Dimensionality reduction is an essential technique in machine learning and data analysis used to simplify high-dimensional datasets while preserving meaningful information. This process improves model performance, reduces computational complexity, and aids in visualization.
Two popular techniques for dimensionality reduction are Principal Component Analysis (PCA) and t-Distributed Stochastic Neighbor Embedding (t-SNE). Though both serve to reduce data dimensions, they have different mechanisms, strengths, and use cases.
Dimensionality Reduction
High-dimensional data can be challenging to analyze due to the "curse of dimensionality," which leads to overfitting and prolonged computation times. Dimensionality reduction helps by transforming the data into a lower-dimensional space that retains important characteristics. This is useful for both preprocessing before model training and for visualizing complex datasets.
Principal Component Analysis (PCA)
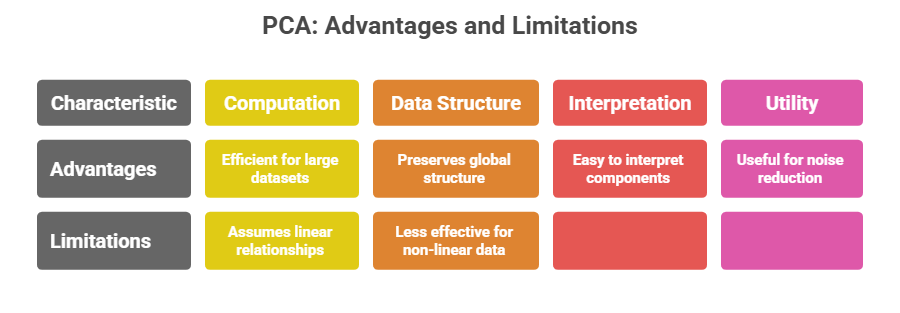
PCA is a linear dimensionality reduction technique that identifies the directions (principal components) along which the data varies the most. It projects the original data onto a smaller set of orthogonal axes that capture the maximum variance.
How PCA Works:
1. Computes the covariance matrix of the data.
2. Extracts eigenvalues and eigenvectors representing directions of maximum variance.
3. Order these principal components by the amount of variance explained.
4. Projects data onto the top principal components, reducing the feature space while preserving global structure.
t-Distributed Stochastic Neighbor Embedding (t-SNE)
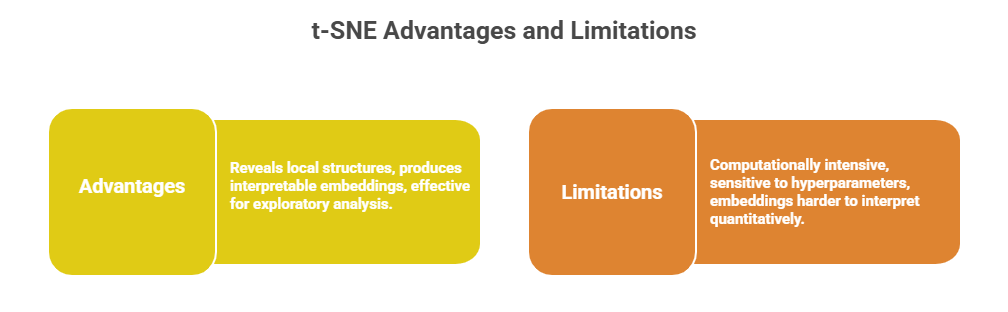
t-SNE is a non-linear dimensionality reduction technique designed primarily for visualizing high-dimensional data in two or three dimensions. It focuses on preserving local relationships and similarities by converting distances into probabilities that capture pairwise similarities.
How t-SNE Works:
1. Converts distances between high-dimensional points into conditional probabilities reflecting similarity.
2. Maps these probabilities to a low-dimensional space using a Student’s t-distribution to model similarities.
3. Optimizes the embedding by minimizing the Kullback–Leibler divergence between high- and low-dimensional probability distributions using gradient descent.
4. Emphasizes preserving distances between nearby points, clustering similar data points together.
Hybrid Approach
Often in practice, PCA is used first to reduce very high-dimensional data to fewer dimensions (e.g., 50), followed by t-SNE for further reduction to 2 or 3 dimensions to improve visualization speed and quality.

Class Sessions
Sales Campaign

We have a sales campaign on our promoted courses and products. You can purchase 1 products at a discounted price up to 15% discount.