In machine learning, effective data splitting is essential to build models that generalize well to new, unseen data. Splitting data into distinct subsets—training, validation, and test sets—ensures that models are trained, tuned, and evaluated fairly without overfitting or bias. This structured approach provides reliable estimates of model performance and aids in selecting the best model and hyperparameters before deployment.
Data Splitting
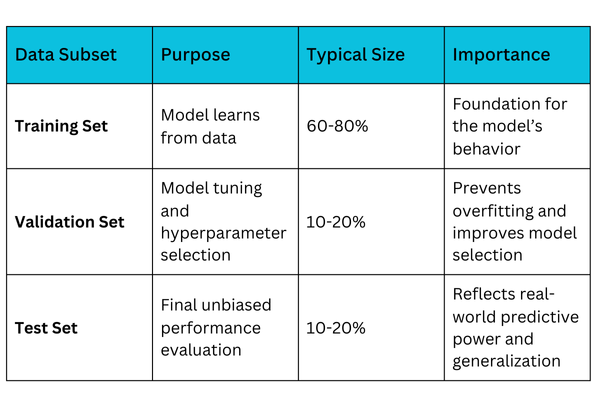
Data splitting divides the original dataset into separate parts to allow independent phases of model development:
1. Training set: Used to train the machine learning model, enabling it to learn patterns and relationships in the data.
2. Validation set: Used during training to tune hyperparameters and optimize model performance, preventing overfitting.
3. Test set: Reserved for final evaluation to assess how the model performs on completely unseen data, simulating real-world usage.
Purpose of Each Set
Common Data Splitting Techniques
Data splitting forms the backbone of model training and validation, helping prevent overfitting and skewed results. Here’s a list of common approaches used to divide datasets effectively.
1. Random Splitting: The dataset is randomly divided into training, validation, and test sets. This simple method works well with large, balanced datasets but may not preserve class proportions, leading to bias in imbalanced data scenarios.
2. Stratified Splitting: Stratified splitting maintains the original class distribution across all subsets. It is vital for classification problems with imbalanced classes, ensuring that rare classes are adequately represented in each set and the model learns all patterns effectively.
3. Time-based Splitting: Used for time series or sequential data, this method splits data chronologically. The model is trained on past data and validated or tested on future unseen data, simulating realistic prediction scenarios and avoiding information leakage.
Practical Considerations
In practice, data partitioning involves more than ratios—it demands safeguards that prevent bias and leakage. Outlined here are essential considerations to ensure robust and consistent model assessment.
.png) Example Workflow
Example Workflow
1. Shuffle the dataset to remove ordering bias.
2. Split the data based on the chosen strategy (random, stratified, etc.).
3. Use the training set for model fitting.
4. Use the validation set for hyperparameter tuning and early stopping.
5. After finalizing the model, evaluate the test set to estimate generalization.

Class Sessions
Sales Campaign

We have a sales campaign on our promoted courses and products. You can purchase 1 products at a discounted price up to 15% discount.