In the lifecycle of machine learning projects, transitioning from model development to production deployment is pivotal. Model serving and API development are integral parts of this deployment phase, enabling trained models to be accessible and usable by other systems or end-users in real time.
What is Model Serving?
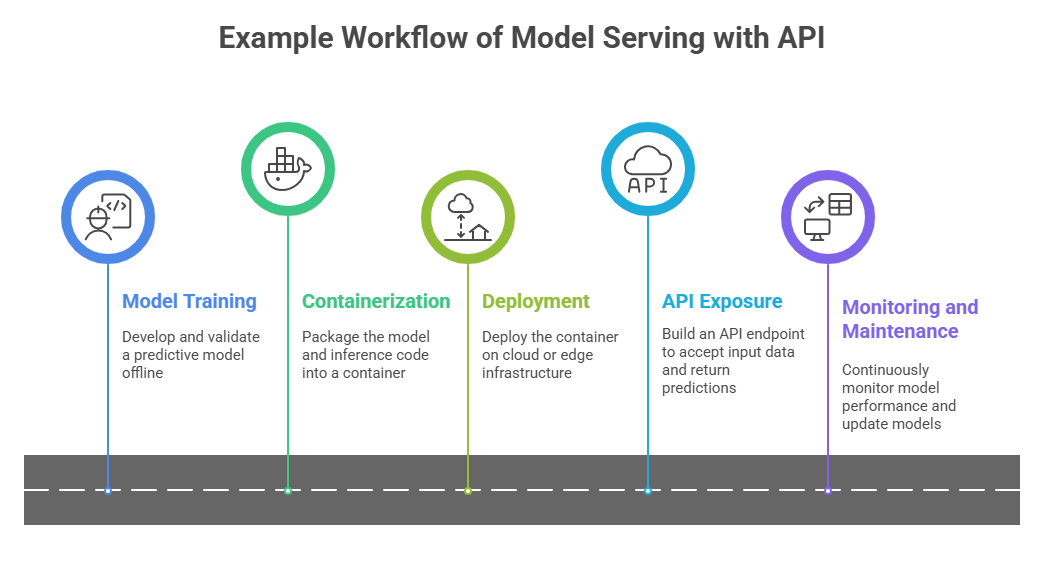
Model serving refers to the process of making a trained machine learning model available in a production environment to perform inference on new data inputs. It acts as a bridge between the model's offline training phase and real-time decision-making or automation applications.
Goal: Efficiently deliver model predictions with low latency and high reliability.
Context: Part of a larger MLOps pipeline encompassing continuous integration, monitoring, and maintenance.
Model serving may involve scaling, load balancing, version control, and integration with upstream and downstream systems.
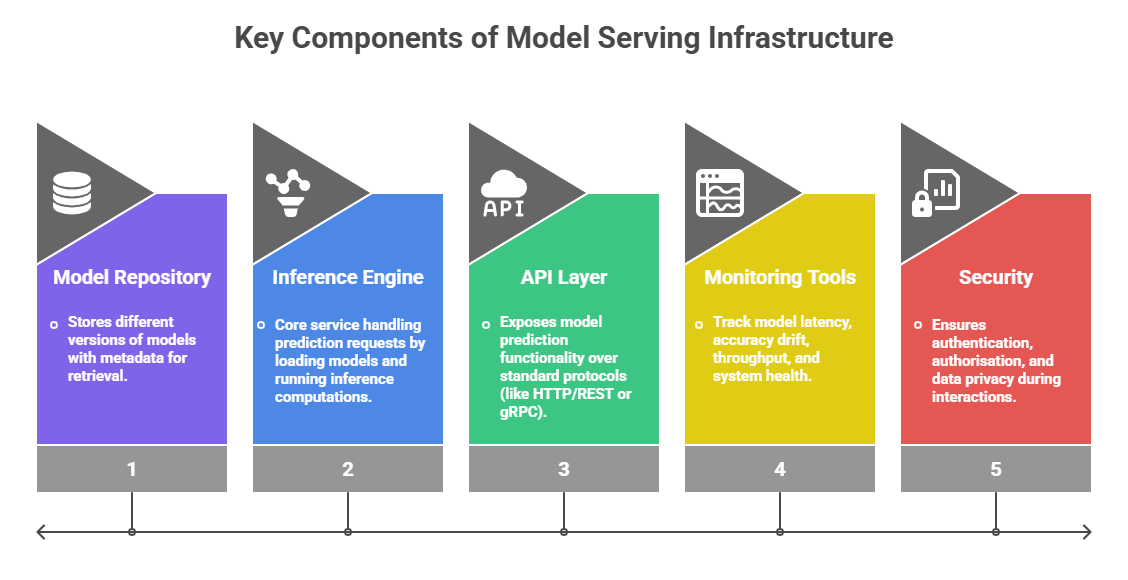
API Development for Machine Learning Models
An API (Application Programming Interface) provides a standardised way for external applications to interact with the model serving system. This makes the machine learning model reusable, scalable, and maintainable.
1. RESTful APIs: Popular approach using HTTP methods, allowing clients to send prediction requests and receive responses.
2. gRPC: High-performance alternative suited for microservices and internal communication.
3. Input/Output Specification: Clear schema definitions for requests and responses ensure consistent and error-free communication.
4. Serialisation Formats: JSON, Protocol Buffers, or Avro are commonly used for data exchange.
Best Practices for Model Serving and APIs
Effective model serving depends on a set of core operational principles that support stability and smooth delivery. The following outlines essential practices to optimise API-driven model usage.
1. Versioning: Maintain multiple model versions to rollback or test new models safely.
2. Scalability: Use container orchestration (e.g., Kubernetes) and auto-scaling to handle variable loads.
3. Latency Optimisation: Employ batching, caching, or model quantisation to reduce prediction time.
4. Robust Error Handling: Ensure graceful degradation and meaningful error messages.
5. Logging and Auditing: Keep detailed logs for monitoring and diagnosing issues.
6. Security Measures: Use TLS, API gateways, and authentication mechanisms to protect endpoints.

Class Sessions
Sales Campaign

We have a sales campaign on our promoted courses and products. You can purchase 1 products at a discounted price up to 15% discount.