The Data Science lifecycle outlines the end-to-end process through which raw data is transformed into meaningful insights, predictive models, and deployable intelligence.
It acts as a structured roadmap that guides how data scientists approach real-world problems, ensuring that every step from initial problem framing to final evaluation is executed systematically.
This lifecycle is essential because modern data projects involve diverse datasets, evolving objectives, and complex modeling requirements.
Without a clear framework, teams risk misinterpretation, inefficiency, or inaccurate outcomes.
The lifecycle is not rigid; instead, it is iterative and adaptive. Each stage—problem definition, data acquisition, data preparation, exploratory analysis, model building, evaluation, deployment, and continuous improvement—feeds into the next and often loops back for refinement.
This flexibility allows data scientists to revise assumptions, optimize models, and incorporate new data as it becomes available.
As machine learning, automation, and big data technologies continue to advance, the lifecycle has evolved to include components like MLOps, real-time monitoring, and ethical checkpoints.
Importance of Data Science Lifecycle
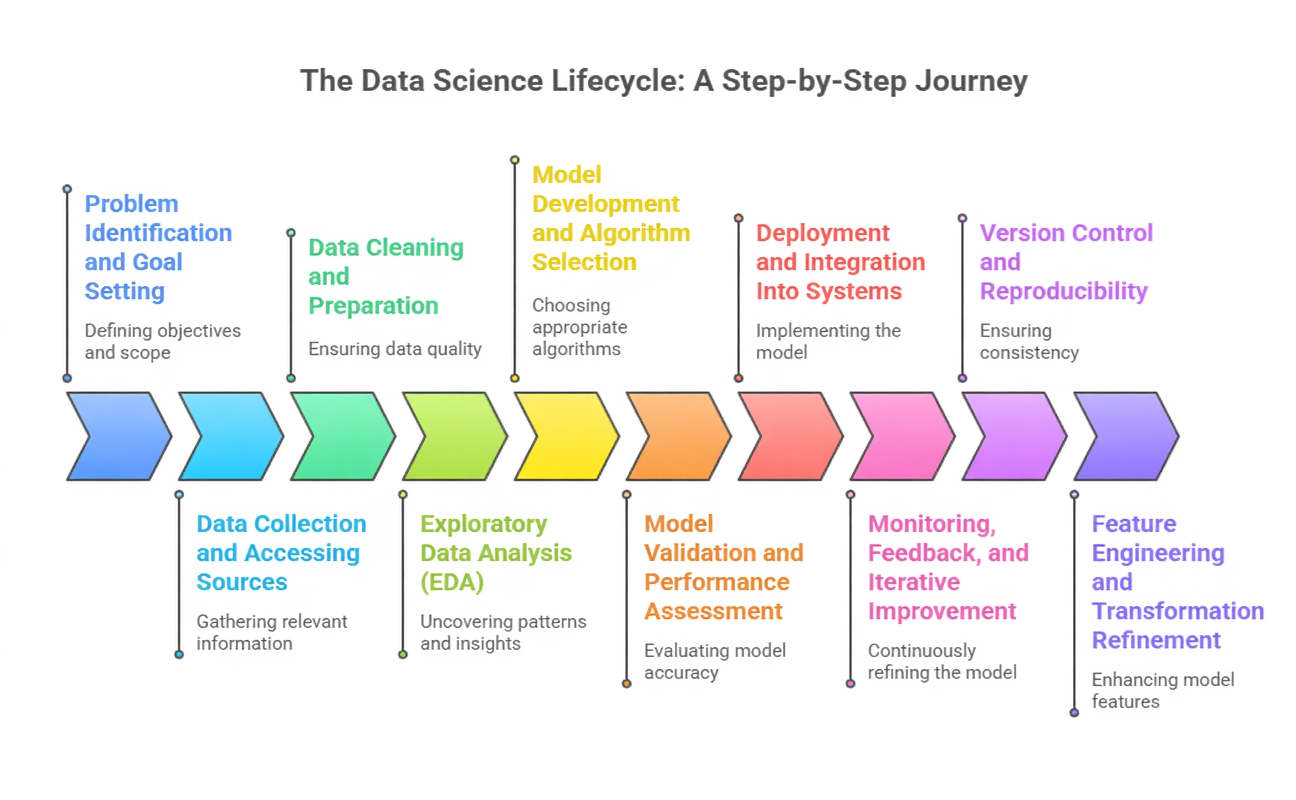 1. Problem Identification and Goal Setting
1. Problem Identification and Goal Setting
This stage focuses on clearly interpreting the business challenge and converting it into a data-focused problem statement.
Stakeholders provide context about objectives, constraints, and expected outcomes. A well-defined goal ensures the entire project moves in the right direction, preventing unnecessary work.
Data scientists determine what metrics will be used to judge success.
Understanding the scope helps in selecting suitable methods and tools. This clarity also improves communication and alignment among teams involved.
2. Data Collection and Accessing Sources
Once the problem is established, relevant data must be gathered from internal systems, external APIs, public datasets, or third-party providers.
Data may exist in structured, unstructured, or streaming formats, requiring different extraction techniques.
At this stage, data engineers may build pipelines or connectors to automate access. Ensuring data reliability and completeness is essential because missing or incorrect information impacts downstream steps.
Proper documentation of sources supports traceability and future audits. The foundation of any good project lies in the quality of data gathered here.
3. Data Cleaning and Preparation
Data preparation involves resolving inconsistencies, handling missing values, standardizing formats, and removing noise.
Real-world datasets often contain errors that can mislead models if ignored.
Feature engineering is also introduced here, allowing extraction of meaningful variables that capture underlying patterns.
The better the data is prepared, the stronger the model’s performance will be.
This phase typically takes the most time due to its complexity. A meticulous cleaning strategy ensures the dataset becomes a trustworthy input for analysis and modeling.
4. Exploratory Data Analysis (EDA)
EDA brings clarity to the structure, behavior, and relationships present within the dataset.
Visualizations and statistical summaries reveal hidden trends, anomalies, and potential drivers of the target outcome.
Insights gained at this stage guide decisions about modeling techniques and feature selection.
Analysts validate assumptions, detect outliers, and uncover patterns that may not be obvious.
EDA also helps confirm whether the initial hypothesis still holds. By interpreting the dataset deeply, teams reduce the risk of choosing an unsuitable modeling approach.
5. Model Development and Algorithm Selection
Based on the insights from EDA, suitable machine learning algorithms are chosen to solve the problem—whether predictive, descriptive, or prescriptive.
Data is split into training and testing groups to evaluate performance fairly. Multiple models may be built and compared to identify the best fit.
Hyperparameter tuning further enhances accuracy and robustness.
Throughout this process, domain understanding influences decisions about complexity and interpretability. The ultimate aim is to create a model that generalizes well to unseen data.
6. Model Validation and Performance Assessment
Validation ensures the developed model behaves reliably and aligns with real-world expectations.
Metrics such as accuracy, precision, recall, RMSE, or AUC help quantify results.
If performance is unsatisfactory, earlier stages may be revisited to refine features or adjust algorithms.
Cross-validation and stress-testing improve confidence in model stability.
This step protects against overfitting and ensures fairness and transparency.
The validation phase ensures the solution is not only mathematically sound but also practically useful.
7. Deployment and Integration Into Systems
Once validated, the model is deployed into production—through APIs, web services, dashboards, or embedded applications.
Deployment enables continuous usage of the model by end-users or automated systems.
Engineers ensure scalability, security, and efficiency for real-time or batch operations.
Proper documentation and integration guidelines support smooth handoffs.
The success of a project becomes visible only when the model starts impacting real workflows. Deployment thus transforms analysis into actionable outcomes.
8. Monitoring, Feedback, and Iterative Improvement
Models need ongoing oversight because data patterns and business environments change over time.
Monitoring identifies performance drift, anomalies, or unexpected behavior in production.
Feedback from users and stakeholders helps refine features and improve accuracy.
Regular updates ensure the model remains relevant and effective.
MLOps frameworks support automated retraining and lifecycle management. This iterative loop keeps Data Science solutions aligned with evolving demands.
9. Version Control and Reproducibility
Reproducibility ensures that every experiment, transformation, and model can be recreated exactly as before.
Version control systems like Git help track dataset versions, code updates, and model iterations.
This prevents confusion when multiple team members collaborate on the same project.
Reproducibility also builds trust, as stakeholders can verify how a model was developed.
Maintaining detailed experiment logs supports comparison between different model configurations.
This process safeguards the integrity of the entire lifecycle. Ultimately, reproducible workflows make scaling Data Science projects easier and more consistent.
10. Feature Engineering and Transformation Refinement
Although introduced earlier, feature engineering becomes more sophisticated as insights evolve.
New variables may be constructed from existing ones, improving a model’s ability to recognize deeper patterns.
Domain expertise plays a critical role here—knowing what behaviors or signals matter can greatly boost model effectiveness.
Transformations such as scaling, encoding, or dimensionality reduction are reassessed for optimal performance.
This iterative refinement ensures the most meaningful representation of the data.
Better features often outperform complex algorithms, highlighting their importance in the lifecycle. A strong feature set becomes the backbone of accurate predictions.
11. Model Interpretability and Explainability
Modern projects must ensure that models are not only accurate but also understandable.
Explainability tools like SHAP or LIME reveal how specific features influence predictions.
This clarity helps stakeholders trust automated decisions, especially in sensitive fields like healthcare or finance. Interpretability also exposes potential biases or unintended patterns learned by the model.
By understanding model behavior, teams can make more informed improvements.
Regulatory requirements increasingly demand algorithmic transparency. Explainability bridges the gap between technical outcomes and real-world accountability.
12. Ethical Review and Compliance Verification
As AI systems become more influential, ethical checks must be integrated into the lifecycle.
This includes evaluating fairness, privacy, and potential unintended consequences.
Ethical review ensures that models do not disadvantage specific groups or expose sensitive data.
Compliance with regulations such as GDPR or emerging AI policies becomes a critical part of the process.
Teams assess whether data usage aligns with consent and legal standards.
Ethical checkpoints prevent damage to reputation and user trust. Incorporating these reviews makes Data Science both responsible and sustainable.
13. Collaboration and Cross-Functional Communication
Data Science projects involve multiple groups—data engineers, analysts, domain experts, and decision-makers.
Effective communication ensures every team understands goals, progress, and constraints.
Regular discussions help align technical work with business expectations.
Collaboration tools and documentation platforms make shared work more organized and transparent.
Miscommunication can lead to misaligned outcomes, so this step reinforces clarity.
Shared understanding accelerates progress and reduces delays. Strong teamwork transforms complex projects into streamlined, coordinated efforts.
14. Data Governance and Quality Assurance
Data governance establishes rules and standards for how data should be stored, accessed, and secured.
Quality assurance frameworks verify accuracy, consistency, and completeness across all datasets.
This prevents unreliable or contaminated data from influencing downstream processes.
Governance ensures that data assets remain organized and compliant with organizational standards.
It also clarifies responsibility regarding ownership and stewardship.
Well-managed data ecosystems support faster experimentation and higher-quality insights. Strong governance forms the backbone of any scalable Data Science operation.
15. Scalability Planning and Performance Optimization
As a project matures, the system must scale to handle larger datasets, more users, or higher computation demands.
Scalability planning ensures models and pipelines can expand without performance issues.
Optimization strategies such as caching, parallel processing, or distributed training improve speed and efficiency.
Teams evaluate resource usage to avoid bottlenecks. This step is crucial for production systems that operate continuously or in real time.
Scalability also prepares the project for future enhancements. Ensuring performance stability builds long-term reliability.
