As deep neural networks grow in depth and complexity, training stability and convergence speed become critical challenges.
Issues such as internal covariate shift, vanishing/exploding gradients, and unstable weight updates can significantly hinder learning.
Two powerful techniques—batch normalization and gradient clipping—have emerged to address these challenges.
Batch normalization stabilizes learning by normalizing intermediate layer activations, reducing sensitivity to weight initialization and enabling higher learning rates.
Gradient clipping, on the other hand, prevents gradients from becoming excessively large during backpropagation, a common issue in very deep networks or recurrent architectures.
Both methods play complementary roles in modern deep learning workflows.
Batch normalization accelerates convergence, improves generalization, and allows deeper networks to train reliably.
Gradient clipping ensures that optimization remains stable even in the presence of steep loss landscapes, reducing the risk of numerical instability.
Batch Normalization
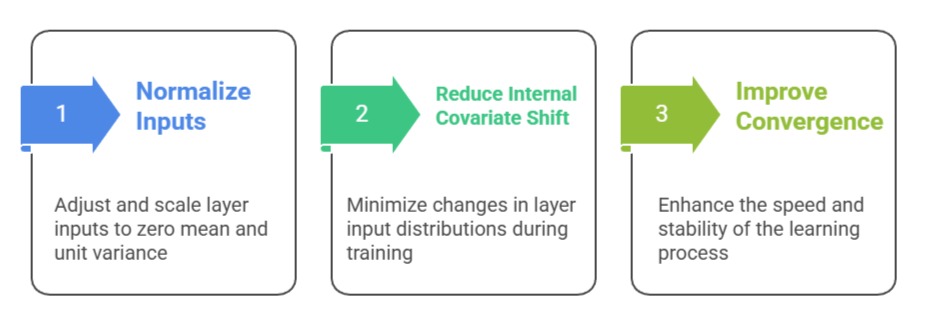 Batch normalization (BN) normalizes the inputs to each layer by adjusting and scaling the activations to have zero mean and unit variance within a mini-batch.
Batch normalization (BN) normalizes the inputs to each layer by adjusting and scaling the activations to have zero mean and unit variance within a mini-batch.
This reduces internal covariate shift—the phenomenon where the distribution of layer inputs changes during training—which can slow down convergence and destabilize learning.
pythonimport torch.nn as nn
nn.Conv2d(3, 64, kernel_size=3, padding=1)
nn.BatchNorm2d(64)
Advantages
1. Accelerates Convergence
Batch normalization reduces internal covariate shift by normalizing activations, which allows the network to use higher learning rates safely.
This speeds up training and helps deep networks converge more efficiently.
It stabilizes gradient flow, enabling smoother optimization and reducing the number of epochs required to reach optimal performance.
2. Improves Generalization
By introducing mini-batch statistics during training, BN adds slight stochasticity that acts as a regularizer.
This reduces overfitting and encourages the model to develop more robust internal representations.
Combined with other regularization techniques, it enhances performance on unseen data.
3. Reduces Sensitivity to Initialization
BN makes the network less dependent on precise weight initialization.
Since activations are normalized, the impact of poor initialization is minimized, which allows stable training even with deeper architectures or varying initial conditions.
4. Enables Deeper Architectures
BN mitigates vanishing and exploding gradients by stabilizing activations across layers.
This allows very deep networks, such as ResNets and Transformers, to train effectively without additional architectural modifications.
It reduces sensitivity to depth-related instability, making extremely deep models feasible for complex tasks like image recognition and NLP.
5. Reduces Learning Rate Sensitivity
With normalized activations, networks become less sensitive to learning rate selection.
This allows the use of relatively higher learning rates, accelerating convergence and reducing the time spent tuning hyperparameters.
It also reduces the risk of divergence during training caused by overly aggressive updates.
6. Supports Multi-Task and Transfer Learning
Batch normalization improves generalization across tasks and datasets, which is particularly useful in transfer learning.
By stabilizing internal representations, BN allows pretrained models to adapt quickly to new tasks without retraining the entire network.
This makes it ideal for fine-tuning large models efficiently.
Disadvantages
1. Dependency on Mini-Batch Size
BN relies on accurate batch statistics, so very small batch sizes can introduce noise and unstable training.
In scenarios like online learning or small datasets, this can reduce effectiveness and require alternative normalization methods like Layer Normalization.
2. Slight Computational Overhead
Calculating batch mean and variance, and performing scaling and shifting adds extra computation and memory usage.
While often negligible in modern GPUs, it can be significant for extremely large networks or resource-constrained environments.
3. Inconsistent Behavior Between Training and Inference
BN uses batch statistics during training but running averages during inference.
If batch statistics differ significantly from running estimates, predictions may be slightly off.
This discrepancy can lead to minor performance drops if not carefully managed, especially in models with small batch sizes.
4. Less Effective for Sequential Models
In recurrent networks or models with varying sequence lengths, batch normalization may introduce inconsistencies due to fluctuating mini-batch statistics.
Alternative normalization methods like Layer Normalization or Group Normalization are often preferred for sequential data.
5. Minor Impact on Memory and Training Time
While BN generally accelerates convergence, it does increase memory consumption and slightly slows per-iteration computation.
For extremely large networks or hardware-limited scenarios, this overhead can be noticeable and may require memory optimization strategies.
Gradient Clipping
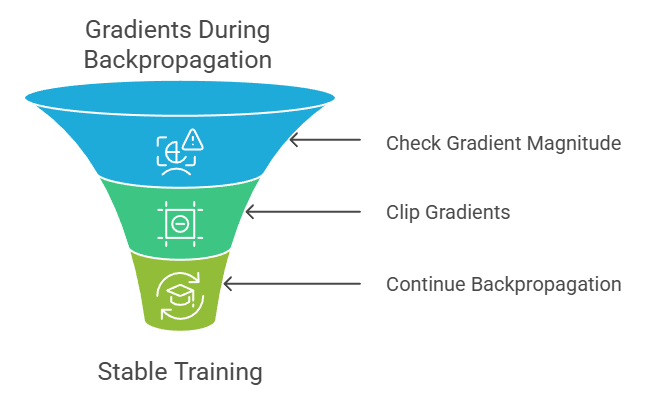
Gradient clipping restricts the magnitude of gradients during backpropagation to prevent exploding gradients.
This is especially important in very deep networks or recurrent neural networks (RNNs), where gradients can grow exponentially and destabilize training.
Example
Clipping gradients in PyTorch for an RNN:
import torch.nn.utils as utils
utils.clip_grad_norm_(model.parameters(), max_norm=1.0)TensorFlow example using optimizer:
pythonoptimizer = tf.keras.optimizers.Adam(learning_rate=0.001, clipnorm=1.0)
Advantages
1. Stabilizes Training
Gradient clipping prevents gradients from exceeding a set threshold, avoiding exploding gradients that can destabilize learning.
This ensures smooth weight updates, particularly in very deep or recurrent networks, improving overall stability.
2. Supports Higher Learning Rates
By keeping gradients under control, clipping allows the use of larger learning rates without risking divergence.
This can accelerate training while maintaining safe optimization paths, especially in networks prone to steep loss surfaces.
3. Reduces Weight Oscillations
Controlling extreme gradient values prevents large abrupt changes in weights, helping the model converge more smoothly.
This contributes to better generalization and prevents the network from overfitting due to erratic updates.
4. Facilitates Stable Training for RNNs and LSTMs
Recurrent networks are particularly prone to exploding gradients due to repeated multiplications through time steps.
Gradient clipping ensures that weight updates remain within a safe range, enabling stable learning over long sequences.
This is essential for NLP tasks such as language modeling or machine translation.
5. Complements Advanced Optimizers
Clipping gradients works well alongside adaptive optimizers like Adam or RMSProp.
It prevents occasional extreme updates that could disrupt momentum-based or adaptive learning rate strategies, leading to smoother convergence and more predictable training behavior.
6. Reduces Risk of NaN or Inf Values
Exploding gradients can sometimes result in numerical overflow, producing NaN or Inf values in weights or activations.
Gradient clipping protects against such catastrophic failures, ensuring training does not halt unexpectedly and improving robustness in large or complex models.
Disadvantages
1. Requires Careful Threshold Selection
Choosing an appropriate clipping threshold is critical; too low restricts learning, while too high fails to prevent exploding gradients.
Selecting the correct value often involves trial and error and monitoring training stability closely.
2. Addresses Symptoms, Not Causes
Gradient clipping prevents exploding gradients but does not fix underlying issues such as poor initialization, unsuitable learning rates, or overly deep architectures.
It should be combined with other methods for robust training.
3. May Mask Poor Model Design
While gradient clipping stabilizes training, it does not address fundamental architectural or hyperparameter issues.
Networks with inappropriate depth, learning rates, or initialization may still underperform, and clipping can hide these underlying design problems.
4. Can Slow Convergence if Overused
If the clipping threshold is too low, weight updates become overly restricted, limiting the optimizer’s ability to reach optimal minima.
This may lead to slower convergence or underfitting, requiring careful monitoring to balance stability and learning progress.
5. Extra Hyperparameter to Tune
Gradient clipping introduces an additional hyperparameter—the clipping threshold—which needs careful selection.
Incorrect thresholds can either negate benefits or impede learning, adding complexity to the training pipeline and requiring experimentation.
