Clustering is an unsupervised machine learning technique used to group similar data points into clusters or groups without predefined labels. It helps uncover hidden patterns, segment populations, and facilitate exploratory data analysis.
Among many clustering algorithms, K-Means, Hierarchical Clustering, and Density-Based Spatial Clustering of Applications with Noise (DBSCAN) are widely used due to their effectiveness and interpretability.
K-Means Clustering
K-Means is a centroid-based clustering algorithm that partitions data into K clusters by minimizing the within-cluster variance.
How K-Means Works:
1. Randomly initialize K cluster centroids.
2. Assign each data point to the nearest centroid based on a distance metric (usually Euclidean distance).
3. Update centroids by calculating the mean of all assigned points.
4. Repeat assignment and centroid update steps until convergence (i.e., centroids no longer change significantly or maximum iterations reached).
.png)
Applications:
1. Market segmentation
2. Image compression and segmentation
3. Document clustering
Hierarchical Clustering
Hierarchical clustering builds a multilevel hierarchy of clusters by either agglomerating or dividing observations.
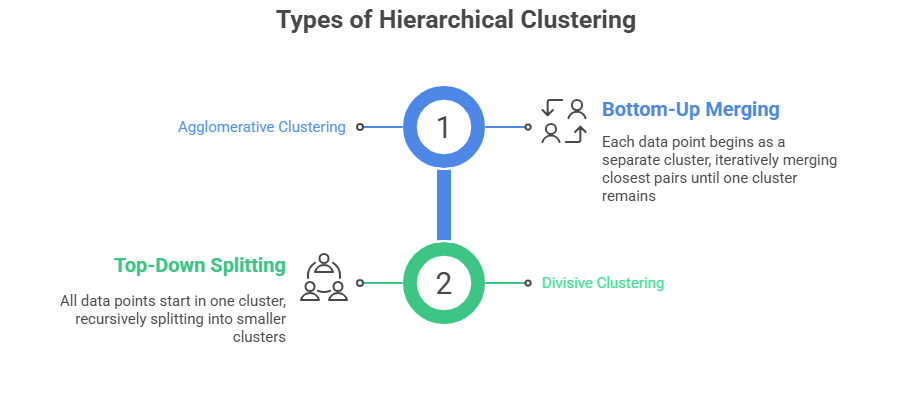
How It Works:
1. Calculate the distance matrix between data points or clusters.
2. Merge or split clusters based on linkage criteria such as single linkage (minimum distance), complete linkage (maximum distance), average linkage, or Ward’s method (minimize variance).
Advantages: The ability to form clusters without needing to predefine their number, making it highly adaptable to different datasets. It also generates a dendrogram that visually represents the relationships and hierarchy among clusters, which helps in understanding data structure. Additionally, it is flexible in terms of linkage methods and distance metrics, allowing it to be tailored to a wide range of analytical needs.
Limitations: High computational cost when applied to large datasets, which can make it inefficient at scale. It is also sensitive to noise and outliers, which may distort the resulting cluster structure. Moreover, there is no simple or definitive method to determine the optimal number of clusters from the hierarchy.
Applications:
1. Genomics and phylogenetics
2. Social network analysis
3. Document and text clustering
DBSCAN (Density-Based Spatial Clustering of Applications with Noise)
DBSCAN is a density-based clustering algorithm that groups points with many nearby neighbors and marks points in low-density regions as noise or outliers.
How DBSCAN Works:
1. For each point, count the number of points within a radius ε (epsilon).
2. Points with neighbors greater than or equal to a minimum points (MinPts) are classified as core points.
3. Points reachable from core points are clustered together.
4. Points not reachable from any core points are labeled as noise.
.png)
Applications:
1. Anomaly detection
2. Spatial data analysis
3. Image analysis

Class Sessions
Sales Campaign

We have a sales campaign on our promoted courses and products. You can purchase 1 products at a discounted price up to 15% discount.