Computer vision enables machines to interpret and understand visual information from images or videos, mimicking human vision abilities. Convolutional Neural Networks (CNNs) have become the cornerstone architecture for computer vision, revolutionizing how machines recognize, classify, and analyze images by learning hierarchical feature representations directly from raw pixel data.
Introduction to CNNs in Computer Vision
CNNs are specialized deep learning networks designed to process grid-like data structures such as images. Their architecture is inspired by the human visual cortex, focusing on local patterns through convolutional filters that capture spatial relationships between pixels. CNNs automate feature extraction, eliminating the need for manual design of features traditionally required in image processing.
Key Components of CNNs
Listed below are the primary structural components that give CNNs their powerful feature-learning capabilities. Understanding these parts explains how CNNs transform raw images into meaningful outputs.
1. Convolutional Layers
These layers apply a set of learnable filters or kernels that slide over the input image, performing element-wise multiplications and summations to produce feature maps. Each kernel detects specific local features like edges, textures, or shapes. Multiple filters allow the network to capture diverse visual patterns at various levels of abstraction.
2. Activation Functions
Non-linear functions like ReLU (Rectified Linear Unit) are applied after convolution to introduce non-linearity, enabling the network to model complex functions and hierarchies beyond simple linear transformations.
3. Pooling Layers
Pooling simplifies feature maps by downsampling spatial dimensions, reducing computational load and enhancing feature robustness. Max pooling, which selects the maximum value from a region, is commonly used to preserve the most significant features.
4. Fully Connected Layers
Positioned towards the end of the network, these layers integrate extracted features to make final predictions. They connect every neuron in one layer to every neuron in the next, translating spatial feature maps into output classes for classification tasks.
How CNNs Work
The following points outline the process through which CNNs convert input images into final outputs. This workflow reveals the layered transformation that drives deep visual understanding.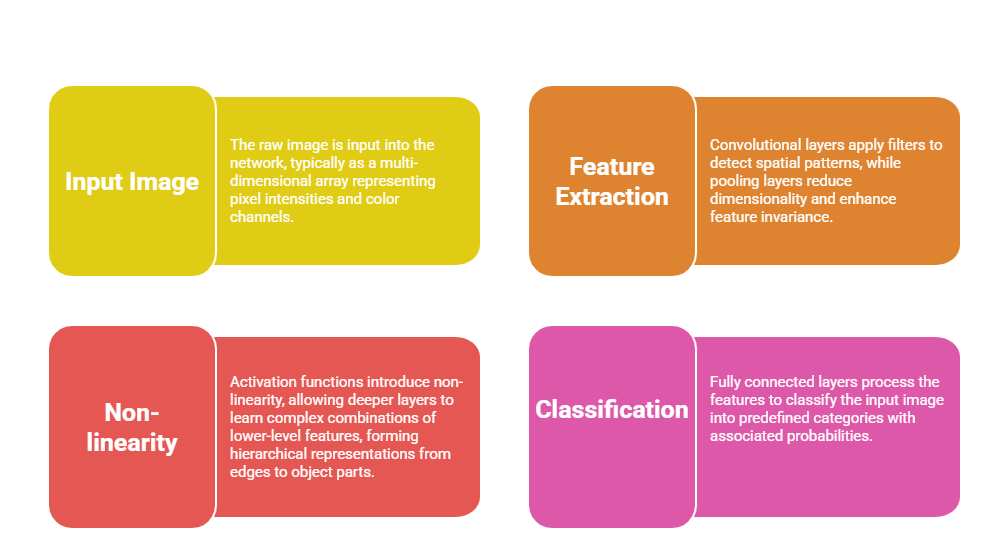
Advantages of CNNs in Computer Vision
Here are the essential advantages that distinguish CNNs from traditional machine-learning models in vision. They demonstrate how CNNs leverage spatial hierarchies and automatic learning for superior performance.
1. Automatic Feature Learning: CNNs learn optimal filters during training, removing the need for manual feature engineering.
2. Spatial Hierarchy: They preserve spatial information, capturing local and global patterns through layered processing.
3. Robustness and Translation Invariance: Pooling layers help models tolerate minor shifts and distortions in images.
4. Scalability: CNNs effectively process large image datasets with millions of parameters learnable via backpropagation.
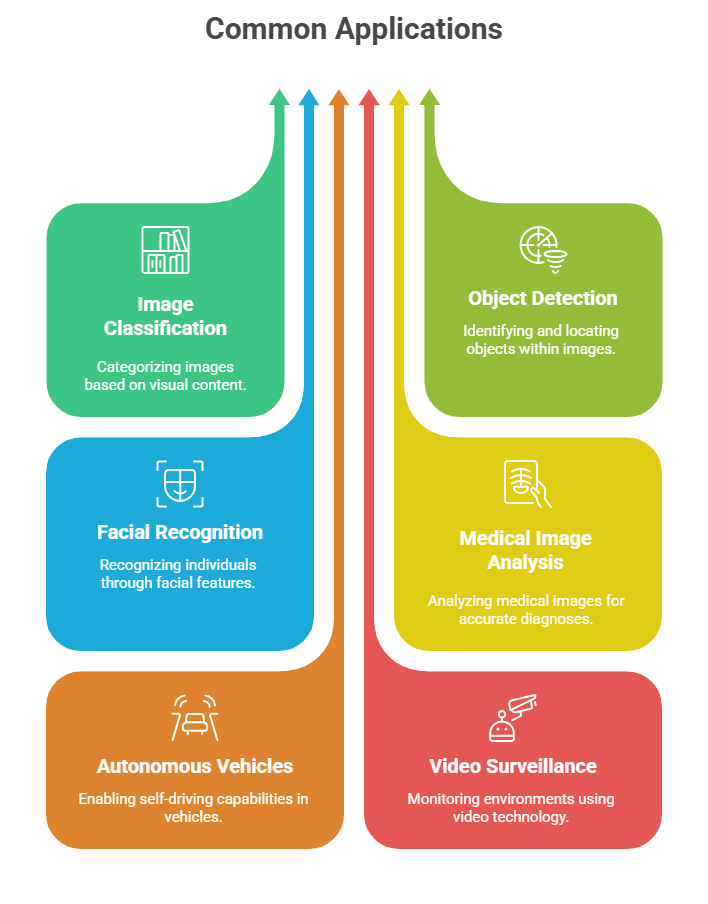

Class Sessions
Sales Campaign

We have a sales campaign on our promoted courses and products. You can purchase 1 products at a discounted price up to 15% discount.