As backend systems grow, managing large volumes of data in a single database can lead to performance and scalability challenges.
Partitioning and sharding are techniques used to distribute data across smaller, more manageable pieces.
Partitioning divides a database table into segments based on criteria such as ranges, lists, or hashes, while sharding distributes data across multiple database instances or servers.
These approaches help improve query performance, balance load, and enable horizontal scaling.
They are especially important for high-traffic applications that handle massive datasets and require consistent performance.
What is Database Partitioning?
Partitioning divides a large table (or index) into smaller, manageable sub-tables called partitions, all within the same database instance.
This keeps data logically grouped while physically splitting it for efficiency—think of it as organizing a massive filing cabinet into labeled drawers.
It shines in read-heavy workloads or when dealing with time-series data, reducing I/O overhead without needing multiple servers.
Types of Partitioning
Databases offer several partitioning strategies, each suited to specific data patterns. Choose based on your query patterns and data growth.
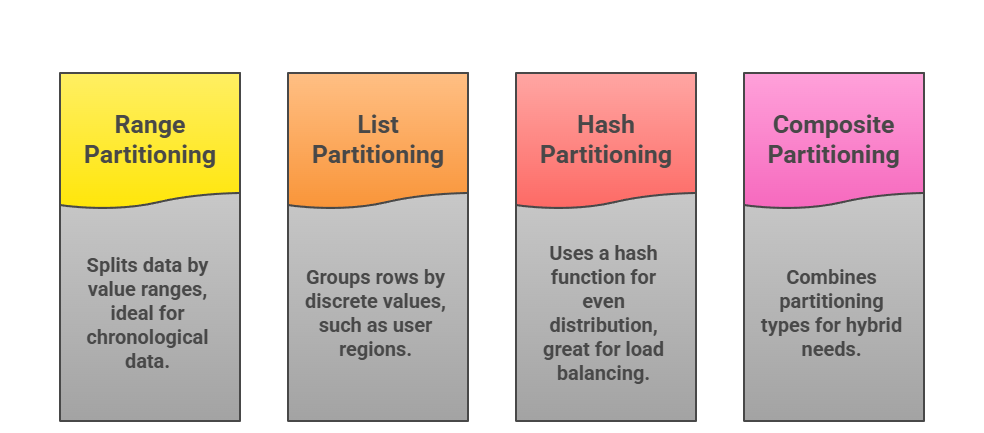
PostgreSQL 14+ supports declarative partitioning with auto-pruning, where queries skip irrelevant partitions automatically.
Benefits and When to Use It
Partitioning boosts performance by enabling partition elimination—the database skips scanning irrelevant partitions during queries.
1. Faster queries and maintenance (e.g., vacuuming one partition at a time).
2. Easier archiving (drop old partitions entirely).
3. Scalability within a single server before sharding.
Partitioning Implementation Steps
Here's a practical walkthrough for PostgreSQL, a go-to for backend devs:
1. Choose Partition Key: Select a column with good selectivity (e.g., created_at for orders).
2. Create Parent Table: CREATE TABLE orders (...) PARTITION BY RANGE (created_at);
3. Add Child Partitions: CREATE TABLE orders_2024 PARTITION OF orders FOR VALUES FROM ('2024-01-01') TO ('2025-01-01');
4. Load Data and Test: Insert rows and run EXPLAIN to verify pruning.
5. Automate with Triggers/Extensions: Use pg_partman for dynamic management.
Pro Tip: Always index partition keys sparingly to avoid overhead.
Understanding Sharding
Sharding takes partitioning further by distributing data across multiple database instances (shards), often on separate servers.
It's like partitioning across a cluster—each shard holds a subset of data, queried in parallel for massive scale.
This is crucial for horizontal scaling in distributed systems, powering giants like Instagram (sharded MySQL) or MongoDB Atlas clusters.
Horizontal vs. Vertical Scaling
Sharding enables horizontal scaling (add cheap servers) over vertical (bigger servers), aligning with cloud economics.
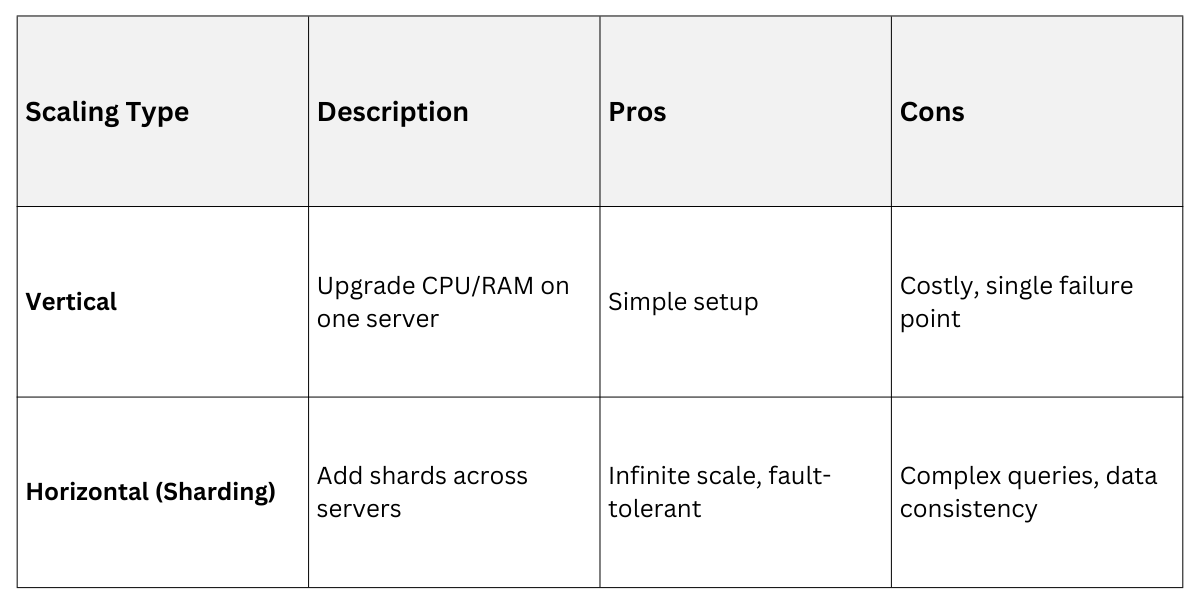
Vertical works for prototypes; sharding for production at 100TB+.
Sharding Strategies
Pick a shard key wisely—it's the glue holding your system together.
1. Range Sharding: Divide by ranges (e.g., user IDs 1-1M on Shard 1). Risks hotspots if uneven.
2. Hash Sharding: Hash the key for even spread (MongoDB default). Balances load perfectly.
3. Directory-Based: Central lookup service maps keys to shards (Cassandra style).
4. Geographic: Shard by location for low-latency (e.g., EU data in Frankfurt).
Best Practice: Composite keys (user_id + timestamp) prevent "hot shards" where one gets all writes.
Partitioning vs. Sharding: Key Differences
These techniques overlap but serve different scales—know when to layer them.
Partitioning is intra-server; sharding is inter-server. Many systems combine both: partition tables within shards.
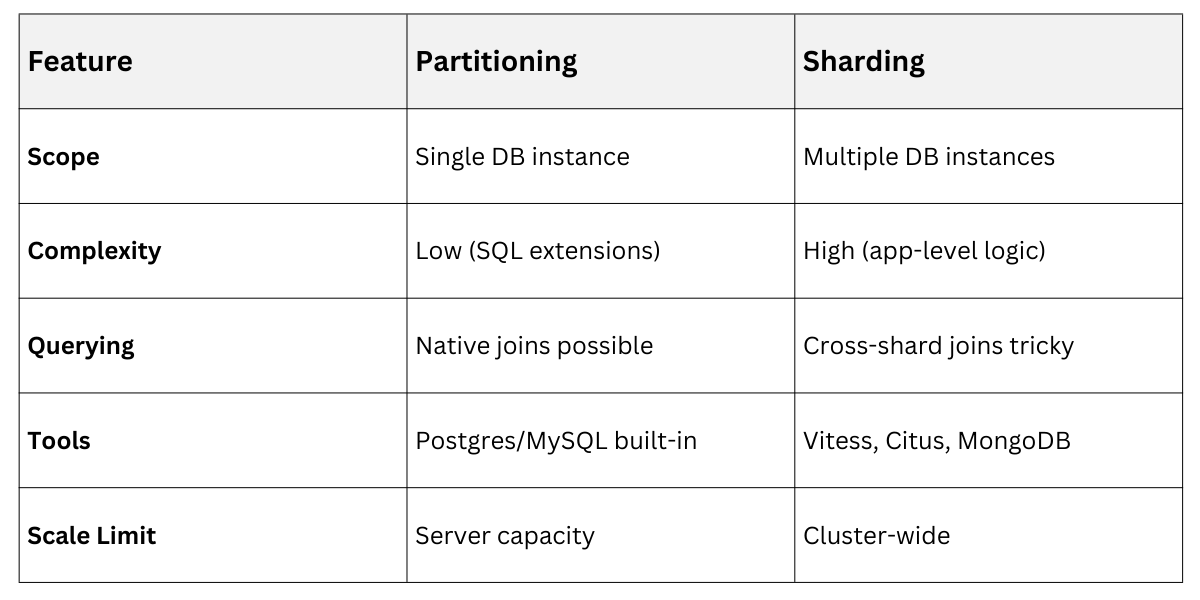
Example: E-commerce app partitions orders by date per shard (hashed by tenant_id).
Practical Implementation and Best Practices
Real-world sharding demands tools and foresight. Let's walk through a FastAPI backend with sharded Postgres via Citus.
Step-by-Step Sharding Setup
1. Design Shard Key: Analyze writes/queries—e.g., tenant_id for multi-tenant SaaS.
2. Choose Orchestrator: Use Citus (Postgres extension) or Vitess (MySQL).
3. Distribute Tables: SELECT create_distributed_table('orders', 'tenant_id');
4. Route Queries: App logic or proxy fans out to shards.
5. Handle Failures: Replicate shards (3x for HA) and use consistent hashing for resharding.
6. Monitor: Track shard balance with Prometheus/Grafana.
Common Pitfalls
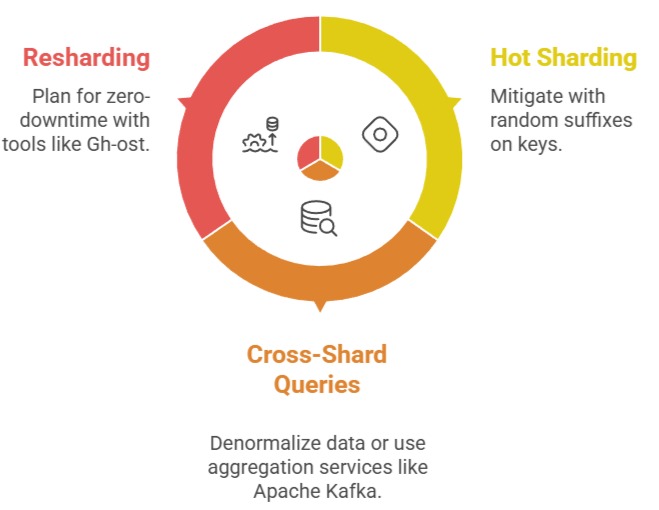
Industry standards (e.g., CockroachDB's auto-sharding) now simplify this, but understanding basics ensures you won't over-rely on managed services.
Case Study: Uber shards MySQL by city_id, handling 1M+ rides/day with sub-100ms latencies.
Challenges and Advanced Considerations
No silver bullet—sharding introduces trade-offs.
1. Consistency: Use eventual consistency (CAP theorem) or 2PC for strong guarantees.
2. Backups: Shard-level snapshots, not full dumps.
3. Latest Trends (2025): Serverless sharding in PlanetScale/Vitess 18+, AI-driven key selection in YugabyteDB.
Start Small: Prototype partitioning locally, then shard in staging.
