Regression algorithms are fundamental tools in machine learning used to predict continuous outcomes based on input variables. They establish relationships between dependent and independent variables, enabling forecasting, trend analysis, and decision-making across diverse domains.
Introduction to Regression
Regression analysis focuses on modeling the relationship between a continuous dependent variable and one or more independent variables (features). The goal is to learn a function that maps inputs to predicted continuous values while minimizing prediction errors. Different regression algorithms vary in complexity, interpretability, and suitability for handling multicollinearity, overfitting, or non-linear relationships.
Linear Regression
Linear Regression is the simplest and most widely used regression technique. It assumes a linear relationship between the independent variables and the dependent variable.
How it Works:
1. The algorithm fits a linear equation ![]()
![]() ,
, ![]()
2. Coefficients β are estimated using methods like Ordinary Least Squares (OLS) to minimize the sum of squared residuals.
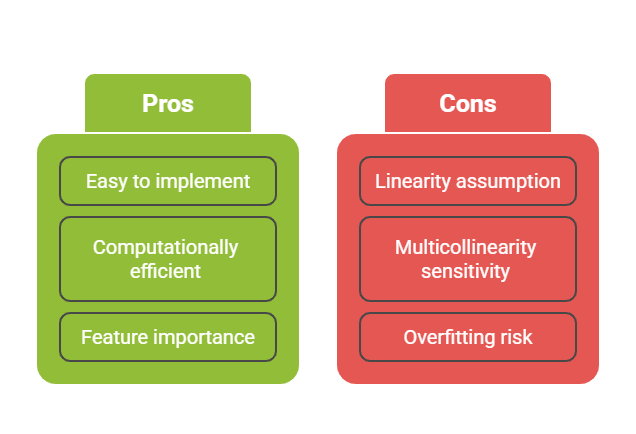
Ridge and Lasso Regression (Regularized Regression)
Regularization techniques address overfitting and multicollinearity by adding penalty terms to the linear regression's cost function, shrinking coefficient magnitudes.
Ridge Regression (L2 Regularization):
1. Adds a penalty equal to the sum of the squared coefficients multiplied by a regularization parameter λ.
2. Shrinks coefficients towards zero but never exactly zero.
3. Effectively reduces model complexity while retaining all features.
4. Suitable when all predictors contribute to the outcome.
Mathematically, the objective is:

Lasso Regression (L1 Regularization):
1. Adds a penalty proportional to the absolute values of the coefficients.
2. Can shrink some coefficients exactly to zero, performing feature selection.
3. Produces simpler, more interpretable models by excluding irrelevant features.
4. Useful when only a subset of predictors is relevant.
Objective function:

Decision Tree Regression
Decision Tree Regression models predict continuous outputs by recursively partitioning the feature space into regions and fitting simple models within each region.
How it Works:
1. Split data based on feature thresholds that minimize prediction error (e.g., mean squared error).
2. Create a tree structure where leaf nodes represent predicted values.
.png)
Practical Use Cases
1. Linear Regression: Predicting sales based on advertising spend.
2. Ridge Regression: Housing price estimation with many correlated features.
3. Lasso Regression: Genetic data analysis where only a few genes impact the outcome.
4. Decision Trees: Customer segmentation and credit risk analysis.

Class Sessions
Sales Campaign

We have a sales campaign on our promoted courses and products. You can purchase 1 products at a discounted price up to 15% discount.