Data collection and storage are fundamental components of any data-driven process, including artificial intelligence and machine learning projects. The accuracy, relevance, and accessibility of collected data are critical for building robust models and enabling efficient analysis.
Data Collection
It is the systematic process of gathering information from various sources to answer specific questions, test hypotheses, or support decision-making. It is the first step in the data lifecycle and sets the foundation for subsequent data processing and analysis. Effective data collection ensures that the data is accurate, relevant, consistent, and representative of the task or phenomenon under study.
Methods of Data Collection:
 Data collection methods can be broadly classified as primary or secondary:
Data collection methods can be broadly classified as primary or secondary:
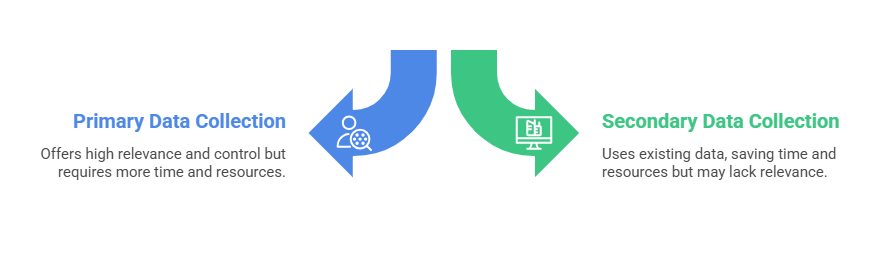
1. Primary data collection involves directly gathering new data through methods such as:
Surveys and questionnaires (online, face-to-face, telephone)
Interviews and focus groups
Observations (e.g., field studies or sensor recordings)
Experiments or controlled data generation
Primary data collection is tailored to specific study goals, offering high relevance and control over data quality but often requires more time and resources.
2. Secondary data collection uses existing data gathered by others for different purposes:
Published sources (books, research papers, government reports)
Online databases and public datasets
Organizational records and transactional logs
Social media and web-scraped data
Secondary data is readily available and cost-effective, but may require careful validation and preprocessing for new analytical uses.
Data Quality and Ethics Considerations
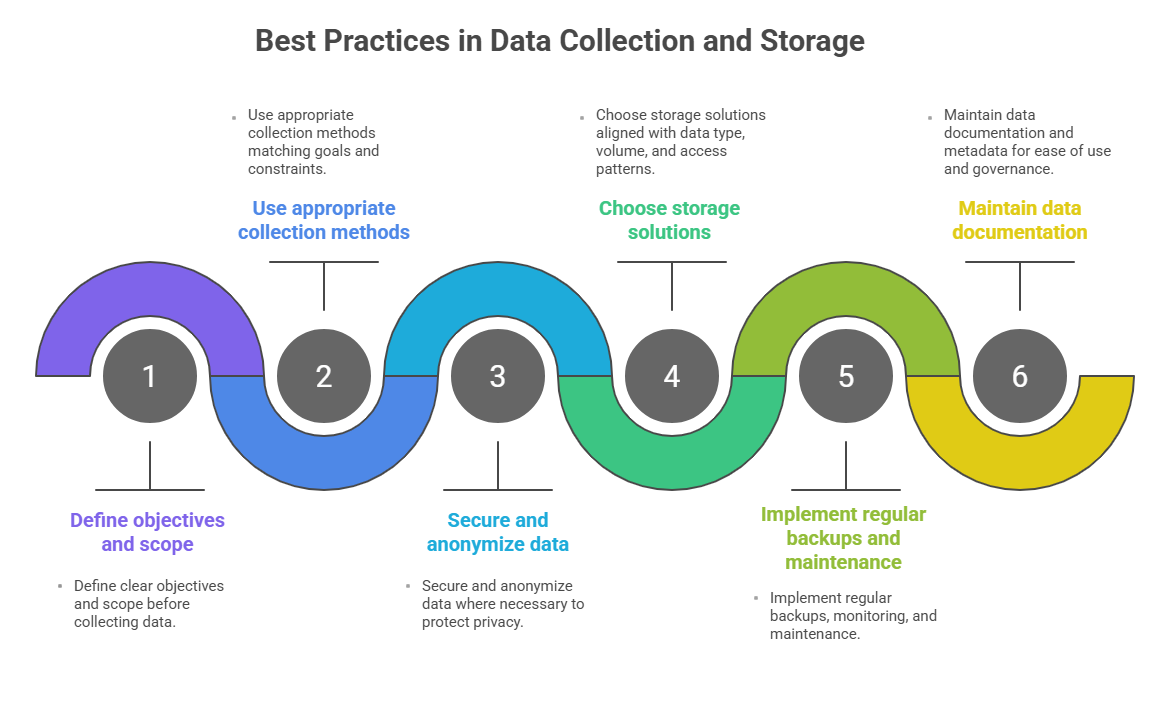
Ensuring data quality involves maintaining accuracy, completeness, consistency, and timeliness during collection. Ethical considerations include respecting privacy, obtaining informed consent, and securing sensitive information to comply with regulations such as GDPR or HIPAA.
Data Storage
It is the technology and methods used to save collected data for access, processing, and long-term retention. The choice of storage depends on data type, volume, access speed, security, and scalability requirements.
Types of Data Storage:
1. Direct Attached Storage (DAS): Storage devices like SSDs or HDDs attached directly to one system. Suitable for small-scale or backup storage.
2. Network Attached Storage (NAS): Storage accessible over a local network, enabling multiple users or applications to share data.
3. Storage Area Network (SAN): A high-performance network designed for block-level data storage, commonly used in enterprise environments.
4. Cloud Storage: Scalable, flexible storage provided via internet services like AWS S3, Azure Blob Storage, or Google Cloud Storage. Supports on-demand access and large-scale data handling.
5. Data Lakes: Centralized repositories optimized for storing raw and unstructured data in native formats. Ideal for big data and advanced analytics use cases.

Class Sessions
Sales Campaign

We have a sales campaign on our promoted courses and products. You can purchase 1 products at a discounted price up to 15% discount.