Data augmentation is a fundamental technique in machine learning aimed at increasing the diversity and size of training datasets by creating modified versions of existing data. This approach addresses challenges such as limited data availability, class imbalance, and overfitting by introducing controlled variations that help models generalize better to unseen data.
Augmentation techniques differ depending on the type of data—tabular, image, or text—each requiring tailored strategies to preserve data integrity while enhancing variability.
Introduction to Data Augmentation
Machine learning models perform best when trained on large, diverse datasets that capture the range of possible real-world variations. However, collecting sufficient data is often costly or impractical.
Data augmentation artificially expands datasets without acquiring new data by applying transformations that alter existing samples while preserving their original labels or meaning. This enriches the training process by exposing models to varied instances, improving robustness and predictive accuracy.
Data Augmentation for Tabular Data
Tabular data consists of structured rows and columns commonly found in spreadsheets and databases. Augmentation here must maintain logical consistency across features.
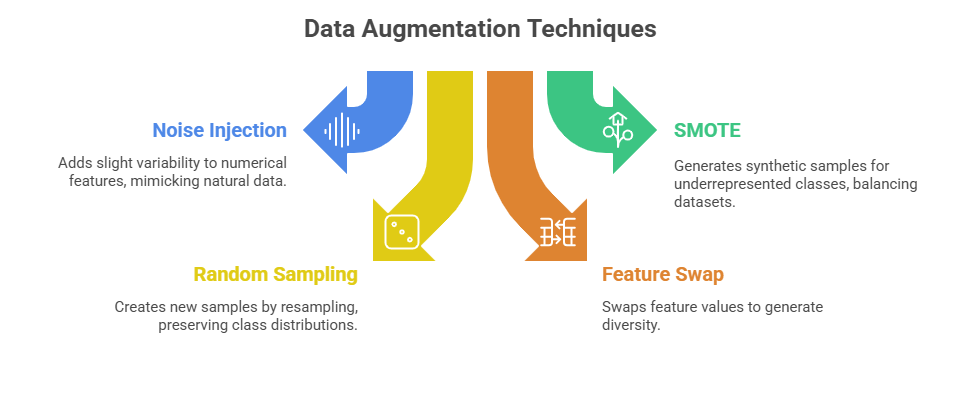
Considerations:
1. Maintain feature relationships and constraints (e.g., age must remain positive).
2. Avoid introducing unrealistic or impossible data points.
3. Evaluate augmented data with domain knowledge to ensure relevance.
Data Augmentation for Image Data
Image augmentation is widely used to increase training data size and improve computer vision models’ robustness against variations such as rotations, lighting, or occlusions.
.png)
Benefits:
1. Helps models become invariant to orientation, scale, and illumination.
2. Reduces overfitting by presenting varied but semantically equivalent images.
3. Facilitates augmentation on the fly during training, reducing storage needs.
Data Augmentation for Text Data
Textual data augmentation improves natural language processing (NLP) models by diversifying language inputs while preserving semantic meaning.
.png)
Considerations:
1. Preserve grammatical correctness and semantic coherence.
2. Avoid introducing bias or changing the original meaning.
3. Balance augmentation to prevent over-representation of synthetic data.
