Indexing is a critical technique used to improve database query performance. In backend systems, as data volume grows, searching through tables without indexes can become slow and resource-intensive.
Indexes create optimized data structures that allow the database to locate records quickly without scanning entire tables.
Choosing the right indexing strategy helps balance fast read operations with acceptable write performance and storage overhead.
B-tree Indexes
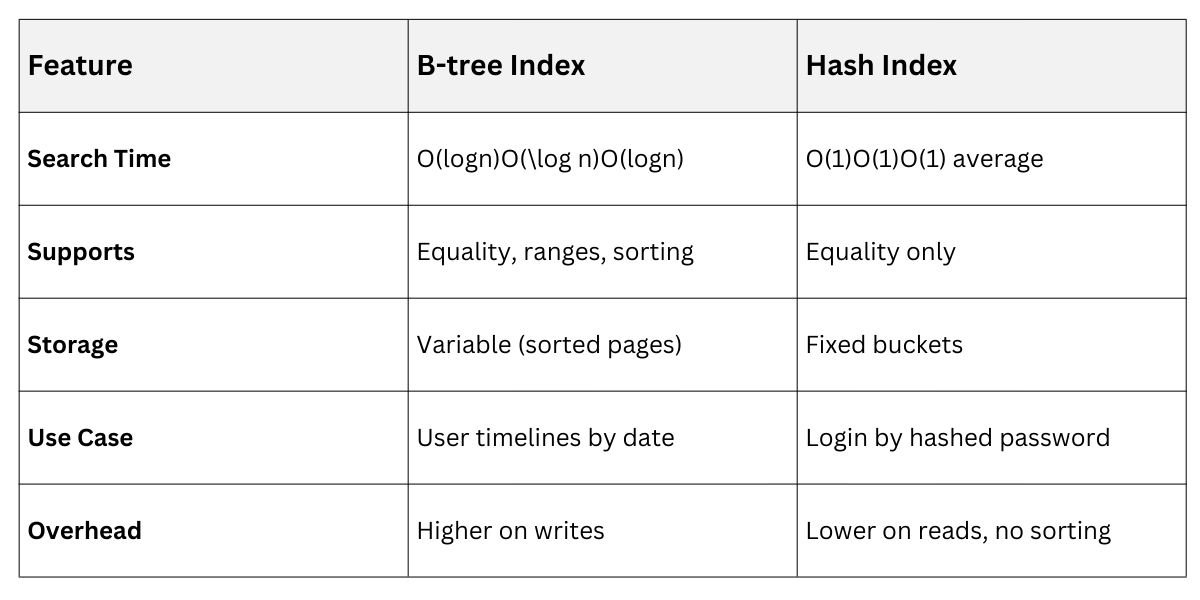
B-tree indexes are the workhorse of most relational databases, organizing data in a balanced tree structure for lightning-fast lookups. They're versatile and handle a wide range of queries, making them ideal for backend apps with dynamic data.
B-trees (short for Balanced trees) maintain sorted data in a multi-level structure, where each node points to child nodes or leaf nodes with actual data pointers.
This balance ensures logarithmic search times—think O(\log n) complexity—regardless of data volume. Unlike linear scans, B-trees let the database engine "walk" the tree to find rows quickly.
Key Characteristics
1. Self-balancing: Automatically adjusts on inserts/deletes to prevent skew.
2. Range-friendly: Excels at WHERE clauses with >, <, BETWEEN, or ORDER BY.
3. Default choice: Used by MySQL InnoDB, PostgreSQL, and SQL Server for primary/secondary keys.
Consider a user table with millions of records. A B-tree index on created_at (TIMESTAMP) speeds up fetching "users registered in the last 30 days":
SELECT * FROM users WHERE created_at >= NOW() - INTERVAL '30 days' ORDER BY created_at;Without it, the database scans every row; with it, it prunes irrelevant branches instantly.
When to use B-tree:
1. Equality checks (WHERE user_id = 123).
2. Range queries (e.g., date ranges, price filters).
3. Sorted outputs (ORDER BY).
Trade-offs: Indexes add storage (10-20% overhead) and slow writes, so profile with EXPLAIN before adding.
Hash Indexes
Hash indexes use a hash function to map keys to fixed-size buckets, enabling constant-time lookups for exact matches.
They're a specialized tool in your backend arsenal, shining where precision trumps range flexibility.
Unlike B-trees' sorted paths, hash indexes compute a hash value (e.g., via MD5-like algo) and jump straight to the bucket. This yields
O(1) average-case performance for equality searches, perfect for high-read workloads like caching or unique lookups.
Hash Indexes Suit:
1. Exact matches only: WHERE email = 'user@example.com'.
2. Memory-based engines: MySQL MEMORY storage or in-memory tables.
3. No ranges: Fails on >, <, or LIKE '%pattern'.
Example: In a session store table, index session_id (VARCHAR unique) with hash for sub-millisecond SELECT * FROM sessions WHERE session_id = ?.
Best Practice: Per MySQL 8.0+ docs, enable adaptive hash indexing for InnoDB to auto-switch based on workload. Avoid for frequently updated data, as rehashing slows inserts.
Composite Indexes
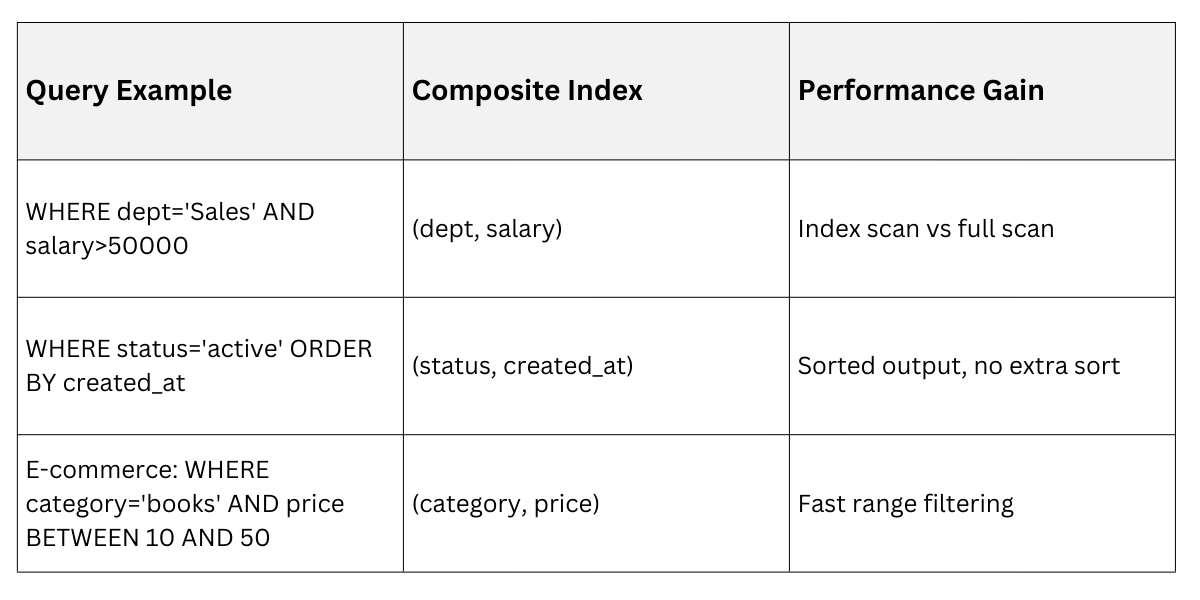
Composite indexes (or multi-column indexes) combine multiple columns into one structure, turbocharging queries that filter on several fields at once.
They're essential for complex backend queries, like e-commerce search or analytics dashboards.
Start with a short intro: Imagine a B-tree (or hash) built on (last_name, first_name)—the database sorts and searches primarily by last name, then refines by first name.
This follows the leftmost prefix principle: Queries must match left-to-right columns for full efficiency.
Benefits
1. Reduced I/O: One index covers multi-column WHERE.
2. Selectivity boost: Order columns by cardinality (unique values), e.g., user_id before status.
Building Effective Composites
1. Analyze query patterns with EXPLAIN ANALYZE.
2. Place most selective column leftmost.
3. Include sort columns last for ORDER BY.
Real-World Tip: In PostgreSQL 16+, use INCLUDE clauses for non-key columns to minimize index size. Test with your app's top 80% queries—composites can cut latency by 90%.
Pitfall: Over-indexing bloats storage; aim for 5-10 indexes per table max.
Covering Indexes
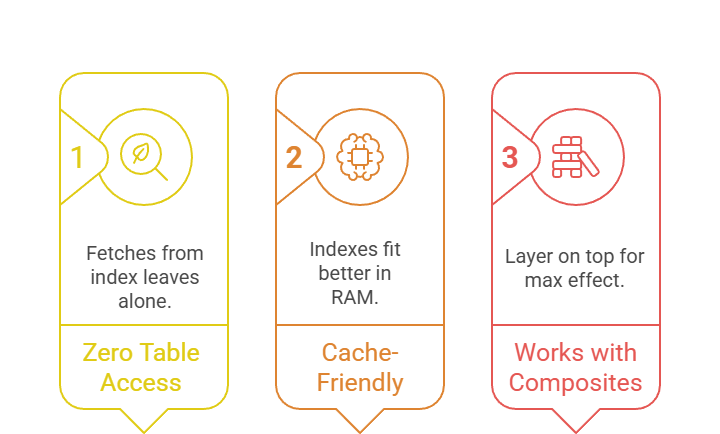
Covering indexes (aka index-only scans) store all queried columns within the index itself, bypassing the table entirely for ultra-fast reads.
This is a game-changer for read-heavy backends, slashing disk I/O in APIs or reports.
After a quick setup: Extend a B-tree or composite with INCLUDE (PostgreSQL/SQL Server) or covering columns (MySQL). The query planner spots it via EXPLAIN (look for "Index Only Scan").
Advantages
Implementation Steps
1. Identify: frequent SELECT projections (e.g., SELECT id, name, email).
2. Create: CREATE INDEX idx_users_cover ON users (status) INCLUDE (id, name, email);.
3. Verify: Query shows "Index Only Scan".

Class Sessions
Sales Campaign

We have a sales campaign on our promoted courses and products. You can purchase 1 products at a discounted price up to 15% discount.