In machine learning, imbalanced datasets pose significant challenges where one class (majority) significantly outnumbers another (minority). This imbalance often leads to biased models that perform well on majority classes but poorly on minority classes, which may be critical in applications such as fraud detection, medical diagnosis, or anomaly detection. Effective handling of imbalanced datasets is vital to achieve fair, accurate, and reliable predictive models.
Introduction to Imbalanced Datasets
An imbalanced dataset means the distribution of classes is skewed, sometimes drastically disparate. Traditional evaluation metrics like accuracy become misleading in such scenarios, necessitating specialised techniques both at the data level and algorithmic level.
Strategies to Handle Imbalanced Data
Here are the main techniques to address imbalanced data and enhance model reliability. These strategies cover dataset balancing, algorithm adjustments, and metrics that properly evaluate minority class predictions.
.png) Resampling modifies the training dataset composition to achieve a more balanced class distribution.
Resampling modifies the training dataset composition to achieve a more balanced class distribution.
1. Oversampling: Increases the number of minority class samples.
Naive oversampling duplicates existing samples, increasing representation.
Smarter techniques like Synthetic Minority Oversampling Technique (SMOTE) create synthetic samples by interpolating between existing minority instances, enhancing diversity while reducing overfitting risk.
2. Undersampling: Reduces the majority class samples.
Random undersampling removes the majority class instances to equalise the distribution.
Risks of losing valuable information and reducing the dataset size.
3. Hybrid Approaches: Combine oversampling and undersampling to balance benefits and minimise drawbacks.
Algorithm-Level Adjustments
Algorithm-level adjustments modify the learning process to handle class imbalance more effectively. Cost-sensitive learning incorporates different misclassification costs for each class, placing greater penalties on errors involving minority classes.
Similarly, class weighting assigns weights inversely proportional to class frequencies during training, ensuring that the model pays more attention to underrepresented classes and improves overall predictive performance.
Ensemble Methods
These methods combine multiple base models to enhance predictive performance, particularly for identifying minority class instances. Techniques such as bagging and boosting focus on learning from hard-to-classify examples, improving the model’s ability to handle imbalanced datasets.
Common ensemble approaches include AdaBoost, Gradient Boosting Machines, and Random Forest, which leverage the strengths of individual models to produce more accurate and robust predictions.
Anomaly Detection Approaches
Anomaly detection approaches handle class imbalance by treating minority classes as anomalies that deviate from the patterns of the majority class. In cases of extreme imbalance, specialised algorithms such as Isolation Forest or One-Class SVM are employed to identify these rare instances, effectively distinguishing them from the predominant class patterns.
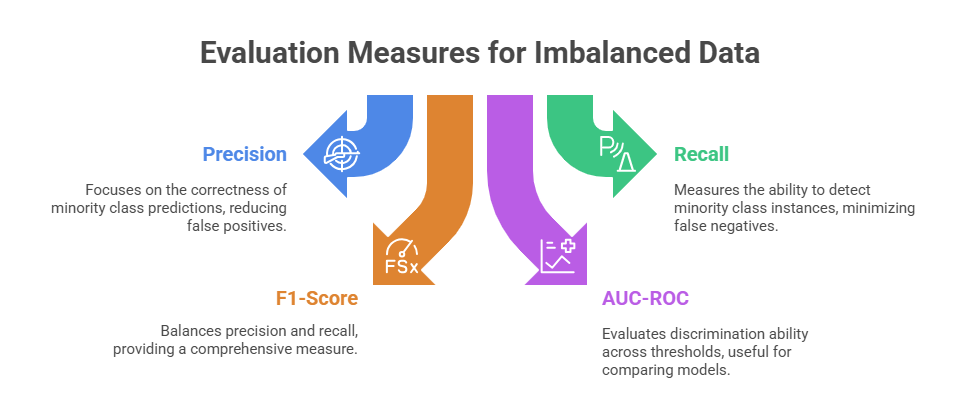
Practical Considerations
1. Analyse dataset characteristics and business needs before choosing techniques.
2. Avoid overfitting the minority class by relying solely on oversampling without validation.
3. Combine multiple strategies for the best results.
4. Use domain knowledge to engineer discriminative features that facilitate minority class prediction.

Class Sessions
Sales Campaign

We have a sales campaign on our promoted courses and products. You can purchase 1 products at a discounted price up to 15% discount.