Regularization is a fundamental strategy in machine learning used to prevent overfitting, improve model generalization, and manage model complexity. By adding constraints or penalties to the learning process, regularization discourages the model from fitting noise in the training data, thus helping it perform better on unseen data.
Introduction to Regularization
Overfitting occurs when a machine learning model models training data too closely, including random fluctuations or noise, resulting in poor performance on new data.
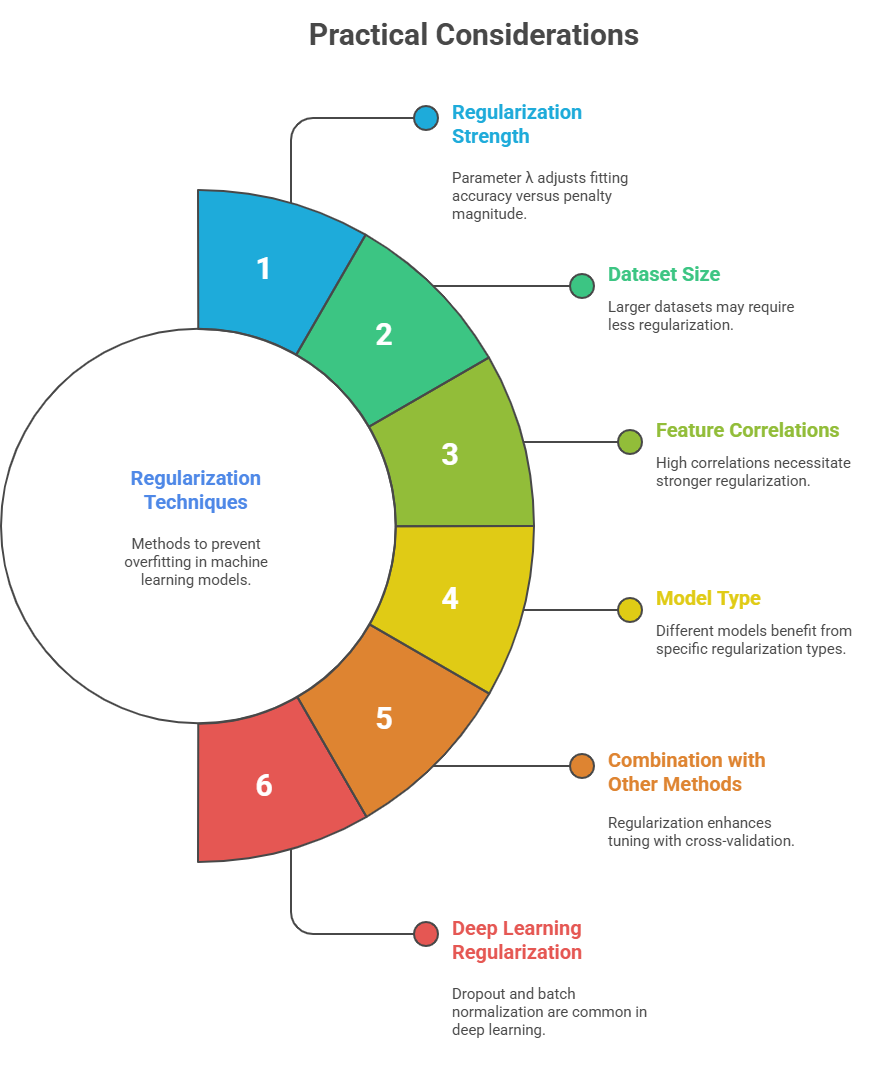
Regularization techniques modify the learning algorithm by adding penalty terms or by other mechanisms to limit model complexity. The core idea is to find a balance between accurately fitting the training data and maintaining simplicity to generalize well.
Key Regularization Techniques
Here are some of the most effective regularization techniques applied in machine learning and deep learning. They help mitigate overfitting, improve convergence, and maintain model interpretability.
1. L1 Regularization (Lasso)
Adds a penalty equal to the absolute value of the coefficients' magnitudes to the loss function.
Encourages sparsity by shrinking some coefficients to exactly zero.
Effectively performs feature selection by eliminating less important features.
Useful when a simpler, interpretable model is desired.
Mathematically: ![]()
2. L2 Regularization (Ridge)
Adds a penalty proportional to the square of the coefficients’ magnitudes.
Shrinks coefficients evenly but does not set them to zero.
Addresses multicollinearity by stabilizing coefficient estimates.
Helps produce smoother models with minimal weights.
Mathematically: ![]()
3. Elastic Net
Elastic Net is a regularization technique that combines both L1 (Lasso) and L2 (Ridge) penalties. This approach balances sparsity with coefficient shrinkage, making it robust for feature selection and reducing overfitting. It is particularly useful for datasets with correlated features, where Lasso alone may produce unstable results.
4. Dropout
Dropout is a regularization method used in neural networks that randomly removes neurons along with their connections during training. This forces the network to learn redundant representations and prevents over-reliance on specific pathways. By reducing the co-adaptation of neurons, dropout improves the robustness and generalization of the model.
5. Early Stopping
Early stopping monitors model performance on a validation set during training and halts training when improvement ceases. This technique prevents overfitting by limiting excessive training that could memorize the training data. It ensures that the model maintains good generalization on unseen data.
6. Batch Normalization (as Regularization)
Batch normalization standardizes the inputs to each layer during training, reducing internal covariate shift and stabilizing learning. It accelerates training while providing mild regularization effects, sometimes reducing the need for additional techniques like dropout. Maintaining consistent input distributions helps neural networks converge faster and generalize better.

Class Sessions
Sales Campaign

We have a sales campaign on our promoted courses and products. You can purchase 1 products at a discounted price up to 15% discount.