In machine learning, the goal is to build models that generalize well to unseen data. Achieving this requires proper model evaluation and optimization techniques that minimize overfitting and underfitting. Cross-validation and hyperparameter tuning are two essential methods used to assess model performance reliably and find the best model configurations. Understanding these techniques is vital for building robust, high-performing models.
Introduction to Cross-Validation
Cross-validation is a statistical method used to estimate the performance of machine learning models on independent datasets. It helps assess how the results of a model will generalize to an unseen dataset and prevents overoptimistic performance estimates based on a single train-test split.
Common Cross-Validation Techniques:
1. k-Fold Cross-Validation
Data is divided into k equal-sized subsets or "folds."
The model is trained on k-1 folds and tested on the remaining fold.
This process repeats k times, with each fold used exactly once for testing.
Performance metrics are averaged over the k iterations for robust evaluation.
Commonly used when data sizes are moderate.
2. Stratified k-Fold Cross-Validation
A variation of k-fold suitable for classification tasks
Ensures each fold preserves the original class proportions.
Prevents imbalanced folds that could bias performance metrics.
3. Leave-One-Out Cross-Validation (LOOCV)
Special case of k-fold where k equals the number of samples.
Each observation is used once as the test set, while the rest form the training set.
Provides nearly unbiased estimates, but computationally expensive for large datasets.
4. Repeated Cross-Validation
Repeats k-fold cross-validation multiple times with random data splits.
Provides more reliable estimates by reducing variability due to data partitioning.
Introduction to Hyperparameter Tuning
Hyperparameters are configuration settings external to the model learned during training, such as regularization strength, learning rate, or number of trees in a random forest. Selecting optimal hyperparameters is crucial as they significantly affect model accuracy and stability.
Hyperparameter Tuning Methods:
1. Grid Search
Exhaustively searches a predefined set of hyperparameter values.
Evaluates model performance at each combination using cross-validation.
Simple but computationally expensive for large search spaces.
2. Random Search
Randomly samples hyperparameter combinations from specified distributions.
More efficient than grid search as it can explore broader spaces with fewer evaluations.
Often yields comparable or better results with fewer resources.
3. Bayesian Optimization
Uses probabilistic models to predict the best hyperparameters.
Balances exploration and exploitation to efficiently navigate the search space.
Provides an intelligent method to find optimal parameters, especially with expensive-to-evaluate models.
4. Gradient-Based Optimization
Differentiates model performance with respect to hyperparameters.
Used in some neural network architectures for automated tuning.
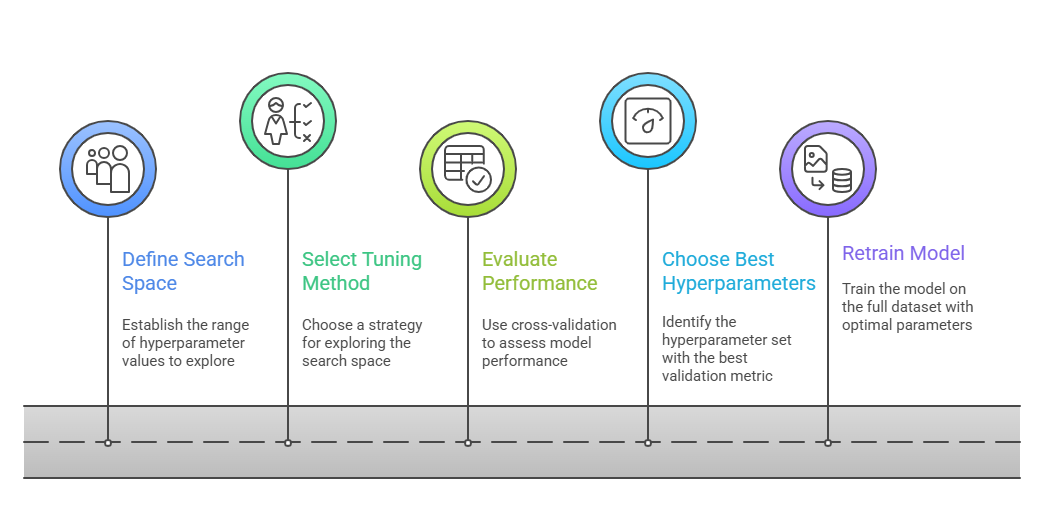
Hyperparameter Tuning Workflow
To achieve peak model performance, hyperparameters must be tuned in a methodical and data-driven manner. Below is an overview of the core steps commonly followed during the tuning cycle.
 Best Practices
Best Practices
To get the most out of your tuning efforts, it’s important to combine technique, efficiency, and domain insight. Here’s a list of practical recommendations that support smarter hyperparameter searches.
1. Combine cross-validation with hyperparameter tuning to prevent overfitting.
2. Monitor computational resources and balance thoroughness with efficiency.
3. Use domain knowledge to narrow down hyperparameter ranges.
4. Consider early stopping criteria to save training time in iterative tuning.

Class Sessions
Sales Campaign

We have a sales campaign on our promoted courses and products. You can purchase 1 products at a discounted price up to 15% discount.