Pattern mining in data science involves uncovering interesting relationships, connections, and associations within large datasets. Among various techniques, association rule mining and market basket analysis are prominent methods used to identify frequent patterns, correlations, and co-occurrences in transactional data.
These methods are widely exploited in retail, e-commerce, and beyond to optimize cross-selling strategies, inventory management, and recommendation systems.
Introduction to Association Rules and Market Basket Analysis
Association rule mining focuses on discovering interesting relations between variables across large datasets. Market Basket Analysis (MBA), a specific application of association rules, analyzes customer purchase data to identify items that are frequently bought together.
It helps businesses understand buying behavior, which can inform marketing, sales, and merchandising strategies. The core goal is to extract rules that reliably indicate the likelihood of the co-occurrence of items or events.
Key Concepts in Association Rule Mining
1. Support: The proportion of transactions that contain a specific itemset.
Purpose: Measures the popularity or frequency of an item or combination.
Example: If 30% of transactions include bread, support for bread is 0.3.
2. Confidence: The probability that a transaction containing item A also contains item B.
Formula: ![]()
Purpose: Indicates the strength of a rule, i.e., how often B appears when A appears.
3. Lift: The ratio of the observed support for A and B appearing together to what would be expected if A and B were independent.
Formula: ![]()
Purpose: Measures the interestingness of a rule; lift > 1 indicates a positive association.
Market Basket Analysis
Market Basket Analysis applies association rule mining to transactional datasets, typically sales data, to identify itemsets frequently bought together. The insights guide:
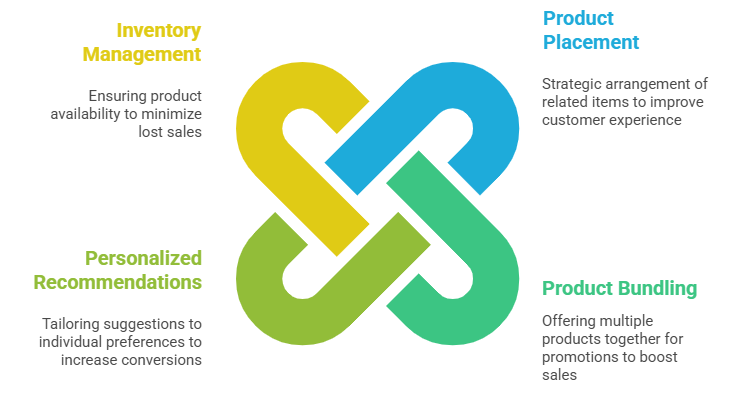
Techniques for Mining Association Rules
Association rule mining enables insights into co-occurrence and dependencies among items. The following techniques highlight efficient approaches for extracting frequent itemsets.
1. Apriori Algorithm
A classic method that uses support thresholds to identify frequent itemsets iteratively.
Starts with single items, then combines to find larger frequent itemsets.
Prune itemsets with support below the threshold, reducing computational complexity.
2. Eclat Algorithm
Uses a depth-first search with a vertical data format.
More efficient than Apriori on dense datasets.
Focuses on intersecting transaction lists to find frequent itemsets.
3. FP-Growth Algorithm
Constructs a compact data structure called FP-tree.
Extracts frequent itemsets directly from the FP-tree without candidate generation.
Faster and more scalable for large datasets.

Limitations and Challenges
Even with powerful algorithms, association rule mining faces hurdles that affect efficiency and relevance. Here are the primary limitations and challenges to keep in mind during analysis.
1. Support Thresholds: Setting support thresholds too high might miss interesting rules; too low can result in overwhelming, irrelevant rules.
2. Computational Complexity: Large datasets require significant processing power.
3. Interpretability: Not all rules are meaningful; business context is needed for filtering and validation.
4. Dynamic Data: Evolving patterns require frequent reassessment.
Future Directions
Advanced techniques involve integrating association rule mining with machine learning models to enhance recommendation systems. Deep learning methodologies and real-time analytics are also being explored to improve pattern discovery in increasingly complex datasets.

Class Sessions
Sales Campaign

We have a sales campaign on our promoted courses and products. You can purchase 1 products at a discounted price up to 15% discount.