Attention mechanisms have emerged as a groundbreaking innovation in artificial intelligence and machine learning, particularly within deep learning models. Inspired by human cognitive processes of selectively focusing on salient stimuli, attention mechanisms enable models to dynamically highlight important parts of input data, leading to improved performance, interpretability, and efficiency.
Introduction to Attention Mechanism
Traditional neural networks process inputs uniformly, treating every element with equal importance regardless of contextual relevance. Attention mechanisms counter this limitation by assigning different weights or “attention scores” to each part of the input, allowing the model to prioritize crucial information.
This selective processing mimics human attention, improving the model’s ability to focus on meaningful patterns, especially in long sequences or complex data.
How the Attention Mechanism Works
The core idea is to compute attention weights that represent the relevance of each input element relative to a given context or query. This involves three key components:
Query: Represents the current focus or task context (e.g., a specific word to be predicted).
Key: Encodes information about elements in the input sequence.
Value: Holds the actual representations or embeddings to be weighted and combined.
The attention mechanism calculates compatibility scores between the query and each key using similarity metrics (e.g., scaled dot-product). These scores are normalized into probabilities via softmax to form attention weights. The output is computed as a weighted sum of the values, emphasizing the most relevant information.
Variants of Attention Mechanisms
The following points highlight different forms of attention used in deep learning. Each type is designed to handle dependencies and relationships within data effectively.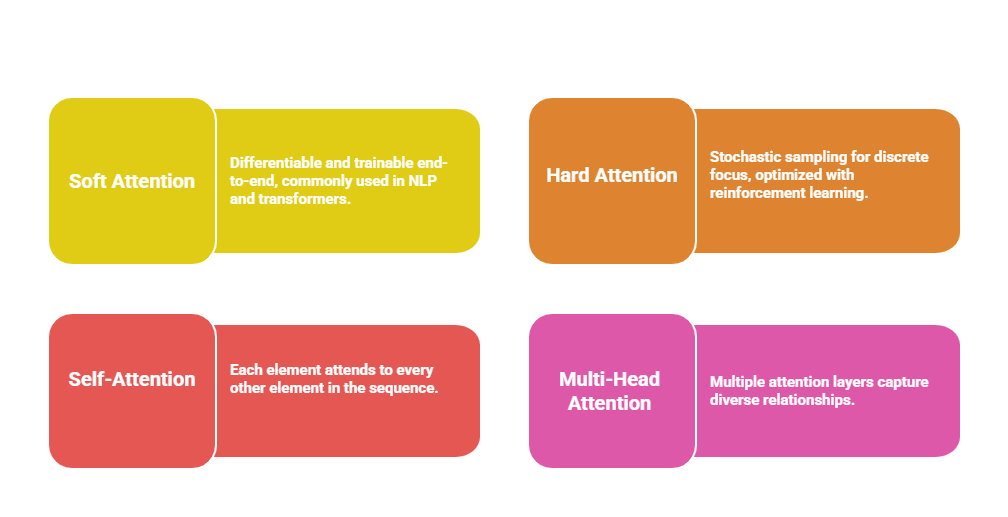
Importance and Benefits of Attention
Listed below are the core reasons attention mechanisms are widely used in AI models. These features enable better generalization, efficient processing, and interpretability.
1. Improved Performance: By focusing on critical parts of input, models achieve higher accuracy and generalization.
2. Handling Long Sequences: Overcomes limitations of prior architectures struggling with distant dependencies by allowing direct connections between any parts of the input.
3. Model Interpretability: Attention weights provide insights into what the model considers important, enhancing transparency.
4. Efficiency: Focused computation reduces wasteful processing of irrelevant data components.

Class Sessions
Sales Campaign

We have a sales campaign on our promoted courses and products. You can purchase 1 products at a discounted price up to 15% discount.