Data is fundamental to machine learning, analytics, and business intelligence. Understanding the distinctions among structured, unstructured, and semi-structured data is key to selecting appropriate storage, processing, and analysis methods. Each data type has unique attributes and challenges, influencing how organizations collect, manage, and extract value from data.
Structured Data
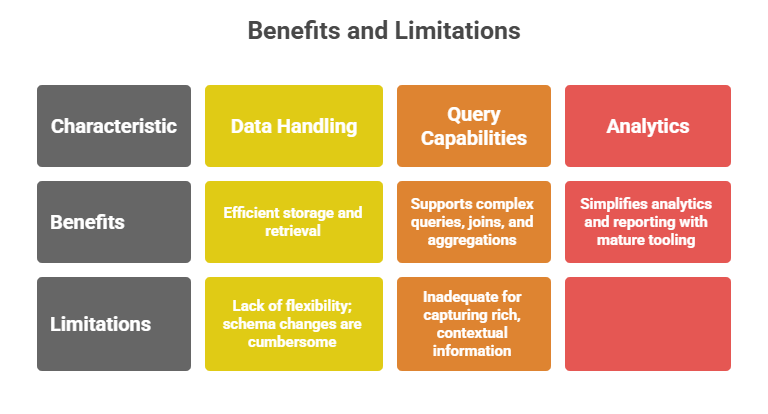
Structured data is highly organized and easily searchable in traditional databases.
Characteristics:
1. Organized in fixed fields within records, often stored as rows and columns in relational databases.
2. Easily searchable using standard query languages like SQL.
3. Highly suitable for numerical, categorical, and transactional information.
Examples: Customer databases, product inventories, and financial records.
Unstructured Data
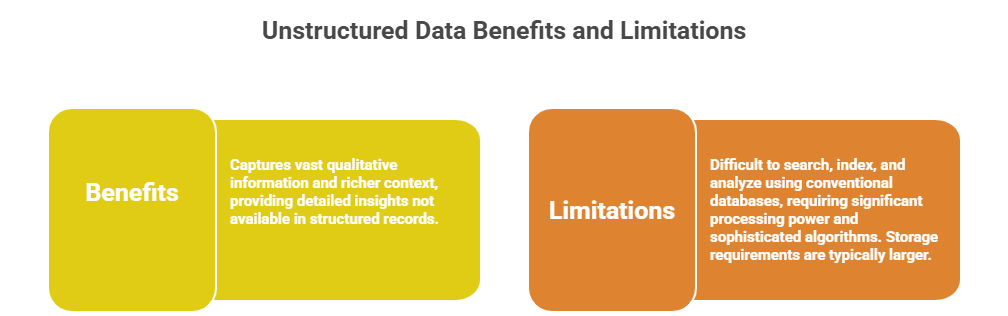
Unstructured data lacks a predefined format, encompassing vast and diverse formats like text, images, and videos
Characteristics:
1. No predefined format or organizational schema.
2. Includes text documents, emails, images, audio, video, social media posts, sensor data, etc.
3. Requires advanced processing techniques like NLP, computer vision, or speech recognition.
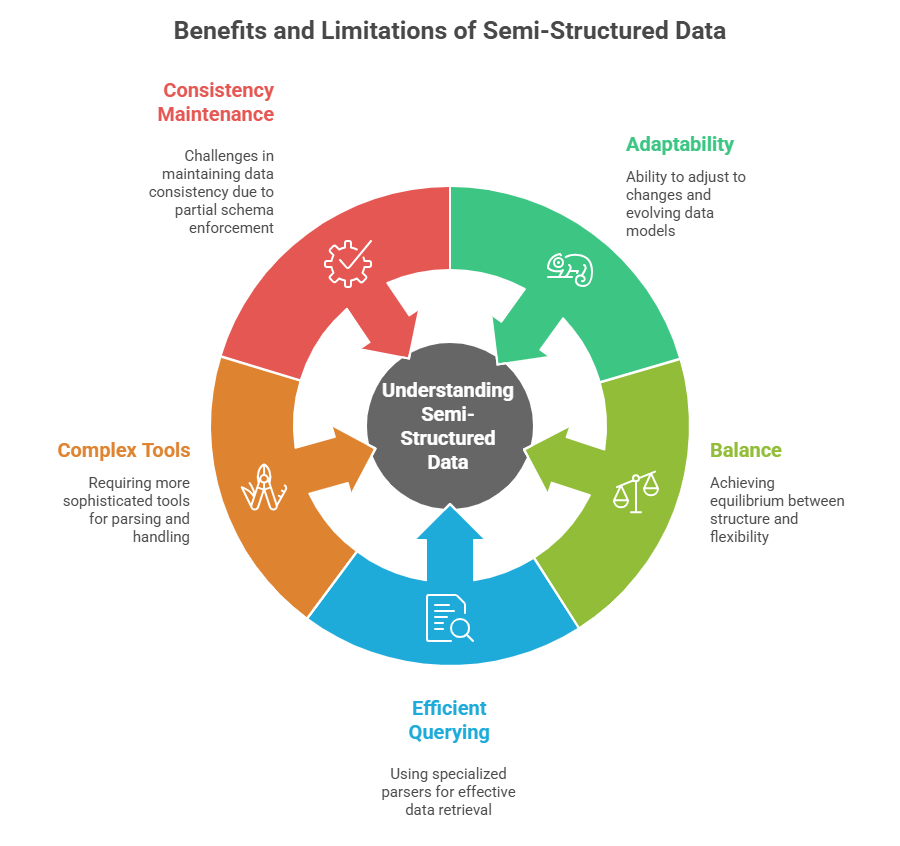
Semi-Structured Data
Semi-structured data bridges these two extremes, possessing organizational elements but without rigid tabular schemas.
Characteristics:
1. Contains organizational properties through metadata or tags without strict relational schemas.
2. Formats include JSON, XML, YAML, and NoSQL databases.
3. More flexible and extensible than structured data, yet easier to analyze than unstructured data.