In machine learning, data preprocessing is essential for preparing raw data into a form that algorithms can effectively use. Two critical preprocessing steps are encoding categorical variables and scaling numerical features. Encoding converts categorical data into numerical values since most machine learning algorithms require numeric input. Scaling standardizes the range of numerical features to improve convergence and model performance.
Encoding Categorical Variables
Categorical variables represent data points that fall into discrete categories, such as gender, color, or product type. Because machine learning models are mathematically designed to process numbers, categorical data must be converted into numeric representations — a process called encoding.
Common Encoding Techniques
1. Label Encoding
Assigns each category a unique integer label (e.g., ‘Red’ → 1, ‘Blue’ → 2).
Suitable when categories have an ordinal (ordered) relationship.
Simple and memory-efficient.
Potential drawback: may imply a false ordinal relationship for nominal categories.
2. One-Hot Encoding
Converts each category into a binary vector where each column represents one category.
Avoids implicit order by creating separate columns with 0s and 1s.
Widely used with nominal data.
Can lead to high dimensionality with many categories.
3. Ordinal Encoding: Similar to label encoding but explicitly used when the categorical variable has a meaningful order (e.g., ‘Low’, ‘Medium’, ‘High’).
4. Target Encoding
Replaces categories with the mean of the target variable for that category.
Useful for high-cardinality features.
Risks of overfitting; smoothing or cross-validation techniques are recommended.
5. Binary Encoding
Converts categories to binary numbers and splits them into multiple columns.
Memory-efficient for high-cardinality data.
More complex, but reduces dimensionality compared to one-hot encoding.
Scaling Numerical Features
Numerical features often come with widely different ranges and units, which can bias machine learning models. Scaling transforms features to a standard scale, improving model training speed and accuracy.
Common Scaling Techniques
1. Min-Max Scaling (Normalization)
Transforms data to fit within a fixed range, usually.
Formula: ![]()
Preserves relative distances but is sensitive to outliers.
2. Standardization (Z-score Scaling)
Centers data around the mean with unit variance.
Formula: ![]()
Works well with algorithms assuming a Gaussian distribution.
3. Robust Scaling
Uses median and interquartile range, making it robust to outliers.
Suitable for datasets with many anomalies.
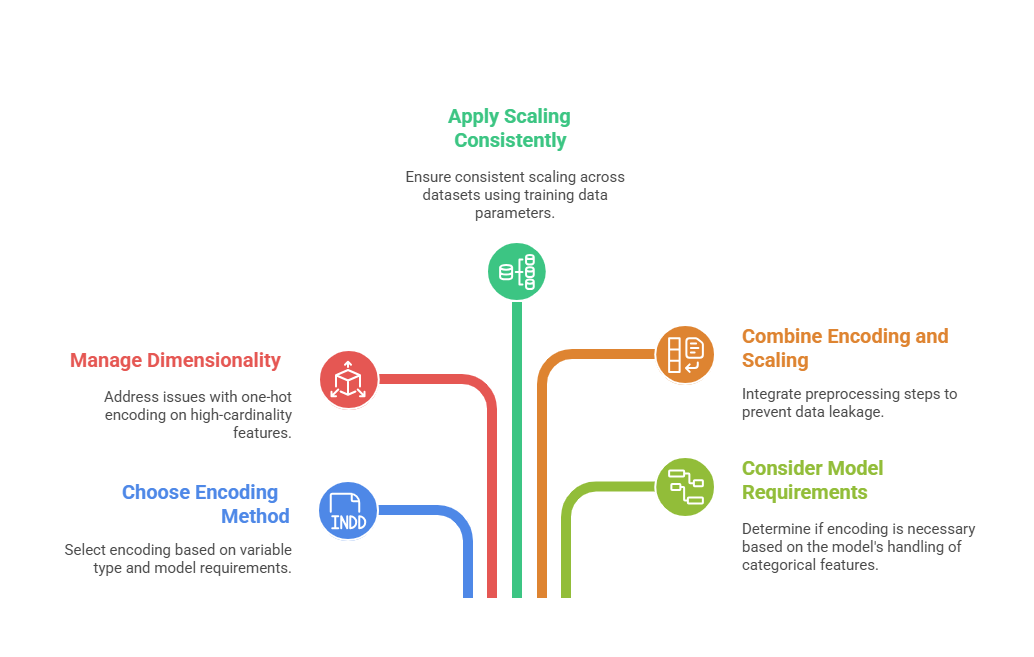
Best Practices and Considerations
Effective data preparation involves balancing model requirements, feature properties, and pipeline consistency. Outlined here are best practices that support robust and well-structured preprocessing workflows.

Class Sessions
Sales Campaign

We have a sales campaign on our promoted courses and products. You can purchase 1 products at a discounted price up to 15% discount.