Modern backend architectures often use a hybrid approach, combining SQL and NoSQL databases to meet different application needs.
Relational (SQL) databases provide strong consistency, structured schemas, and powerful querying, making them ideal for transactional data such as payments and user accounts.
NoSQL databases, on the other hand, offer flexible schemas, high scalability, and fast access, which are well-suited for large-scale, distributed, or rapidly changing data.
Choosing between SQL and NoSQL is not an either-or decision.
Many backend systems use both, selecting the right database type based on data access patterns, consistency requirements, and performance goals. This approach helps optimize reliability and scalability without sacrificing flexibility.
Understanding SQL and NoSQL Foundations
Before diving into hybrids, let's recap the core differences. SQL (relational) databases like PostgreSQL or MySQL use tables, schemas, and joins for consistent, transactional data.
NoSQL databases, such as MongoDB (document) or Cassandra (wide-column), prioritize schema flexibility and horizontal scaling for high-velocity data.
This foundation matters because hybrids emerge when an app outgrows one paradigm—think starting with SQL for user accounts, then adding NoSQL for user-generated content.
Key Characteristics of SQL Databases
SQL shines in scenarios demanding data integrity and complex queries.
1. ACID compliance: Ensures Atomicity, Consistency, Isolation, and Durability for reliable transactions.
2. Structured schema: Fixed tables enforce data relationships via foreign keys.
3. Powerful querying: SQL language supports joins, aggregations, and subqueries out of the box.
For Example, in a banking app, SQL prevents overdrafts during transfers by locking rows atomically.
Key Characteristics of NoSQL Databases
NoSQL thrives on volume, velocity, and variety, often trading some consistency for speed (following BASE: Basically Available, Soft state, Eventual consistency).
1. Schema-less design: Store JSON-like documents or key-value pairs without rigid structures.
2. Horizontal scaling: Easily shard across clusters for massive throughput.
3. High write/read speeds: Ideal for logs, real-time analytics, or IoT streams.
Consider Netflix using Cassandra for user recommendations—it handles petabytes without schema migrations.
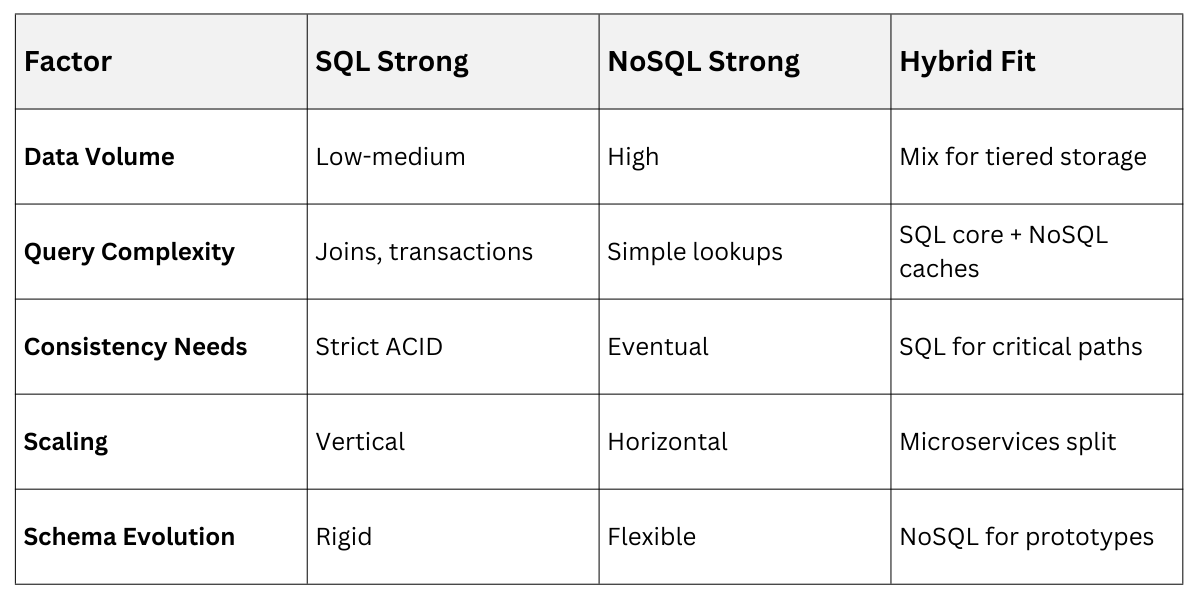
When to Choose SQL, NoSQL, or Both
Pure SQL suits transactional apps; pure NoSQL fits big data pipelines. Hybrids kick in for polyglot persistence, where multiple databases coexist via microservices or polyglot apps.
The decision hinges on data patterns: relational for hierarchies, non-relational for graphs or blobs. Industry standards like those from Gartner emphasize hybrids for 70% of enterprise apps by 2025.
SQL-First Scenarios
Opt for SQL when relationships and consistency dominate.
1. E-commerce order processing: Joins across users, products, and payments.
2. Financial ledgers: ACID transactions prevent errors.
3. Reporting dashboards: Complex analytics with GROUP BY.
Pro Tip: Use PostgreSQL's JSONB extension for semi-structured data within SQL, blurring lines early.
NoSQL-First Scenarios
Choose NoSQL for scale and flexibility in unstructured data.
1. Social feeds (e.g., Twitter-like timelines): MongoDB for nested comments.
2. Session stores: Redis for fast key-value caching.
3. Time-series data: InfluxDB for metrics.
Real-World: Uber uses Schema-less MongoDB for trip histories, scaling to millions of writes per minute.
Hybrid Triggers
Go hybrid when workloads diverge—e.g., 80/20 rule: 80% reads are simple lookups (NoSQL), 20% are joins (SQL).
 Architecting Hybrid Systems: Best Practices
Architecting Hybrid Systems: Best Practices
Hybrid setups require careful orchestration. Use patterns like CQRS (Command Query Responsibility Segregation) to route writes to SQL and reads to NoSQL, or event sourcing for data sync.
Tools like Apache Kafka bridge databases, ensuring eventual consistency. Always monitor with Prometheus for bottlenecks.
Step-by-Step Hybrid Implementation
Follow this process in your backend (e.g., Node.js with Prisma for SQL and Mongoose for MongoDB):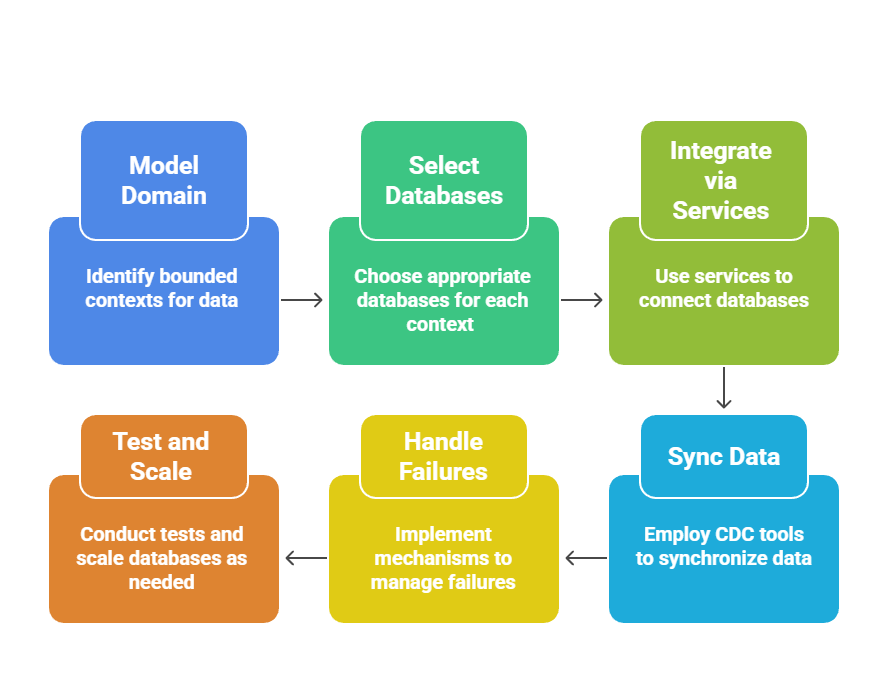
Example: E-commerce backend
User auth & orders → PostgreSQL (ACID)
Product catalogs & reviews → MongoDB (flexible schemas)
Search & analytics → Elasticsearch (full-text)
Cache → Redis (sessions)Sync via Kafka: Order creation events trigger inventory updates.
Common Pitfalls and Mitigations
Hybrids amplify complexity—here's how to sidestep traps.
1. Data duplication: Use event-driven architecture to propagate changes.
2. Sync lag: Accept eventual consistency for non-critical data; fallback to SQL polling.
3. Vendor lock-in: Standardize on open-source like CockroachDB (distributed SQL) or DynamoDB-compatible options.
4. Operational overhead: Containerize with Docker/Kubernetes; use managed services like AWS Aurora (SQL) + DocumentDB (NoSQL).
Real-World Case Studies and Tools
1. Case Study: Spotify's Backend
Spotify uses MySQL for user metadata (relationships) and Cassandra for playlists (scale). Kafka syncs them, handling 1B+ events daily. Lesson: Separate hot (frequent access) and cold data.
2. Case Study: Instagram
PostgreSQL for feeds/transactions; Cassandra for stories. They shard by user ID, achieving 100M+ QPS.
Tool Recommendations
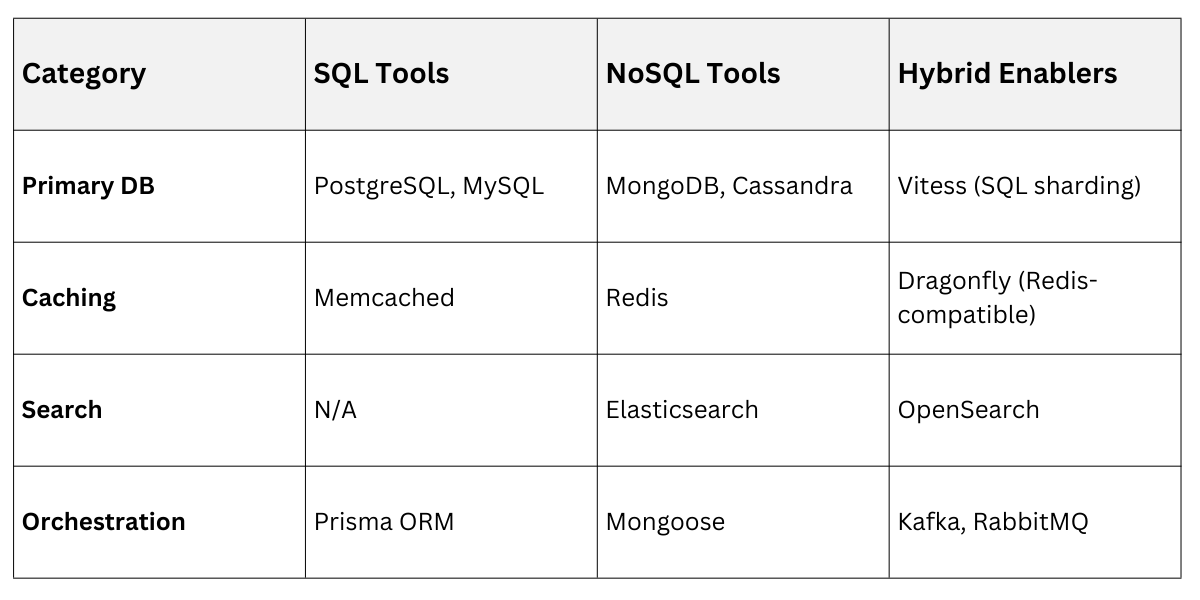 Start Small: Prototype with Docker Compose stacking Postgres + Mongo.
Start Small: Prototype with Docker Compose stacking Postgres + Mongo.

Class Sessions
Sales Campaign

We have a sales campaign on our promoted courses and products. You can purchase 1 products at a discounted price up to 15% discount.