Self-supervised learning (SSL) has emerged as a transformative approach in deep learning, particularly when combined with Transformer architectures.
Unlike traditional supervised learning, which requires large amounts of labeled data, self-supervised learning leverages the inherent structure of unlabeled data to generate supervisory signals.
This enables models to pretrain on vast corpora without manual annotation, learning rich contextual representations that can be fine-tuned for downstream tasks.
Transformers, with their attention-based design, are particularly suited for SSL because they can capture global dependencies and complex patterns across sequences efficiently.
Models like BERT (Bidirectional Encoder Representations from Transformers) and GPT (Generative Pretrained Transformer) exemplify the power of self-supervised pretraining: BERT uses masked language modeling to learn bidirectional context, while GPT employs autoregressive learning to generate coherent sequences of text.
These strategies allow models to understand syntax, semantics, and even subtle contextual nuances without explicit supervision.
The combination of SSL and Transformers has dramatically advanced the state-of-the-art in natural language processing (NLP), powering applications such as question answering, text summarization, sentiment analysis, and conversational AI.
By learning general-purpose representations during pretraining, models require less labeled data during fine-tuning, increasing efficiency and reducing reliance on costly annotations.
BERT (Bidirectional Encoder Representations from Transformers)
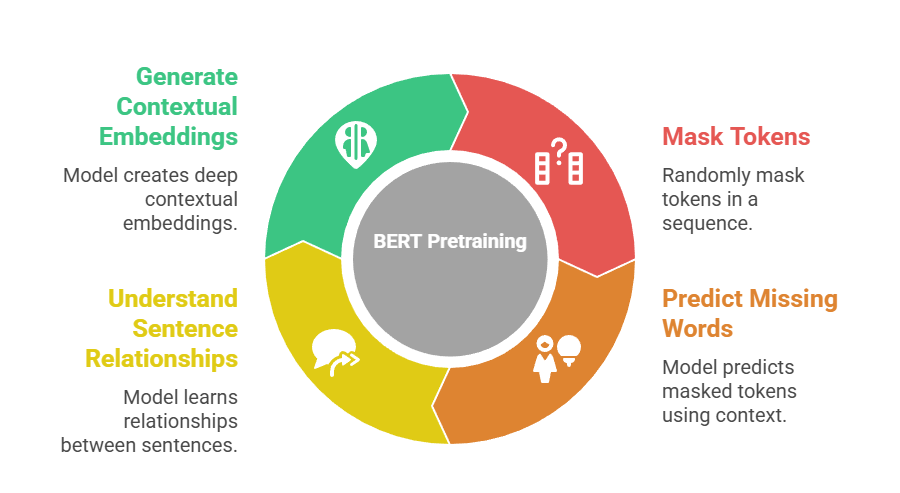
BERT is a Transformer-based model that leverages bidirectional context to generate deep contextual embeddings for each token in a sequence.
Its primary pretraining objective is masked language modeling, where a fraction of tokens is masked and the model predicts the missing words based on surrounding context.
Additionally, BERT uses the Next Sentence Prediction task to understand relationships between sentences.
The bidirectional nature allows it to capture dependencies from both left and right contexts, unlike traditional autoregressive models.
BERT’s pretrained representations can then be fine-tuned for tasks such as classification, question answering, and named entity recognition, providing state-of-the-art performance across many NLP benchmarks.
Advantages
1. Deep Contextual Understanding
BERT’s bidirectional attention enables it to capture nuanced relationships between words in a sentence, allowing for a richer understanding of context than unidirectional models.
This capability improves performance in tasks requiring comprehension of sentence meaning, such as sentiment analysis or question answering.
By considering both preceding and succeeding words, BERT can resolve ambiguities and model polysemous words effectively.
2. Transfer Learning Efficiency
Once pretrained, BERT can be fine-tuned on a wide range of downstream tasks with relatively small labeled datasets.
This transfer learning reduces the need for extensive task-specific data and accelerates model development, making high-performance NLP accessible even to teams with limited annotation resources.
3. Handles Complex NLP Tasks
BERT is capable of solving sophisticated problems like semantic similarity, reading comprehension, and inference.
Its deep bidirectional representations allow it to understand subtle contextual cues, enabling better reasoning and decision-making in natural language tasks.
4. Robust Across Domains
Pretrained on large corpora, BERT’s representations generalize well across domains, including biomedical texts, legal documents, and social media data.
Fine-tuning for domain-specific tasks further enhances its performance, making it highly adaptable.
5. Strong Benchmark Performance
BERT consistently achieves top results on standard NLP benchmarks such as GLUE, SQuAD, and MNLI.
Its architecture allows for precise token-level predictions and sentence-level understanding, driving improvements across multiple tasks simultaneously.
6. Supports Multilingual Applications
Multilingual versions of BERT (mBERT) enable cross-lingual transfer learning, facilitating NLP development in low-resource languages.
This expands its utility globally, addressing data scarcity in non-English contexts.
7. Facilitates Interpretability
Attention mechanisms in BERT provide insights into which tokens influenced predictions, aiding in understanding model reasoning and debugging.
Visualization of attention scores helps identify model biases or focus areas in complex sequences.
Disadvantages
1. Computationally Intensive
Pretraining BERT requires enormous computing resources and large memory capacity, which limits accessibility for smaller organizations or research teams without specialized hardware.
2. High Inference Latency
Due to its deep architecture and large number of parameters, BERT can be slower during inference, making deployment in real-time applications challenging without model compression or optimization.
3. Fixed Input Length Limitations
BERT imposes a maximum token sequence length, restricting performance on tasks requiring very long context comprehension unless specialized models like Longformer are used.
4. Large Model Size
The base BERT model contains hundreds of millions of parameters, increasing storage requirements and energy consumption, which can be prohibitive for edge deployment.
5. Susceptible to Domain Shift
BERT pretrained on general corpora may underperform in highly specialized domains without adequate domain-specific fine-tuning.
6. Masking Prediction Limitation
The masked language modeling task does not naturally handle generative tasks; BERT cannot generate coherent text sequences like autoregressive models without modification.
7. Potential Bias Learning
BERT can inherit biases present in its pretraining data, which can propagate into downstream applications if not carefully mitigated.
Examples
1. Question Answering: Extracting precise answers from paragraphs.
2. Text Classification: Sentiment analysis, spam detection, or topic classification.
3. Named Entity Recognition: Identifying people, organizations, locations in text.
4. Semantic Similarity: Paraphrase detection or duplicate question identification.
5. Cross-Lingual NLP: Machine translation and multilingual understanding tasks.
GPT (Generative Pretrained Transformer)
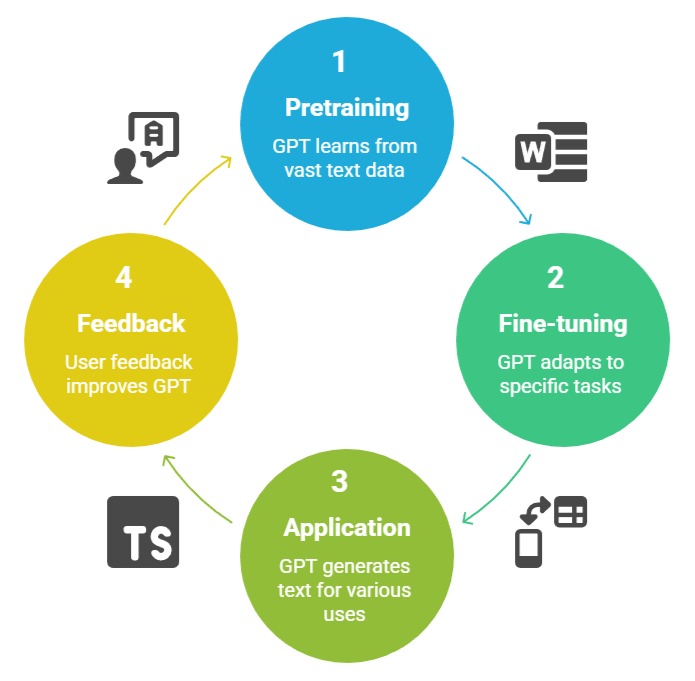
GPT is an autoregressive Transformer model designed for generative tasks. Unlike BERT, GPT predicts the next token in a sequence, learning to generate coherent text based on previous tokens.
GPT pretraining relies on a unidirectional approach, which excels in text generation, summarization, and dialogue systems.
Fine-tuning GPT allows adaptation to tasks such as story completion, conversational AI, and content generation.
Its generative nature contrasts with BERT’s masked approach, making GPT more suitable for creative and predictive NLP tasks.
Advantages
1. High-Quality Text Generation
GPT excels at producing fluent, coherent, and contextually relevant text sequences, making it ideal for chatbots, content creation, and automated report generation.
Its autoregressive training allows continuity and narrative consistency across long passages.
2. Flexible in Creative NLP Applications
GPT can perform tasks beyond conventional classification, including summarization, story writing, code generation, and dialogue.
Its versatility makes it a powerful tool for both technical and creative AI applications.
3. Strong Zero-Shot and Few-Shot Learning
Large GPT models demonstrate remarkable zero-shot and few-shot capabilities, solving new tasks with minimal or no additional training by leveraging learned representations and prompts.
This reduces the need for extensive fine-tuning datasets.
4. Scalable Architecture
GPT scales efficiently with increased parameters and data, enabling continuous performance improvements as compute and datasets grow.
This scalability has led to highly capable models like GPT-3 and GPT-4.
5. Captures Long-Term Dependencies
GPT’s Transformer backbone allows it to model long-range dependencies in sequences effectively, improving performance in text generation, summarization, and story completion tasks.
6. Supports Multimodal Integration
Recent GPT models can integrate text with other modalities (e.g., images or audio) for cross-modal generation and reasoning, expanding applicability beyond pure text.
7. Enables Advanced Conversational AI
GPT forms the basis for modern conversational agents, providing context-aware responses and natural dialogues that enhance human-computer interaction.
Disadvantages
1. Requires Massive Computational Resources
Training large GPT models is extremely resource-intensive, limiting accessibility to well-funded organizations and cloud providers.
2. Potential for Hallucination
GPT may generate text that is plausible but factually incorrect or nonsensical, posing risks for applications requiring factual accuracy.
3. Limited Control Over Output
Without prompt engineering or fine-tuning, GPT may produce outputs that are inconsistent with user expectations or domain constraints.
4. Large Memory and Storage Requirements
High parameter counts result in large models that are difficult to deploy on edge devices or memory-constrained systems.
5. Bias and Ethical Concerns
GPT inherits biases from training data, potentially generating offensive, biased, or harmful content if not carefully moderated.
6. Context Window Limitations
GPT can only attend to a fixed-length context window, limiting performance on tasks requiring understanding of extremely long documents.
7. Fine-Tuning Complexity
Adapting GPT for domain-specific applications can be challenging due to its size and sensitivity to hyperparameters, making the process resource-intensive.
Examples
1. Conversational AI: Chatbots and virtual assistants.
2. Text Summarization: Condensing long documents into concise summaries.
3. Story and Content Generation: Automated writing for marketing or entertainment.
4. Code Generation: Producing programming scripts and assisting developers.
5. Question Answering and Dialogue: Generating informative, context-aware responses.
