Model monitoring is an essential practice in machine learning operations that ensures deployed models maintain accuracy, reliability, and relevance over time.
Drift detection—the process of identifying changes in data or model behavior that degrade performance—is a core aspect of monitoring. Effective monitoring and maintenance practices help organizations preempt failures and adapt models to evolving conditions.
Model Monitoring
Once a machine learning model is deployed, its real-world input data and environment can change, causing the model’s performance to deteriorate.
Monitoring tracks model outputs, input data distribution, and performance metrics continuously or periodically to detect anomalies or shifts signaling drift. Timely detection is critical to trigger retraining, recalibration, or other corrective actions that preserve model effectiveness.
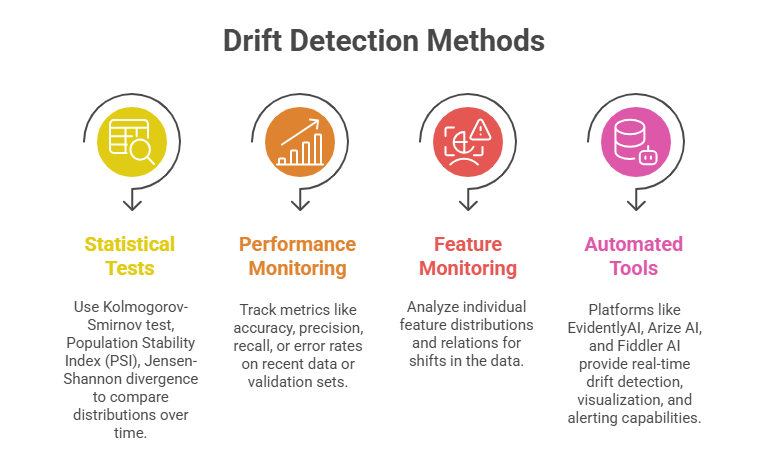
Types of Drift in Machine Learning
Below are the key forms of drift that can impact model reliability over time. Each type highlights how real-world changes can shift data patterns or model behavior.
1. Data Drift: Changes in input feature distributions compared to training data. It signals that the model encounters data unlike what it learned.
2. Concept Drift: Changes in the relationship between input features and target variables, making prior patterns less valid.
3. Prediction Drift: Variations in model output distributions that may indicate underlying data or concept drift.
4. Feature Attribution Drift: Situations where the importance or contribution of features changes over time despite stable input distributions.
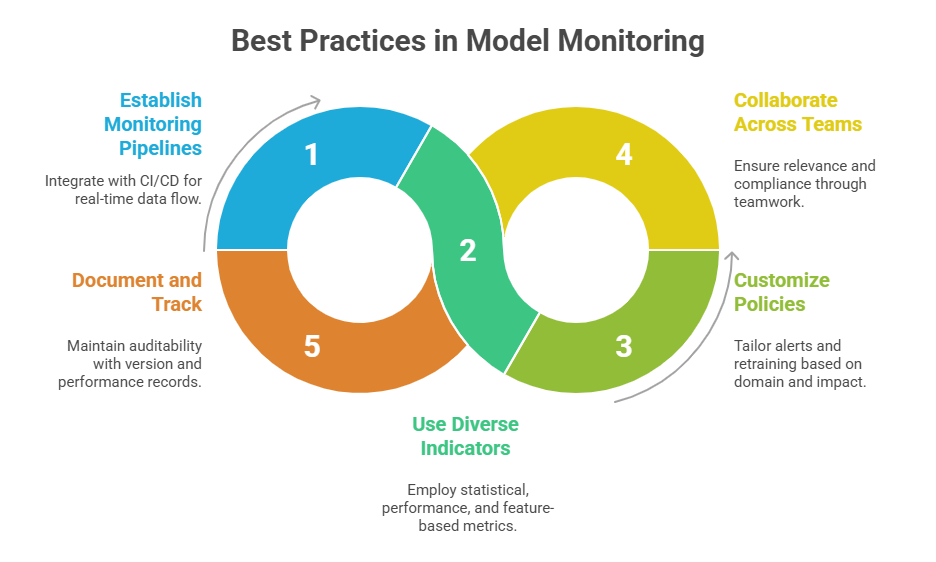
Maintenance and Mitigation Strategies
Here are various maintenance practices designed to combat drift and preserve long-term model performance. These solutions combine alerting mechanisms, retraining workflows, and data-quality safeguards.
1. Alerts and Thresholds: Setting adaptive thresholds on monitored metrics to avoid false positives while enabling timely response.
2. Retraining Models: Periodic or triggered retraining using fresh data to cope with drift.
3. Incremental Learning: Continuously integrating new data to update the model without full retraining.
4. Ensemble and Adaptive Models: Combining multiple models or adapting dynamically to evolving data.
5. Data Validation and Quality Checks: Ensuring incoming data integrity to avoid spurious drift signals.

Class Sessions
Sales Campaign

We have a sales campaign on our promoted courses and products. You can purchase 1 products at a discounted price up to 15% discount.