In deep learning, the quality and structure of data play a critical role in determining model performance. Raw datasets often contain noise, missing values, class imbalances, or irrelevant features that can hinder training.
Therefore, data preparation is a foundational step that involves cleaning, normalizing, and transforming data into a format suitable for model consumption. Proper preparation ensures that models receive consistent, high-quality inputs, leading to more stable and accurate predictions.
Data augmentation is another crucial strategy, especially in fields like computer vision and natural language processing.
It involves creating additional, synthetic training examples by applying transformations such as rotation, flipping, cropping, or synonym replacement.
Augmentation improves model generalization, prevents overfitting, and allows models to learn invariances in the data. In image classification, for instance, augmented datasets help models recognize objects from different angles or under varying lighting conditions.
Pipeline structuring refers to the systematic design of the end-to-end workflow for data handling and model training.
A well-structured pipeline ensures reproducibility, scalability, and efficiency. It includes sequential steps such as data loading, preprocessing, augmentation, batching, and feeding data into the model.
Modern frameworks like TensorFlow, PyTorch, and Apache Airflow allow practitioners to automate and orchestrate these pipelines, facilitating robust training for large-scale datasets.
Designing Reliable Data Pipelines and Preprocessing Steps
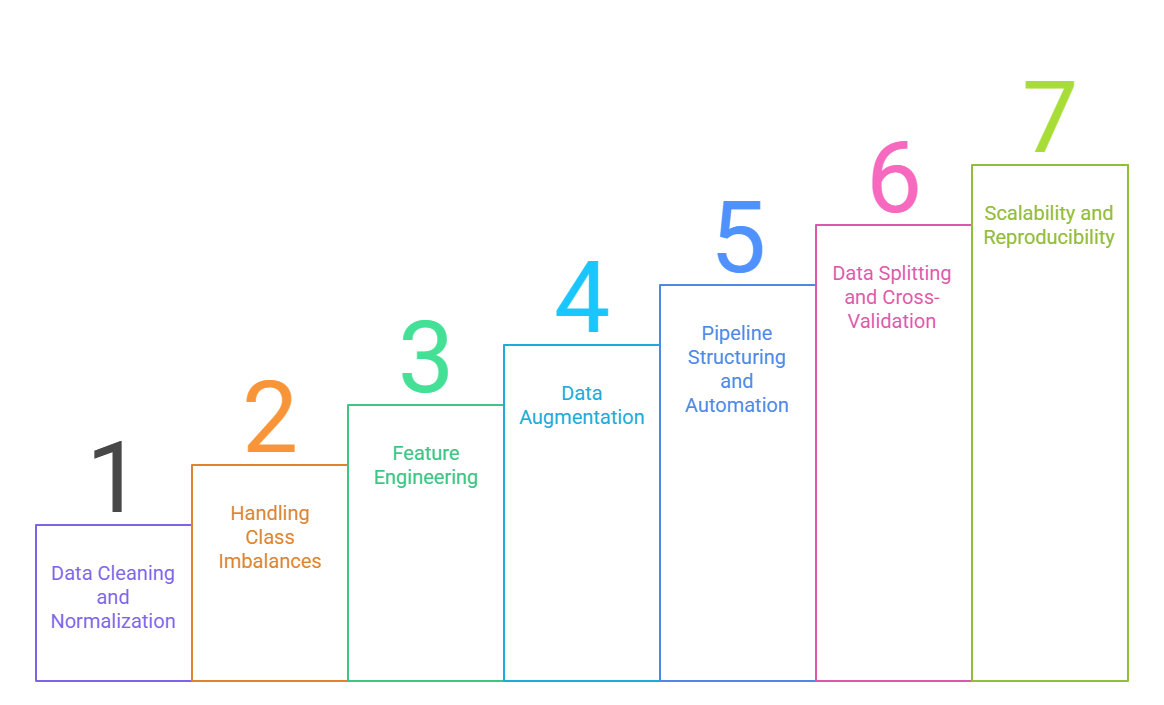 1. Data Cleaning and Normalization
1. Data Cleaning and Normalization
Data cleaning involves removing duplicates, handling missing values, and correcting inconsistent labels, ensuring that the dataset is accurate and reliable.
Normalization scales numerical features to a standard range, preventing models from being biased toward features with larger magnitudes.
Proper cleaning and normalization reduce noise and allow the model to converge faster during training, improving both stability and generalization. For example, in image data, pixel values are often scaled between 0 and 1 to maintain uniformity across datasets.
2. Handling Class Imbalances
Many real-world datasets exhibit imbalanced class distributions, which can cause models to favor majority classes.
Techniques like oversampling, undersampling, and weighted loss functions help mitigate this problem.
By addressing imbalance, models learn better representations for minority classes, reducing bias and improving fairness.
For instance, in medical imaging datasets, rare disease cases are often augmented or reweighted to ensure the model identifies critical conditions accurately.
3. Feature Engineering
Transforming raw data into informative features enhances model performance.
Feature engineering may include one-hot encoding categorical variables, extracting embeddings, or combining multiple raw features into meaningful representations.
Well-designed features provide the model with richer information and can significantly improve predictive accuracy, especially when training deep learning models on tabular or structured data.
4. Data Augmentation
Augmentation artificially increases dataset size by applying transformations to existing samples.
For images, this may include rotations, flips, color jittering, and random cropping.
In text data, augmentations can involve synonym replacement, paraphrasing, or back translation.
Augmentation helps models generalize better to unseen data, prevents overfitting, and allows for more robust feature learning. It is particularly critical when datasets are small or expensive to collect.
5. Pipeline Structuring and Automation
Designing an efficient data pipeline ensures reproducibility, reduces manual errors, and allows for seamless scaling.
A typical pipeline includes steps like data ingestion, preprocessing, augmentation, batching, and feeding into the model.
Automation frameworks such as TensorFlow Dataset API or PyTorch DataLoader help manage large datasets efficiently.
A structured pipeline also simplifies experiment tracking, making it easier to compare different preprocessing or augmentation strategies.
6. Data Splitting and Cross-Validation
Proper splitting of data into training, validation, and test sets prevents information leakage and ensures that model evaluation is unbiased.
Cross-validation techniques allow the model to be tested across multiple subsets, providing more reliable estimates of generalization performance.
This is crucial for avoiding overfitting and ensuring that deployed models perform well on unseen real-world data.
7. Scalability and Reproducibility
Large-scale datasets require scalable pipelines capable of handling millions of samples efficiently.
Tools like Apache Airflow, Kubeflow, and cloud-based storage systems facilitate distributed data processing and pipeline orchestration.
Reproducibility ensures that experiments can be repeated consistently, which is essential for deployment and regulatory compliance in critical applications like healthcare or finance.
