Types of data explain how information is organized and represented in data science and machine learning.
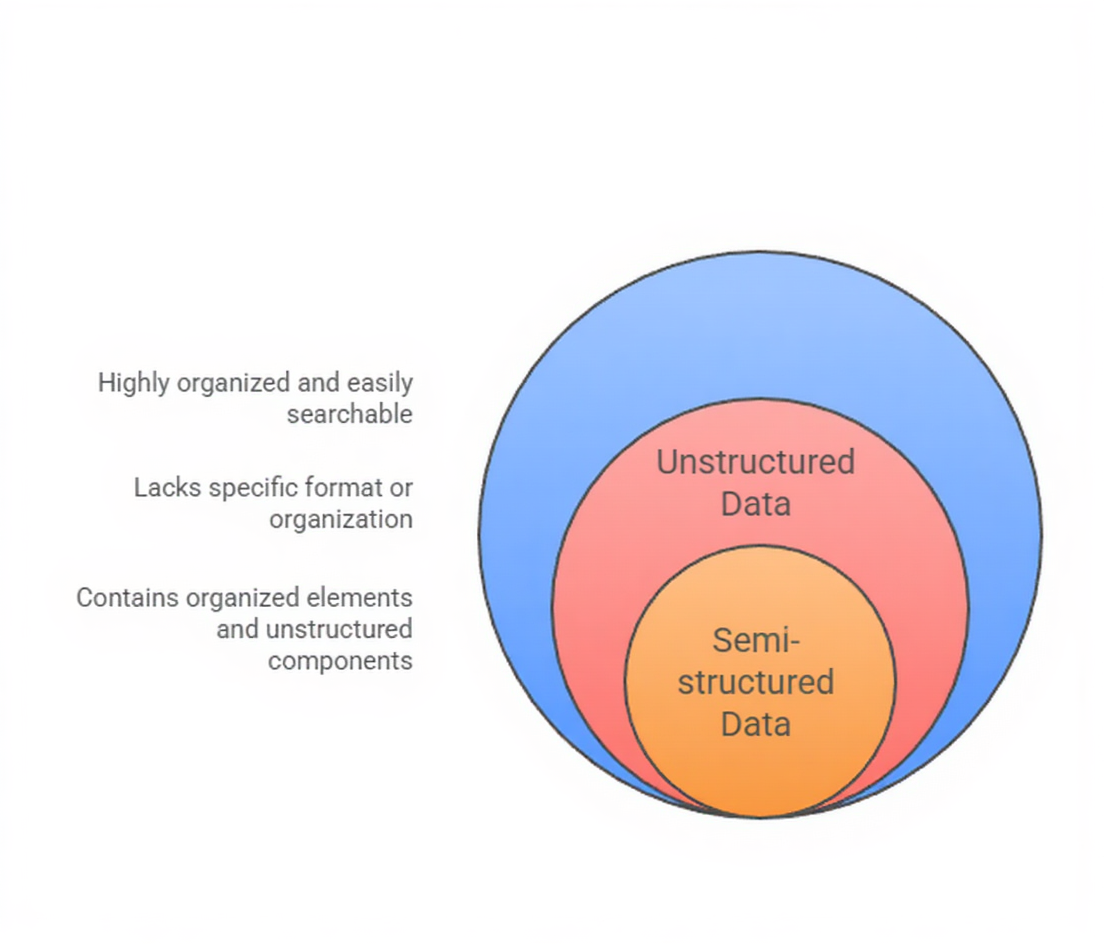
Data can be structured, unstructured, or semi-structured, and each type requires different methods for storage, processing, and analysis.
Understanding these data types helps learners work effectively with real-world datasets and apply suitable techniques in practical projects.
Types of Data
 1. Structured Data
1. Structured Data
Structured data refers to information organized in a predefined manner, usually in rows and columns.
It follows a fixed schema that clearly defines variables and their relationships.
This is the type of data most commonly used in classic machine learning models because it is easy to query, manipulate, and store in databases.
Examples
1. Customer purchase records stored in tables
2. Sensor readings in time-series format
3. Loan application details with numerical and categorical attributes
4. Healthcare patient records in a database
5. CSV or Excel datasets used for supervised learning
2. Unstructured Data
Unstructured data lacks a consistent format, making it difficult to store in traditional relational databases.
It often comes from natural human activity, digital content, or multimedia sources.
Advanced techniques like NLP, computer vision, and deep neural networks are typically used to process this data.
Examples
1. Text from emails, reviews, and social media posts
2. Images used for image recognition models
3. Audio recordings for speech-to-text systems
4. Video logs for action classification
5. Chat transcripts for sentiment analysis
3. Semi-Structured Data
Semi-structured data falls between structured and unstructured formats.
It does not follow a rigid schema, but contains tags, hierarchies, or markers that make it partially organized. It is widely used in modern pipelines, especially for web data, logs, and NoSQL systems.
Examples
1. JSON files from APIs
2. XML data used in web scraping
3. Log files from servers or ML pipelines
4. NoSQL documents from MongoDB
5. Metadata from images or videos
Data Types and Their Role in ML Systems
Real-world data rarely comes in a single format, making data type awareness a critical skill for data scientists.
From databases to text, images, and logs, each data type shapes how models are built and deployed.
1. Importance of Structured Data in Machine Learning
Structured data forms the backbone of traditional machine learning tasks such as regression, classification, and clustering.
Since the data is already organized, preprocessing becomes faster and more efficient. Analysts can easily perform statistical checks, detect patterns, and plug data into algorithms.
Structured datasets are also helpful in benchmarking, as they maintain consistency across experiments.
Many real-world applications like fraud detection, credit scoring, and forecasting rely heavily on structured data.
Furthermore, structured data works well with relational databases that support optimized querying.
This makes it ideal for solutions requiring accuracy, repeatability, and clear interpretability.
2. Challenges and Opportunities with Unstructured Data
Unstructured data is massive in volume and continues to grow through digital interactions and automation.
Although harder to process, it offers rich context that structured data cannot provide.
Machine learning models such as transformers, CNNs, and LSTMs excel at extracting meaning from unstructured information.
However, these tasks require heavy computational power, specialized preprocessing, and larger datasets. Unstructured data helps organizations understand human behavior, emotions, and visual content.
When processed effectively, it leads to advanced applications like chatbots, facial recognition, and document classification.
Despite its complexity, unstructured data is essential for next-generation AI systems.
3. Advantages of Semi-Structured Data in Real-World Pipelines
Semi-structured data provides flexibility while still retaining some level of organization.
This allows it to adapt to changes without redesigning entire schemas. It’s common in projects involving APIs, cloud services, and distributed systems.
Machine learning workflows benefit from semi-structured formats because they integrate smoothly with modern storage tools like NoSQL databases.
These datasets often contain metadata that accelerates extraction, parsing, and feature engineering.
The flexible structure supports scalability and rapid iteration, especially in dynamic environments where format consistency cannot be guaranteed.
Semi-structured data serves as a bridge between the rigidness of structured data and the unpredictability of unstructured content.
4. Why Different Data Types Matter in Data Science Projects
Every stage of a machine learning pipeline—from data ingestion to model deployment—depends heavily on the type of data involved.
Different formats require different preprocessing workflows, tools, and algorithms.
Understanding data types allows teams to choose suitable storage systems and analytical methods.
Structured data may need encoding or scaling, while unstructured data might require embedding techniques or neural networks.
Semi-structured data demands parsing tools that can interpret hierarchies.
These differences also affect project timelines, model complexity, and resource allocation.
Recognizing data types early in a project ensures accuracy, efficiency, and proper system design.
5. Storage Systems and Tools for Various Data Formats
Different data types benefit from different storage solutions.
Structured data aligns well with relational databases like MySQL or PostgreSQL, which enforce consistency and allow complex querying.
Unstructured data works better with data lakes, cloud object storage, and distributed file systems.
Semi-structured data is suited for flexible NoSQL solutions such as MongoDB, Elasticsearch, or DynamoDB.
Selecting the right storage medium influences performance, scalability, and retrieval efficiency.
These decisions also impact the kind of pipelines engineers build for processing and modeling. Proper alignment between data type and storage tool ensures smooth integration across the lifecycle.
6. Preprocessing Requirements for Each Data Category
Structured data usually requires encoding, scaling, and handling missing values.
Unstructured data demands advanced transformation such as tokenization, feature extraction, vectorization, and sometimes noise reduction.
Semi-structured data requires parsing, schema inference, or extraction of nested fields.
These varied preprocessing needs determine the choice of libraries, compute resources, and modeling techniques.
Efficient preprocessing plays a central role in model performance, as poor preparation can significantly distort predictions.
Each data type presents unique challenges that shape how models interpret information. Proper preprocessing ensures the data becomes usable and meaningful for downstream tasks.
7. Impact on Model Selection and Performance
The type of data influences the algorithms that are feasible and effective. Structured datasets work well with decision trees, SVMs, logistic regression, and boosting models.
Unstructured datasets require techniques like CNNs for images, RNNs/transformers for text, or audio-focused architectures.
Semi-structured data often calls for hybrid approaches that combine parsing with ML or deep learning.
Model performance varies greatly depending on how well the model architecture aligns with data structure.
Proper alignment ensures better generalization, reduced bias, and higher robustness. Understanding this relationship leads to more accurate and efficient ML systems.
8. Integration into End-to-End Machine Learning Systems
In real deployments, different data types often coexist within the same system.
For Example, a recommendation engine might use structured transaction records, unstructured reviews, and semi-structured logs simultaneously.
Integrating these sources requires a well-designed pipeline that can handle diverse formats.
Engineers use ETL workflows, API integration, data lakes, and orchestration tools to unify these datasets. Combining multiple data types creates richer models that capture broader context.
This multi-format integration enhances personalization, automation, and decision intelligence. A modern ML pipeline is incomplete without the capability to handle all three data categories.
9. Relevance of Data Variety in Machine Learning Workflows
Different data types—structured, unstructured, and semi-structured—play distinct roles across ML pipelines, influencing everything from feature engineering to model selection.
Structured data typically allows for rapid experimentation with classical algorithms like decision trees or logistic regression due to its tabular form.
Unstructured data, however, often requires advanced deep learning approaches because identifying patterns in text, images, or audio demands feature extraction techniques such as CNNs or Transformers.
Semi-structured data bridges the gap by offering enough organization to parse but still containing flexible components that need preprocessing logic.
Understanding how these types interact enables data scientists to build more adaptable workflows.
It also ensures teams choose the right tools, frameworks, and model families for each task, improving the overall efficiency and accuracy of ML solutions.
10. Data Storage Techniques Aligned with Data Types
How data is stored plays a major role in its accessibility, quality, and suitability for ML tasks.
Structured data often resides in relational databases, enabling SQL queries that retrieve values with precision and speed.
Unstructured datasets, such as large collections of documents or images, frequently utilize distributed file systems or cloud object storage, allowing horizontal scaling when dealing with massive volumes.
Semi-structured data benefits from NoSQL databases like MongoDB or Elasticsearch, where flexible schemas support irregular attributes.
Choosing the correct storage paradigm ensures smoother ingestion pipelines, reduces data preparation time, and prevents bottlenecks during feature extraction.
This alignment ultimately accelerates the transition from raw data to actionable insights.
11. Role of Data Quality Across Structured and Unstructured Forms
The reliability of downstream analytics depends heavily on data quality, regardless of type or structure.
Structured data errors are often easier to detect because missing values or inconsistencies stand out within defined columns.
In contrast, unstructured data issues—such as noisy text, blurry images, or unintelligible audio—are more subtle and require specialized cleaning workflows.
Semi-structured data may contain irregular formatting, optional fields, and nested attributes, demanding validation logic before it can be effectively queried.
Ensuring high quality at this stage reduces bias, improves model generalization, and minimizes false interpretations.
When handled carefully, quality assurance enhances the trustworthiness of insights derived across all machine learning tasks.
12. Impact of Data Types on Feature Engineering Strategies
Feature engineering approaches vary significantly depending on the type of data being processed.
Structured datasets typically leverage statistical transformations, encoding methods, and domain-specific ratios or aggregates to enrich model inputs.
Unstructured data, however, relies on embeddings, tokenization, vectorization, or pixel-level representations to transform raw content into meaningful numerical formats.
Semi-structured data requires flattening nested fields, normalizing hierarchical structures, or applying pattern-based extraction.
Selecting the correct strategy ensures that models receive representations that capture the essence of the underlying information.
Effective feature engineering directly enhances predictive accuracy and reduces the amount of manual tuning required during model development.
13. Challenges in Integrating Multi-Type Data Sources
Many real-world machine learning projects require combining various data types, which introduces complexity at engineering, modeling, and evaluation stages.
Structured and unstructured data often use different storage formats, sampling rates, and preprocessing needs, creating alignment issues during integration.
For example, merging customer demographic tables with call-center voice recordings involves syncing metadata, timestamps, and identities.
Semi-structured sources further complicate this by offering optional fields that may not consistently align across records.
Designing pipelines that normalize, synchronize, and reconcile these differences ensures models operate on cohesive datasets. When done well, integrated data provides richer context, enabling more robust predictions.
14. Importance of Metadata for Managing All Data Types
Metadata plays a pivotal role in understanding, organizing, and retrieving structured, semi-structured, and unstructured datasets.
For structured data, metadata describes column types, constraints, and relationships across tables, ensuring consistent interpretation during analytics.
Unstructured data depends heavily on metadata like timestamps, file types, categories, or textual tags to provide context that algorithms would otherwise lack.
Semi-structured sources contain embedded metadata within JSON keys or XML tags, guiding downstream parsing logic.
Well-maintained metadata accelerates data discovery, supports compliance, prevents schema confusion, and strengthens the integrity of machine learning pipelines.
It becomes even more essential as datasets scale across distributed environments.
