Normalization is a database design technique used to organize data efficiently in relational databases. Its main goal is to reduce data redundancy and ensure data consistency by structuring tables according to well-defined rules called normal forms.
In backend data design, proper normalization helps prevent common data issues and makes databases easier to maintain and scale.
What is Normalization and Why Does It Matter?
Normalization breaks down complex tables into simpler, related ones following proven rules—or normal forms—developed by E.F. Codd in the 1970s.
These principles, now an industry standard in relational databases like PostgreSQL and MySQL, eliminate data repetition and protect against insertion, update, and deletion anomalies.
By applying normalization, backend developers prevent bloated tables that slow down CRUD operations and invite bugs.
Think of it as decluttering your database kitchen: everything has its place, making meals (queries) quicker to prepare.
Key Benefits in Backend Contexts
Normalization shines in dynamic apps where data evolves rapidly.
1. Reduces storage waste: No duplicate customer addresses across orders.
2. Boosts query performance: Smaller, focused tables mean efficient JOINs.
3. Simplifies maintenance: Changes propagate reliably via foreign keys.
4. Enhances integrity: Constraints enforce rules automatically.
5. Understanding Data Anomalies: The Problems Normalization Solves
They arise in un-normalized (or denormalized) tables with redundant or multi-valued data, common in hasty backend designs.
Consider an un-normalized orders table for an online bookstore:
1. Update anomaly: Change Alice's email? Update two rows, or data drifts inconsistent.
2. Deletion anomaly: Delete Bob's order? Lose his email forever.
3. Insertion anomaly: Add a new customer without an order? Can't, due to missing fields.
These issues cascade in backends, breaking APIs and frustrating users.
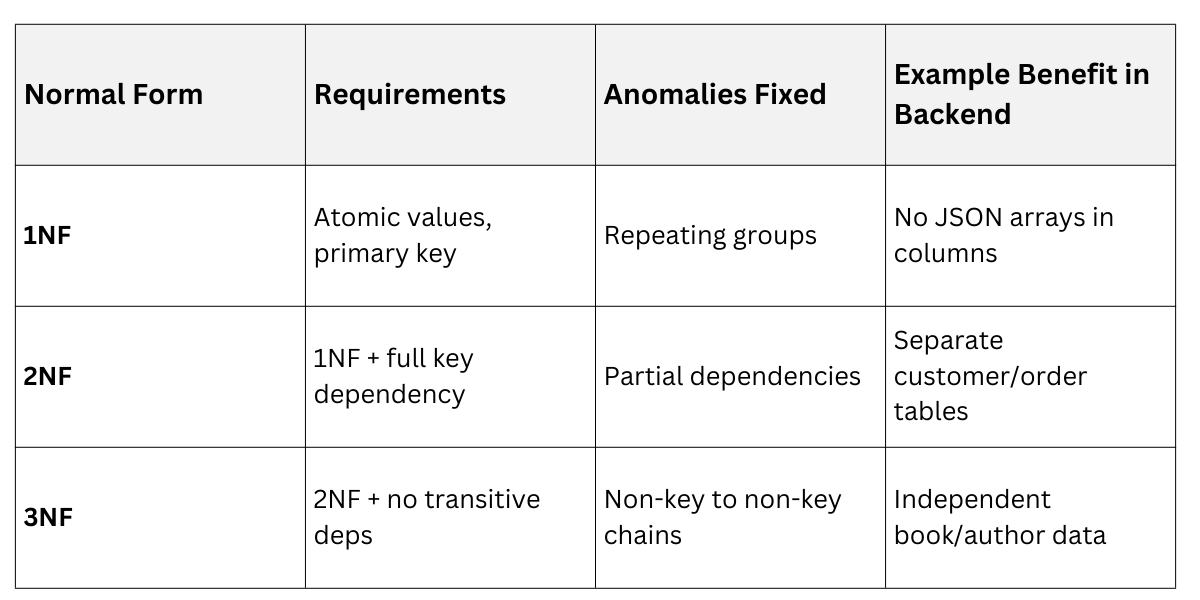
First Normal Form (1NF): Atomic Values and No Repeats
1NF is the entry gate: every column holds atomic values (single, indivisible facts), with no repeating groups or arrays in cells. Tables must have a primary key uniquely identifying each row.
Start here to banish multi-valued fields, a frequent newbie mistake in backend schemas.
To achieve 1NF:
1. Ensure no cell contains lists (e.g., split "SQL, Python" into separate rows).
2. Define a primary key (e.g., order_id).
3. Eliminate duplicate rows.
Example: Normalize the bookstore table above—it's already close but lacks explicit keys. Add customer_id for uniqueness.
1NF Result
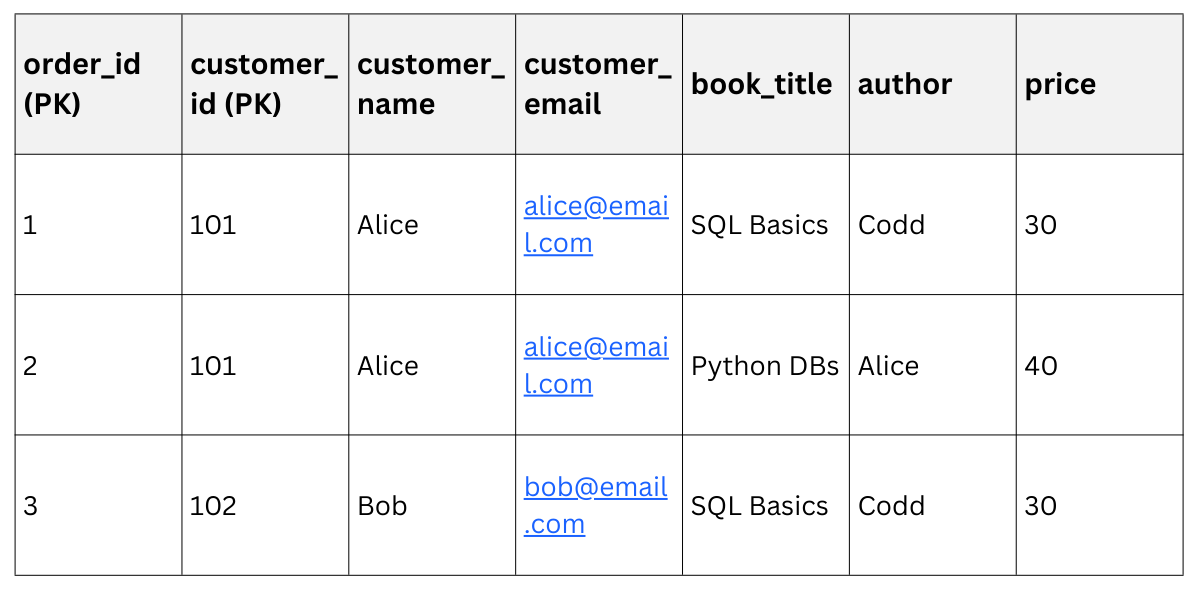 Now, updates are safer, but redundancy persists (e.g., Alice's details repeat).
Now, updates are safer, but redundancy persists (e.g., Alice's details repeat).
Second Normal Form (2NF): Tackling Partial Dependencies
2NF builds on 1NF: the table must be in 1NF, and every non-key attribute must depend fully on the entire primary key, not just part of it.
This eliminates partial dependencies, where non-keys rely on only one key column in composite keys.
Ideal for backends with multi-column primaries, like order-line items.
Check for 2NF violation: In our 1NF table, customer_name and customer_email depend only on customer_id, not the full {order_id, customer_id} key.
To Fix:
1. Identify partial dependencies.
2. Split into separate tables: one for customers, one for order details.
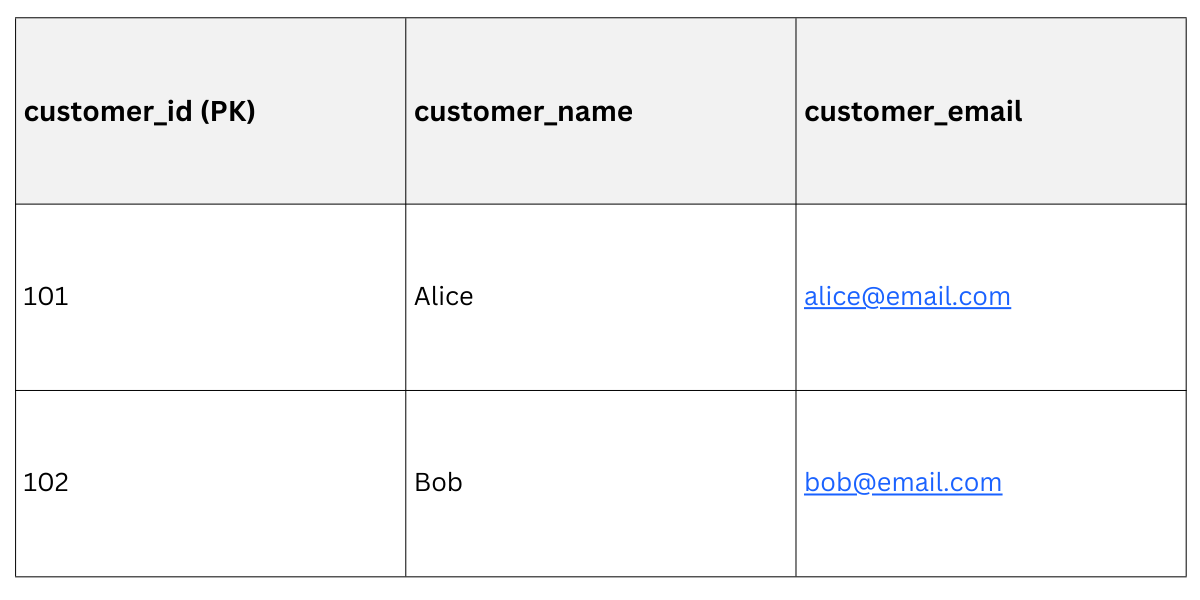
Post-2NF Schema
Customers Table
 Order Details Table (with Foreign key)
Order Details Table (with Foreign key)
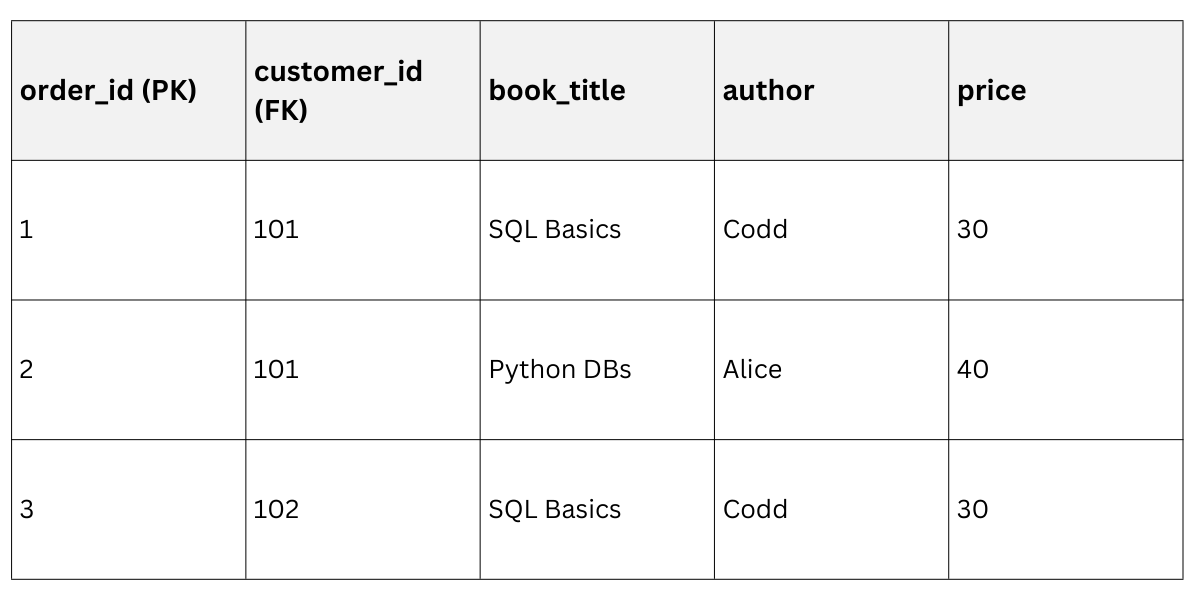 Improvement: Update Alice's email once; JOINs fetch full data efficiently in your FastAPI endpoints.
Improvement: Update Alice's email once; JOINs fetch full data efficiently in your FastAPI endpoints.
Third Normal Form (3NF): Eliminating Transitive Dependencies
3NF refines 2NF: no transitive dependencies, where a non-key attribute depends on another non-key (not directly on the primary key). Everything non-key must depend solely on the primary key.
This prevents chains like "customer → city → country," ensuring clean, independent entities.
Spot the issue in 2NF Order Details: author and price depend on book_title (not directly on order_id). Add a books table!
Steps to 3NF
1. Confirm 2NF compliance.
2. List dependencies: e.g., price → book_title → author.
3. Create intermediary tables for transitively dependent attributes.
Final 3NF Schema
Books Table
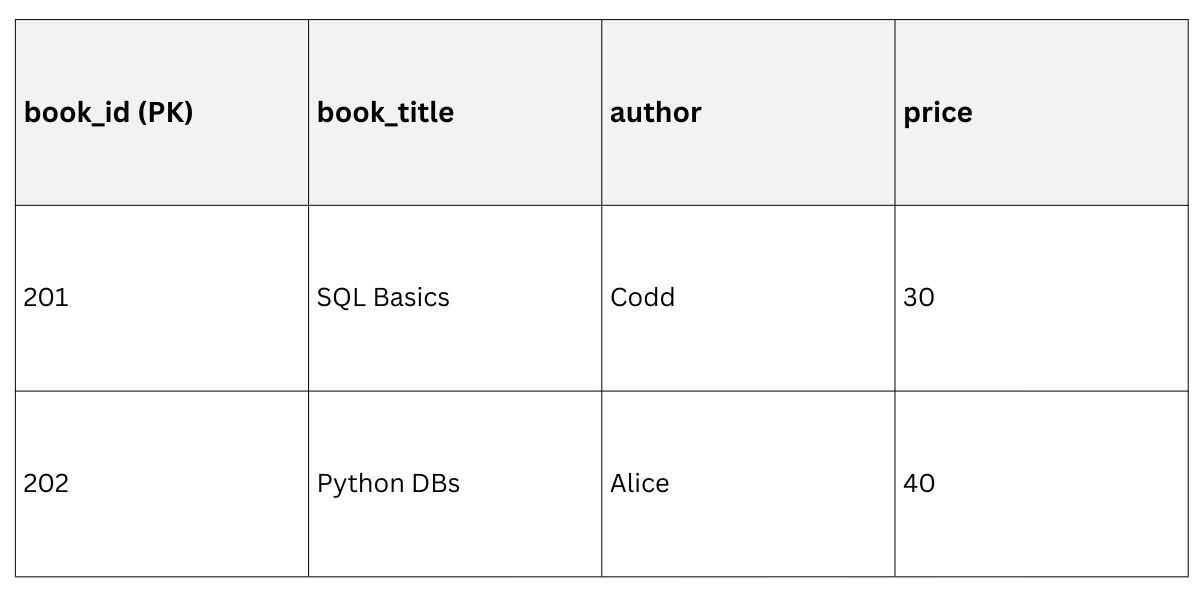 Order Details (Revised)
Order Details (Revised)
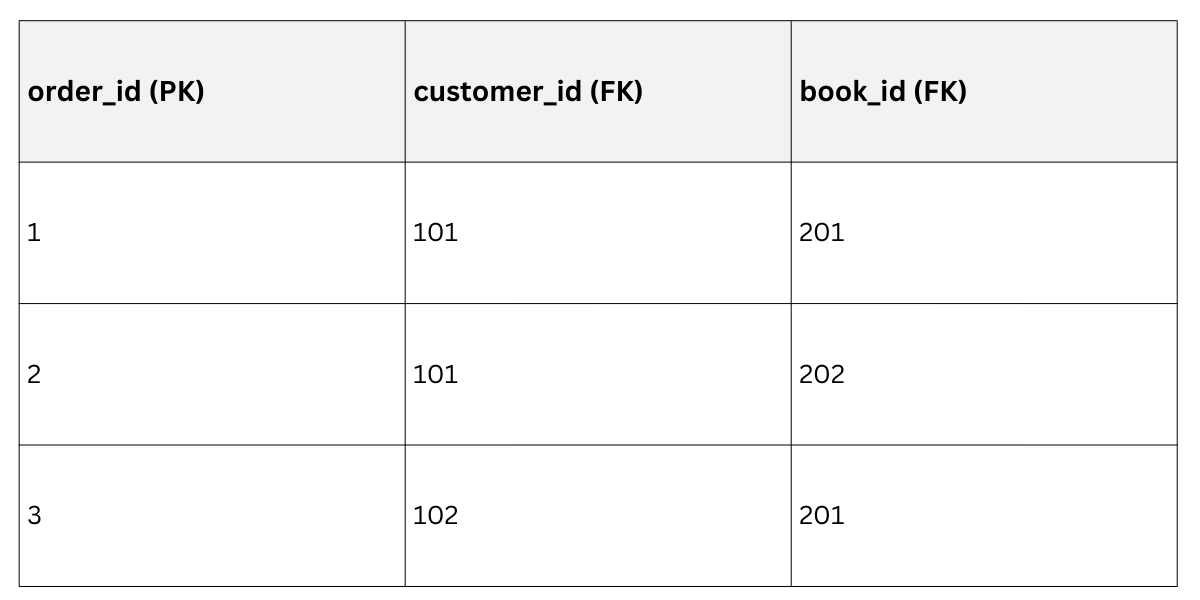 Backend Win: Queries like SELECT * FROM order_details JOIN books ON ... run blazingly fast, with zero redundancy.
Backend Win: Queries like SELECT * FROM order_details JOIN books ON ... run blazingly fast, with zero redundancy.
Normalization Comparison Table
 Practical Implementation in Backend Development
Practical Implementation in Backend Development
Applying normalization isn't theoretical—it's a daily tool for Python devs. Use ORMs like SQLAlchemy or Django's models to enforce it.
Best Practices
1. Start with: 3NF, then denormalize selectively for read-heavy apps (e.g., add customer_name cache in high-traffic views).
2. Validate with tools: Draw ER diagrams in dbdiagram.io; test anomalies with sample INSERT/UPDATE/DELETE.
3. Industry Standard: Follow ANSI SQL-92 rules; PostgreSQL's foreign keys auto-enforce referential integrity.
Real-World Example: E-commerce Backend
Imagine scaling a Flask app. Pre-normalization: fat orders table crashes on 10k rows. Post-3NF: JOINs handle millions, with indexes on FKs boosting speed 5x.
Django Model Snippet (for illustration)
class Customer(models.Model):
name = models.CharField(max_length=100)
email = models.EmailField(unique=True)
class Book(models.Model):
title = models.CharField(max_length=200)
author = models.CharField(max_length=100)
price = models.DecimalField(max_digits=10, decimal_places=2)
class OrderDetail(models.Model):
order_id = models.IntegerField()
customer = models.ForeignKey(Customer, on_delete=models.CASCADE)
book = models.ForeignKey(Book, on_delete=models.CASCADE)This schema prevents anomalies while supporting RESTful APIs seamlessly.
Common Pitfalls and Fixes
When to Denormalize
Pure normalization trades write speed for storage/read efficiency. In modern backends, denormalization adds redundant data strategically for NoSQL-like reads in SQL.
1. High-read scenarios: Cache total_order_value in orders table.
2. Tools: Redis for sessions; database triggers for auto-updates.
3. Rule: Normalize for writes, denormalize for reads—monitor with EXPLAIN ANALYZE.
