Neural networks form the structural core of deep learning, and understanding their fundamental components is essential for building sophisticated AI systems.
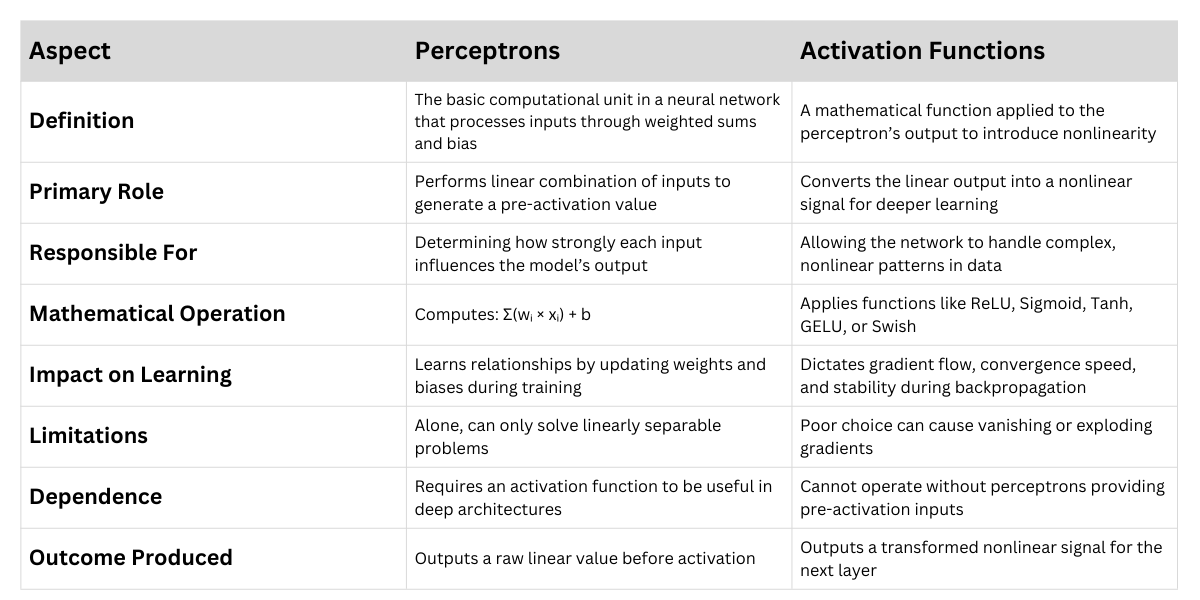
At the heart of these networks lies the perceptron, a simple computational unit that takes numerical inputs, multiplies them by associated weights, applies a bias, and produces an output.
By stacking many such units in layers, networks evolve into powerful models that can approximate complex relationships within data.
Another critical element that gives neural networks their expressive capability is the activation function.
This function introduces nonlinearity, enabling the model to capture patterns that linear transformations alone cannot represent.
Without activation functions, even deep architectures would collapse into mere linear mappings, severely limiting their learning capacity.
Modern activation functions such as ReLU, GELU, and Swish have redefined how efficiently networks train and how well they generalize.
Importance of Neural Networks
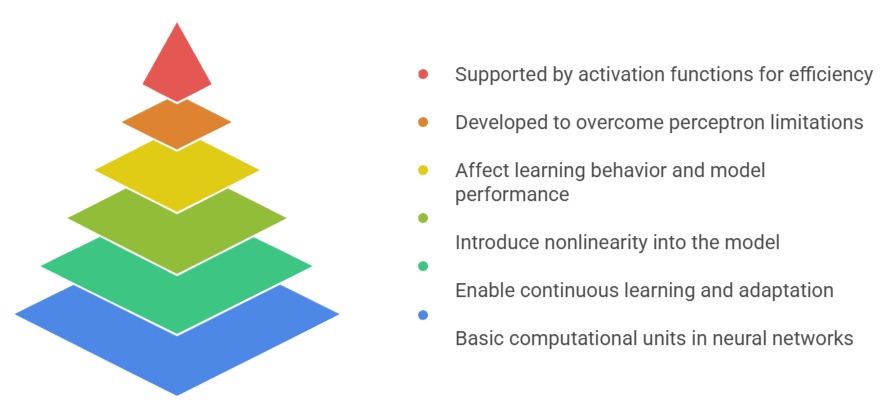
1. Perceptrons serve as the foundational computational units in neural networks
A perceptron processes inputs through weighted connections, adds a bias, and passes the result into an activation function.
This mechanism determines how much influence each input contributes to the output, allowing the model to adjust during training. As the network encounters more data, these weights shift to reduce prediction errors.
When multiple perceptrons are organized into layers, the system can represent increasingly detailed interactions.
Such layered configurations enable networks to move from identifying simple patterns in early layers to decoding more sophisticated relationships deeper within the architecture.
2. Weights and biases enable continuous learning and adaptation
Weights represent the strength of connections, while biases offer a way to shift activation thresholds.
Adjusting these parameters is central to how neural networks learn from examples.
During training, optimization algorithms such as SGD or Adam refine these values to align outputs with correct targets.
This dynamic tuning process allows models to improve accuracy over time and generalize to new data.
Because weights and biases can capture subtle distinctions, they give networks the flexibility needed to operate effectively across diverse domains and tasks.
3. Activation functions introduce essential nonlinearity into the model
Without nonlinear activation functions, a network regardless of depth would behave like a single linear transformation.
Activation functions break this limitation by allowing networks to model curved surfaces, discontinuities, and complex decision boundaries.
Popular choices like ReLU help avoid vanishing gradients, while sigmoid and tanh remain useful in specific contexts such as probability predictions or recurrent structures.
More advanced functions like GELU or Swish enhance training stability and performance in modern architectures, contributing to breakthroughs in language models and vision transformers.
4. Different activation functions influence learning behavior and model performance
Every activation function carries specific properties that affect how quickly networks train, how stable gradients remain, and how well models generalize.
For Example, ReLU accelerates learning by enabling sparse activation, but it may cause inactive neurons if gradients reach zero.
Smooth functions like Swish maintain gradient flow, which benefits deep architectures.
Choosing an appropriate activation function can substantially impact accuracy, convergence speed, and the network’s ability to capture meaningful representations.
5. Perceptron limitations inspired the development of multi-layer networks
A single perceptron can only solve linearly separable tasks, which severely restricts its applicability.
This constraint motivated researchers to explore multi-layer networks that combine many perceptrons in sequence.
With the help of activation functions, these multi-layer perceptrons (MLPs) can approximate virtually any mathematical function.
The transition from basic perceptrons to deep networks marked a major milestone in AI, enabling machine learning models to tackle real-world problems with increasing sophistication.
6. Activation functions support efficient gradient-based training
For optimization algorithms to function properly, activation functions must offer differentiability in most regions.
Smooth gradients are vital for backpropagation, the algorithm used to adjust weights across all layers. If gradients vanish or explode, training becomes unstable.
Modern activation functions are designed to maintain usable gradient magnitudes, ensuring that deep architectures can be trained reliably.
This has been a key factor in the success of contemporary neural network models.
Perceptrons vs Activation Functions

Class Sessions
Sales Campaign

We have a sales campaign on our promoted courses and products. You can purchase 1 products at a discounted price up to 15% discount.