanced computing infrastructure.
Smart Home & IoT Vision Applications
Smart doorbells, home security cameras, and IoT sensors rely on energy-efficient neural networks based on depthwise separable convolutions.
These devices must run continuously while consuming minimal power, making lightweight models ideal.
CNNs in these systems detect motion, recognize faces, and differentiate between humans, pets, and objects to trigger alerts.
Because the models work locally, they enhance privacy by avoiding unnecessary cloud communication.
2. EfficientNet
Medical Imaging: Tumor Classification and Diagnosis
EfficientNet has been widely used in medical imaging due to its high accuracy and reduced computational demand. Hospitals and research centers employ EfficientNet for detecting tumors in MRI and CT scans, identifying diabetic retinopathy in retinal images, and classifying lung diseases from chest X-rays.
In many studies, EfficientNet outperformed traditional CNNs while using fewer parameters, reducing inference time while maintaining diagnostic accuracy.
Its strong transfer learning capabilities allow researchers to fine-tune pretrained models on small medical datasets, achieving clinical-grade results.
This makes EfficientNet valuable in healthcare facilities with limited computing infrastructure.
E-commerce Product Categorization
Large e-commerce companies use EfficientNet to automatically classify products uploaded by sellers.
With millions of listings appearing daily, EfficientNet helps identify product categories, detect counterfeit items, and sort images into correct taxonomy with minimal human intervention.
Its optimized scaling ensures accuracy across diverse image qualities—from high-resolution product shots to user-uploaded images with noise and clutter. The reduced inference cost enables real-time processing at scale without excessive computational resources.
Agricultural Crop Monitoring & Disease Detection
EfficientNet is used in precision agriculture to analyze crop images from drones or mobile apps. By fine-tuning pretrained models, systems can detect leaf diseases, classify crop types, estimate yield, and identify nutrient deficiencies.
The architecture’s high accuracy ensures reliable detection even under varying lighting and environmental conditions.
Farmers benefit from early warnings about infestations or diseases, reducing economic losses. EfficientNet’s efficiency allows deployment on mobile devices for field-side diagnosis without requiring internet connectivity.
Retail Surveillance and Customer Analytics
Retail chains use EfficientNet-based models for analyzing in-store CCTV footage. These models help detect customer movement patterns, count footfall, and identify product engagement zones.
EfficientNet detects human presence, tracks behavior, and recognizes patterns with high accuracy while using manageable computational resources on in-store servers.
This improves store layouts, enhances inventory placement decisions, and supports loss prevention systems.
The balance between accuracy and resource usage makes it practical for large deployments.

Class Sessions
Sales Campaign

We have a sales campaign on our promoted courses and products. You can purchase 1 products at a discounted price up to 15% discount.