Sometimes you need a collection of items where duplicates simply do not belong — like a list of unique tags, distinct user IDs, or a set of categories in a dataset.
That is where Python sets come in. A set is an unordered collection of unique items, meaning it automatically removes duplicates and does not maintain any fixed position for its elements.
Sets are particularly useful for membership testing, removing duplicate data, and performing mathematical set operations like union and intersection.
Creating a Set
Sets are defined using curly braces {} or the set() function. Unlike dictionaries, sets contain only values — no key-value pairs.
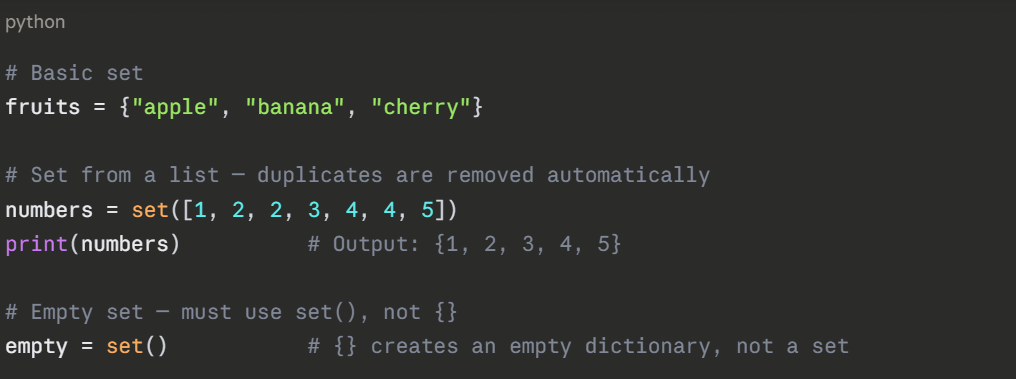
Important: Sets are unordered — the output order may vary each time you run the program.
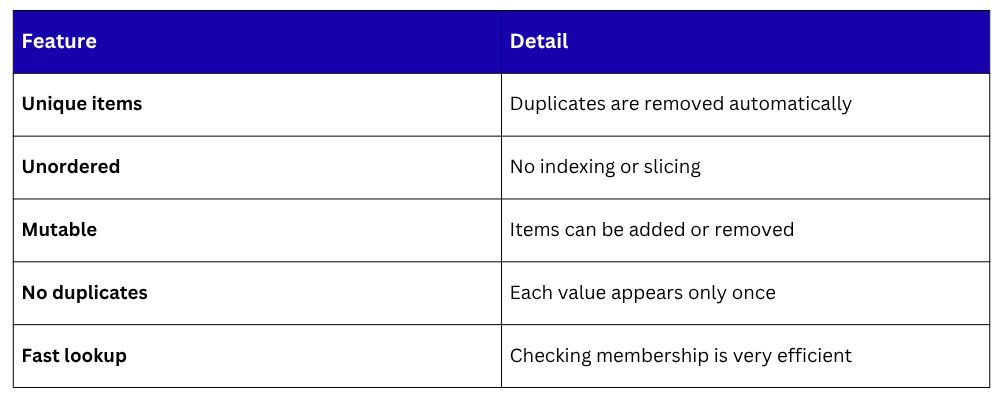
Key Characteristics of Sets
Adding and Removing Items
Sets are mutable, so you can modify them after creation.
python
fruits = {"apple", "banana", "cherry"}
# Add a single item
fruits.add("mango")
print(fruits) # Output: {'apple', 'banana', 'cherry', 'mango'}
# Add multiple items
fruits.update(["grape", "kiwi"])
print(fruits) # Output: {'apple', 'banana', 'cherry', 'mango', 'grape', 'kiwi'}
# Remove item — raises KeyError if not found
fruits.remove("banana")
# Discard item — no error if not found
fruits.discard("orange") # No error even though 'orange' is not in the set
# Remove and return a random item
fruits.pop()
# Clear all items
fruits.clear()
Membership Testing
One of the most common and efficient uses of a set is checking whether a value exists.
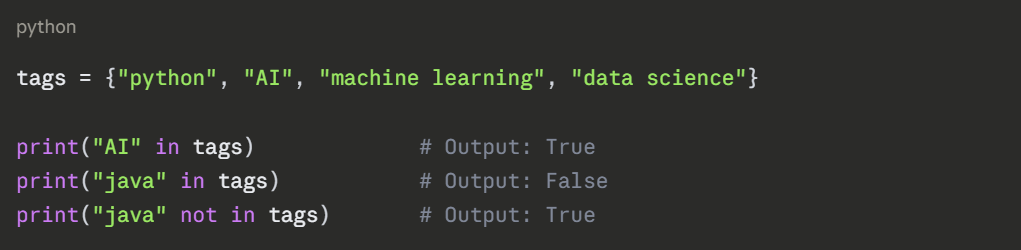
Membership testing in sets is significantly faster than in lists, especially for large collections — an important advantage in AI data processing.
Mathematical Set Operations
Sets support the core operations from mathematical set theory, making them powerful for data comparison tasks.
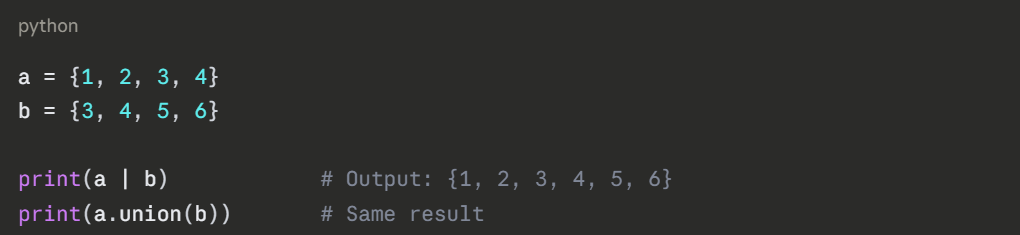
Union — All unique items from both sets
Intersection — Items present in both sets

Difference — Items in one set but not the other

Difference — Items in either set, but not both

Subset and Superset Checks
Sets can also be compared to determine if one is contained within another.
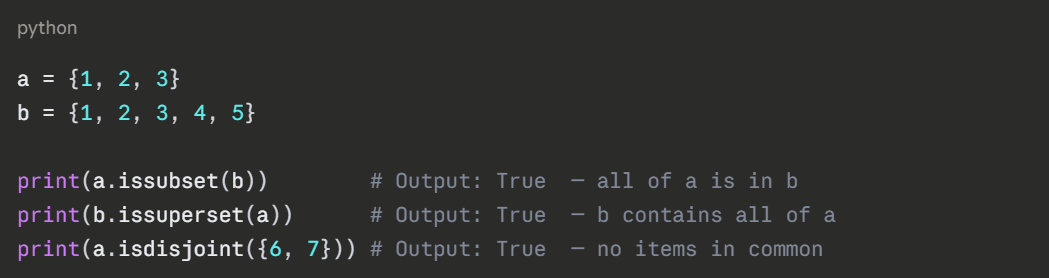
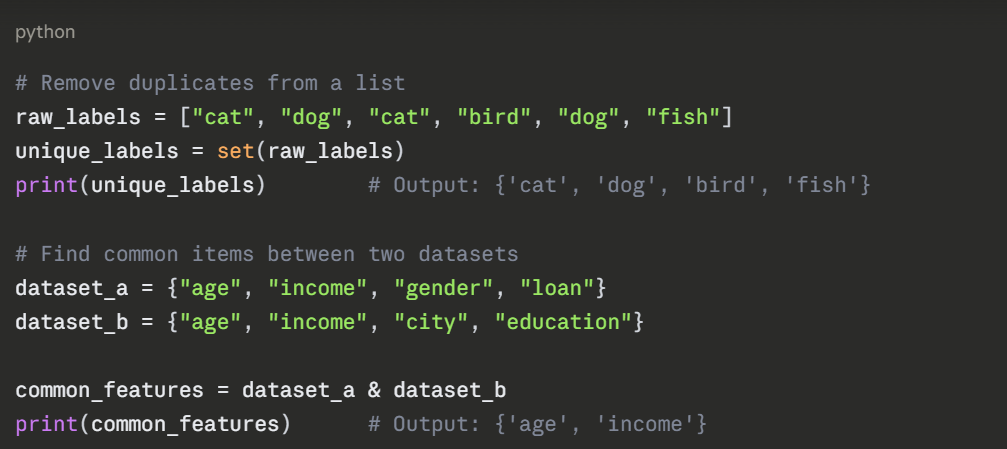
Practical Use Cases in AI and Data Processing
Sets are genuinely useful in everyday data tasks:
1. Removing duplicates from a dataset column.
2. Finding common categories between two datasets using intersection.
3. Comparing feature lists across different models.
4. Fast membership checks when filtering data.
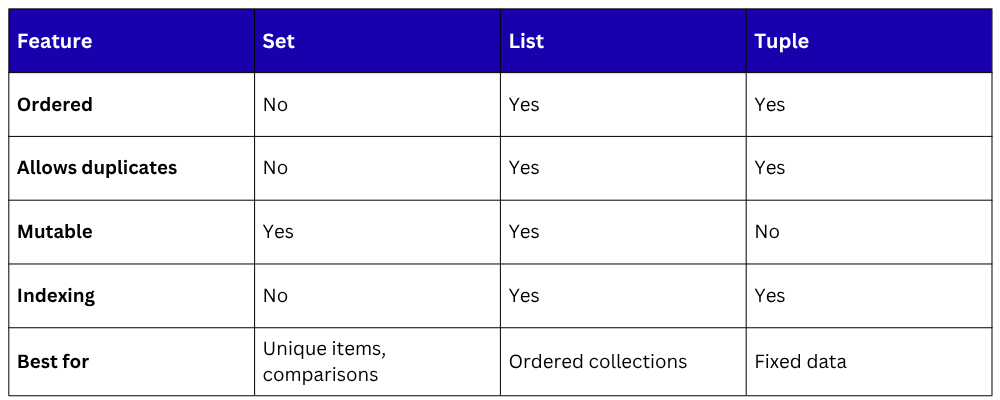
Sets vs Lists vs Tuples

Class Sessions
Sales Campaign

We have a sales campaign on our promoted courses and products. You can purchase 1 products at a discounted price up to 15% discount.