Optimization algorithms are essential components in training deep learning models because they determine how efficiently a network updates its weights to reduce loss.
At their core, these algorithms control the direction and magnitude of parameter adjustments during backpropagation.
Without effective optimization strategies, even the most advanced neural architectures struggle to converge or achieve meaningful accuracy.
Techniques such as Stochastic Gradient Descent (SGD), Adam, and RMSprop have become standards in the field due to their adaptability, computational efficiency, and ability to navigate complex loss landscapes.
Each method offers unique strengths, making them suitable for different tasks, data scales, and network structures
Stochastic Gradient Descent (SGD)
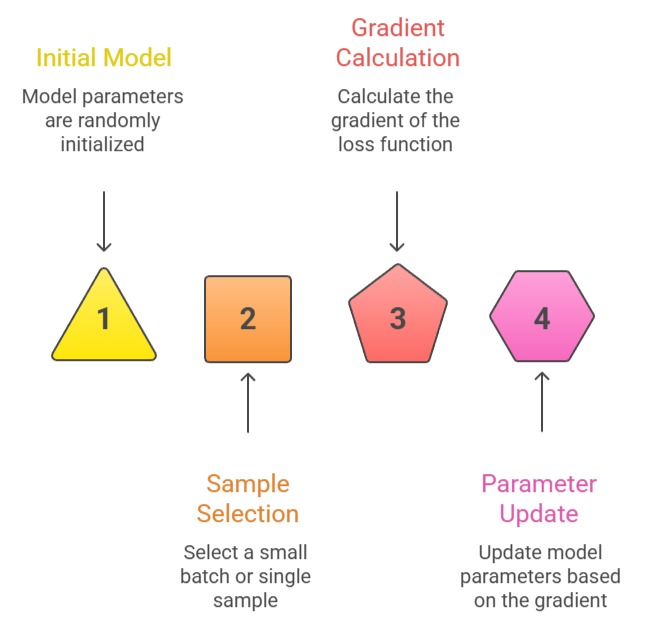
SGD updates model parameters using a small batch or even a single training sample, which introduces randomness into the optimization process.
This stochasticity helps the model escape shallow local minima and reduces computation per iteration.
It remains widely used because of its simplicity and strong performance in many large-scale training scenarios.
Example: Training a convolutional neural network on CIFAR-10 using SGD with momentum often yields superior generalization compared to adaptive methods.
Advantages
1. Memory-efficient updates
SGD processes only a small portion of data at each step, which significantly reduces memory load during training.
This makes it suitable for large datasets and deep models that cannot fit into limited GPU memory.
By handling mini-batches, it enables scalable training even in constrained environments. This efficiency also helps when running models on distributed systems.
2. Naturally promotes good generalization
The inherent noise in SGD updates prevents the model from memorizing the training set too aggressively.
This randomness steers the optimization path through multiple regions of the loss landscape, increasing the chances of finding flatter minima.
Flatter minima are often associated with improved generalization performance on unseen data. This characteristic benefits tasks where robustness is a priority.
3. Works extremely well with momentum
Momentum smooths the optimization trajectory by accumulating past gradients and pushing updates in consistent directions.
When combined with momentum, SGD becomes considerably faster and more stable. It reduces oscillations, especially in deep networks with complex curvature.
This pairing is one of the reasons SGD remains a top choice in computer vision tasks.
Disadvantages
1. Requires careful learning-rate tuning
SGD is sensitive to the initial learning rate, and an improper value can derail the entire training process.
Too high a rate may cause divergence, while too low a rate significantly slows convergence.
This forces practitioners to rely on schedules or trial-and-error, which increases the time needed to achieve optimal results. Effective tuning becomes harder as model size grows.
2. Slow convergence on complex problems
Because SGD uses uniform learning rates for all parameters, it may struggle with gradients that vary greatly in scale.
This results in slow progress in flat regions and unstable updates in steep areas.
Networks with intricate loss surfaces, such as deep CNNs, often experience prolonged training times. Without adaptive techniques, convergence may stagnate.
3. Struggles with sparse gradients
SGD applies equal update strength across all parameters, which is not ideal when dealing with sparse features.
In problems like NLP or recommender systems, many weights require only minor adjustments.
SGD may update these unnecessarily, leading to inefficiencies. Adaptive methods tend to handle such situations more effectively.
Adam (Adaptive Moment Estimation)
Adam combines ideas from momentum and RMSprop, maintaining running averages of both gradients and squared gradients.
This enables it to adapt learning rates per parameter while also smoothing updates over time.
It is widely used across deep learning due to its fast convergence and minimal requirement for manual tuning.
Example: Adam is commonly used for training transformer-based language models because it manages sparse attention patterns exceptionally well.
Advantages
1. Adapts learning rates for each parameter
Adam uses running estimates of gradients and squared gradients to adjust learning rates dynamically.
This allows different parameters to move at speeds proportional to their activity.
Such adaptability removes much of the manual tuning seen in classical methods. As a result, Adam often converges swiftly even on difficult optimization landscapes.
2. Highly stable in noisy environments
Because Adam smooths gradients over time, sudden spikes or erratic updates have less influence on training.
This stability is especially beneficial when working with noisy labels or complex data distributions.
It helps maintain consistent progress without sharp swings. Models remain reliable even when data varies significantly across batches.
3. Excellent performance with sparse gradients
Adam excels at tasks where only a subset of parameters receive frequent updates, such as NLP embeddings or attention weights.
The optimizer boosts relevant parameters while reducing unnecessary updates elsewhere. This ability makes it particularly strong for large-scale language models.
Its handling of sparse features reduces training time and improves performance.
Disadvantages
1. May find sharp minima
Adaptive learning rates can lead Adam toward sharp minima that look optimal during training but generalize poorly.
These sharp regions often cause significant drops in accuracy when evaluated on real-world data.
This drawback is especially visible in image recognition tasks. As a result, SGD sometimes outperforms Adam in long-term generalization.
2. Requires more memory
Adam stores moving averages for both gradients and squared gradients, doubling memory use compared to SGD.
This overhead becomes noticeable when training extremely large models or deploying on constrained hardware.
Extra memory consumption may slow training and increase cost. Large-scale training pipelines must consider this limitation.
3. Sensitive to hyperparameters
Although Adam often works out-of-the-box, its performance can shift dramatically if β₁, β₂, or ε values are poorly chosen.
These parameters control how quickly the optimizer adapts and how strongly it smooths past updates.
Incorrect settings can lead to stagnation or unstable learning. Careful experimentation is sometimes required.
RMSprop
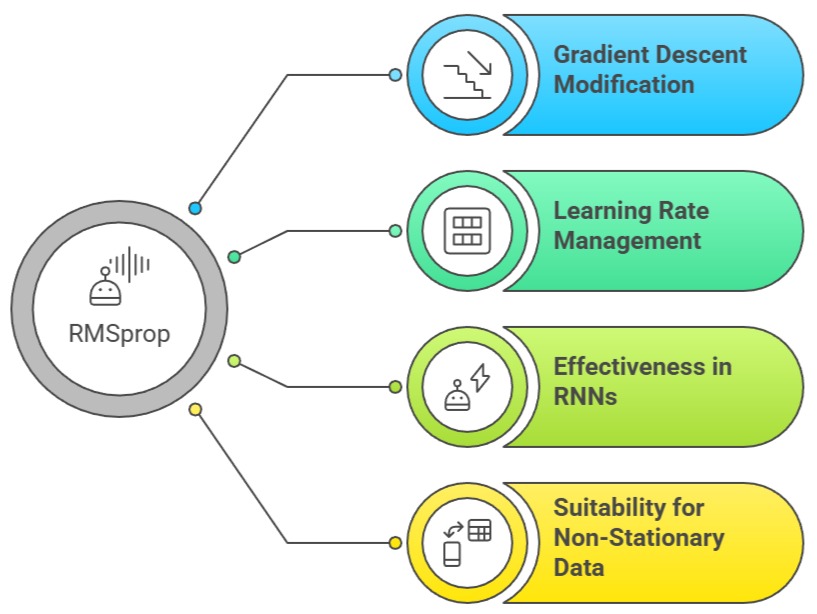
RMSprop modifies gradient descent by adjusting updates based on a moving average of squared gradients.
This keeps learning rates manageable and prevents excessively large steps in steep regions of the loss surface.
RMSprop is particularly effective in recurrent neural networks and tasks involving non-stationary data.
Example: RMSprop is frequently used for training RNN-based models in speech recognition, where gradient magnitudes vary across time steps.
Advantages
1. Effective control of gradient magnitudes
RMSprop maintains a running average of squared gradients, preventing learning rates from becoming excessively large.
This helps the optimizer avoid erratic movements in steep regions of the loss surface.
It makes the training process more controlled and predictable. As a result, models converge more steadily during initial training phases.
2. Well-suited for sequence and time-dependent tasks
RMSprop shines in recurrent architectures because it handles variable gradient scales across time steps.
This is crucial for RNNs, where gradients can fluctuate widely. By stabilizing these fluctuations, RMSprop ensures smoother learning.
Tasks such as speech modeling, time-series forecasting, and reinforcement learning benefit greatly.
3. Performs reliably with non-stationary data
In environments where data patterns shift over time—like streaming systems or online learning—RMSprop maintains consistent adaptation.
It adjusts quickly to new gradient trends without losing track of recent history. This flexibility is valuable for dynamic applications.
It ensures models remain functional despite changing input behavior.
Disadvantages
1. Requires fine-tuning of decay rate
The decay factor determines how strongly past gradients influence current updates.
If set incorrectly, the optimizer might over-smooth or under-smooth the gradient signals.
Both extremes can slow down training or lead to poor convergence. Thus, finding the right balance is essential for optimal performance.
2. Lacks inherent momentum
Unlike Adam, RMSprop does not include momentum by default, which may slow its progress on complex terrains.
Without momentum, updates may lack directionality and wander inefficiently.
Adding momentum manually can help, but it adds tuning complexity. This limitation makes RMSprop less attractive for deep architectures.
3. May underperform on large-scale vision tasks
RMSprop's adaptive behavior is helpful for sequential data but less effective for high-dimensional image models.
Such tasks often demand stronger generalization and momentum-driven optimization.
Because RMSprop does not naturally encourage movement toward flatter minima, it may struggle. As a result, SGD or Adam often outperform it.

Class Sessions
Sales Campaign

We have a sales campaign on our promoted courses and products. You can purchase 1 products at a discounted price up to 15% discount.