Feature engineering is a critical step in machine learning that involves transforming raw data into meaningful inputs for models to improve their performance and accuracy. Two fundamental approaches within feature engineering are feature selection and feature extraction.
While both aim to reduce dimensionality and highlight relevant information, they differ significantly in their methodologies and outcomes. Understanding these differences helps practitioners choose the right approach according to the data characteristics and problem requirements.
Introduction to Feature Engineering
Feature engineering enhances the dataset by either selecting the most relevant original features or by creating new, more informative features from existing data. This process streamlines model training, reduces complexity, and often results in better predictive accuracy and interpretability.
Feature Selection
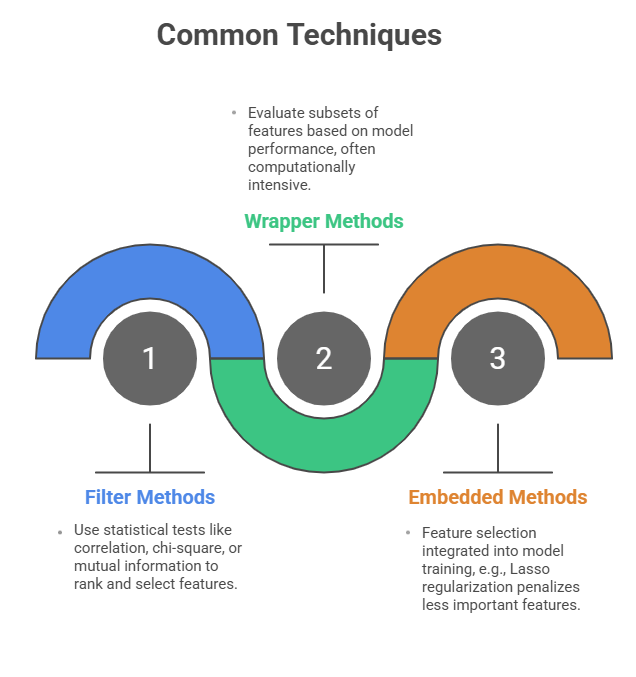
Feature selection involves choosing a subset of relevant features from the original dataset without altering their nature. The goal is to remove irrelevant, redundant, or noisy features that do not contribute to or may even degrade the model's predictive power.
Key Points:
1. Works by retaining original features only.
2. Reduces dimensionality by discarding unimportant features.
3. Improves model interpretability and training efficiency.
4. Helps prevent overfitting by eliminating noise.
5. Requires domain knowledge or algorithmic criteria to identify key features.
Feature Extraction
Feature extraction transforms the original features into a new set of features by combining or projecting them into a different space. It aims to create informative features that capture intrinsic patterns or hidden structures, especially useful in high-dimensional or complex data.
Key Points:
1. Creates new features rather than selecting existing ones.
2. Reduces dimensionality by transformation or projection.
3. Can uncover latent relationships and improve model performance.
4. Often, less interpretable new features may not have a direct meaning.
5. Essential when dealing with complex data like images, text, or signal data.
.png)
Best Practices
A thoughtful approach to feature engineering strengthens model performance and simplifies analysis. Here’s a list of practical recommendations to help you choose the right technique.
1. Use feature selection when you need simplicity, speed, and interpretability.
2. Opt for feature extraction when dealing with large, complex datasets requiring dimensionality reduction.
3. Combine both approaches when beneficial, such as selecting important features before extraction.
4. Evaluate model performance with different techniques to choose the best approach.
5. Consider domain expertise to guide feature engineering decisions.

Class Sessions
Sales Campaign

We have a sales campaign on our promoted courses and products. You can purchase 1 products at a discounted price up to 15% discount.