Concurrency issues arise when multiple transactions access and modify the same data at the same time. In backend systems with many users, improper handling of concurrent transactions can lead to inconsistent or incorrect data.
Common problems include lost updates, where one transaction overwrites another’s changes, and dirty reads, where a transaction reads uncommitted data that may later be rolled back.
Database isolation levels control how transactions interact with each other and how much intermediate data is visible.
Levels such as READ COMMITTED and SERIALIZABLE define the balance between data consistency and system performance.
Concurrency in Databases
Concurrency allows multiple transactions to run at the same time, boosting throughput in high-traffic backend apps.
However, without controls, this leads to anomalies that violate data integrity.
Databases use locking and multiversion concurrency control (MVCC) to manage access, but issues still emerge in shared environments like PostgreSQL or MySQL.
What are Transactions?
A transaction is a unit of work that follows ACID rules: Atomicity, Consistency, Isolation, and Durability.
Backend devs wrap database operations in transactions to ensure all-or-nothing execution.
For example, transferring money between accounts involves debit and credit steps—both must succeed, or neither does.
Key Characteristics
1. Atomicity: All operations complete, or none do.
2. Consistency: Data moves from one valid state to another.
3. Isolation: Transactions appear to run sequentially, even if parallel.
4. Durability: Changes persist after commit, even on failure.
Common Concurrency Issues
When transactions interleave without proper isolation, anomalies occur. These are especially critical in backend services handling user requests concurrently.
Lost Updates
A lost update happens when two transactions read the same data, modify it independently, and overwrite each other's changes—one update "loses" visibility.
Imagine two backend admins updating a user's balance simultaneously:
1. Admin A reads balance: $100.
2. Admin B reads balance: $100 (same stale value).
3. Admin A adds $50, writes $150.
4. Admin B subtracts $20, writes $80—overwriting A's change!
The final balance ($80) ignores A's update, leading to lost data.
1. Impact: Common in inventory systems or financial apps.
2. Detection: Check for unexpected overwrites in logs.
3. Simple fix: Use optimistic locking with version numbers.
Dirty Reads: A dirty read occurs when a transaction reads uncommitted ("dirty") data from another transaction, then acts on it—risking errors if the first rolls back.
Consider a Banking App:
1. Transaction 1: Debit $200 from Account X (balance drops to $300 temporarily).
2. Transaction 2: Reads $300 (dirty value) and approves a loan.
3. Transaction 1 rolls back (due to insufficient funds)—balance reverts to $500.
4. Transaction 2 committed based on false data!
This violates isolation, causing cascading failures in backend workflows.
1. Real-World Risk: E-commerce checkouts showing phantom stock.
2. Why it Matters: Undermines trust in your API responses.
Isolation Levels
Isolation levels define how much transaction interference is allowed, balancing consistency against performance. Defined by SQL standards (ANSI/ISO), they range from weak (READ UNCOMMITTED) to strict (SERIALIZABLE).
Higher levels prevent more anomalies but add overhead like longer locks.
ANSI SQL Isolation Levels
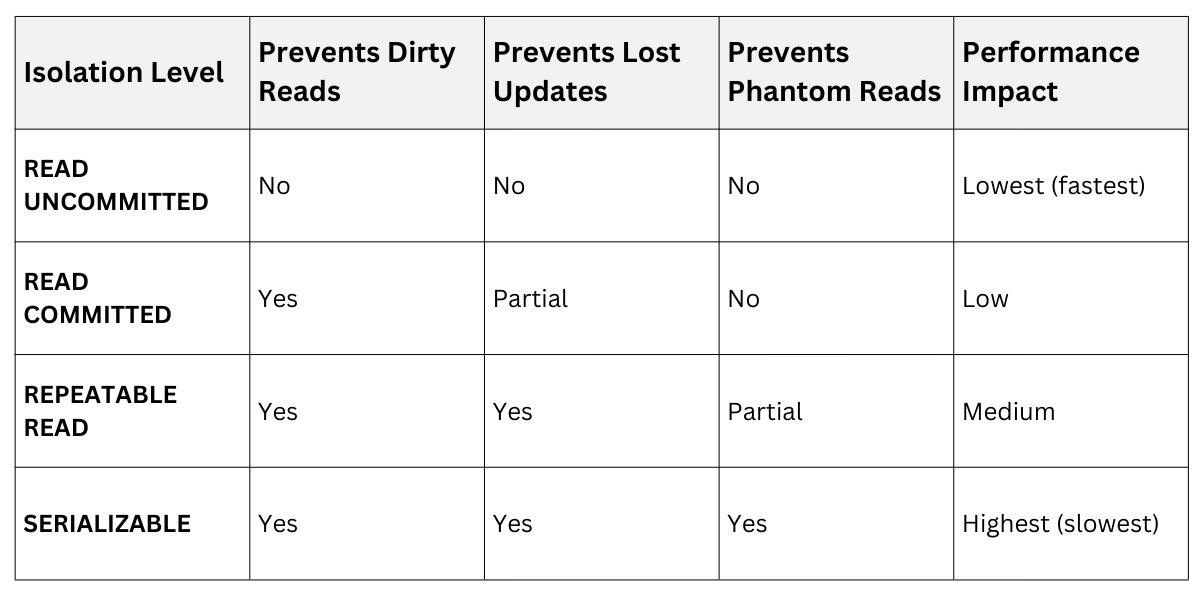 Note: Phantom reads involve new rows appearing mid-transaction; we'll touch on them briefly.
Note: Phantom reads involve new rows appearing mid-transaction; we'll touch on them briefly.
READ COMMITTED: Practical Default
READ COMMITTED ensures reads only see committed data, preventing dirty reads. It's the default in PostgreSQL and SQL Server, ideal for most backend apps.
How it Works
1. Each statement sees a snapshot of committed data at read time.
2. Writers hold short locks, releasing after commit.
Example in a Flask backend (using SQLAlchemy)
# Session 1 (uncommitted)
session.execute("UPDATE accounts SET balance = balance - 100 WHERE id=1")
# Not committed yet
# Session 2 (READ COMMITTED)
balance = session.execute("SELECT balance FROM accounts WHERE id=1").scalar()
# Sees original balance, not dirty -100Pros: Blocks dirty reads; good concurrency.
Cons: Still allows lost updates and non-repeatable reads (same query yields different results).
Best For: Web APIs with moderate contention.
SERIALIZABLE: Gold Standard for Safety
SERIALIZABLE guarantees transactions behave as if run sequentially—no anomalies, including phantoms. PostgreSQL implements it via Serializable Snapshot Isolation (SSI), detecting conflicts at commit.
Process
1. Transactions acquire serializability checks.
2. On commit, DB validates no serialization anomaly occurred.
3. If conflict, serialization failure—retry transaction.
Bank Transfer Example
1. Tx1: Read Account A ($100), plan debit $50.
2. Tx2: Read Account A ($100), plan credit $30.
3. SERIALIZABLE detects overlap, aborts one (say Tx2).
4. Tx1 commits first: $50 debit.
5. Tx2 retries with updated $50 view.
In code (PostgreSQL with psycopg2)
import psycopg2
conn = psycopg2.connect("dbname=test")
conn.autocommit = False
cur = conn.cursor()
cur.execute("SET TRANSACTION ISOLATION LEVEL SERIALIZABLE")
# Your operations here
conn.commit() # Or rollback on failurePros: Full ACID isolation; prevents all listed issues.
Cons: Higher retry rates; ~20-50% perf hit in high contention.
Best For: Financial systems, auctions—any "money moves" app.
Best Practice: Wrap in try-retry loops for failures.
Mitigating Concurrency Issues in Practice
Beyond isolation, backend devs layer strategies for robust databases.
Strategies and Tools
1. Optimistic Concurrency: Add a version column; check on update (UPDATE ... WHERE version = old_version).
2. Pessimistic Locking: SELECT ... FOR UPDATE to block readers.
3. Application-Level Checks: Validate business rules post-read.
4. Indexing: Reduce lock contention with proper indexes.
In Django ORM
# Optimistic
account = Account.objects.get(id=1)
account.balance -= 50
if account.version != original_version: # Conflict!
raise ConcurrencyError()
account.save()